Command Palette
Search for a command to run...
EX-4D: EXtreme Viewpoint 4D Video Synthesis via Depth Watertight Mesh
EX-4D: EXtreme Viewpoint 4D Video Synthesis via Depth Watertight Mesh
Tao Hu Haoyang Peng Xiao Liu Yuewen Ma
Zusammenfassung
Die Generierung hochwertiger, kamerakontrollierbarer Videos aus monokularer Eingabe ist eine anspruchsvolle Aufgabe, insbesondere bei extremen Kameraposen. Bestehende Methoden leiden häufig an geometrischen Inkonsistenzen und Sichtbarkeitsartefakten an Grenzflächen, was die visuelle Qualität beeinträchtigt. In diesem Paper stellen wir EX-4D vor, einen neuartigen Ansatz, der diese Herausforderungen durch eine Tiefen-wasserdichte-Mesh-Darstellung überwindet. Diese Darstellung dient als robustes geometrisches Vorwissen, indem sie sowohl sichtbare als auch verdeckte Regionen explizit modelliert und somit eine geometrische Konsistenz auch bei extremen Kameraposen gewährleistet. Um den Mangel an gepaarten Multiview-Datensätzen zu umgehen, schlagen wir eine simuliertes Maskierungsverfahren vor, das effektive Trainingsdaten ausschließlich aus monokularen Videos generiert. Zudem wird ein leichtgewichtiger, auf LoRA basierender Video-Diffusions-Adapter eingesetzt, um hochwertige, physikalisch konsistente und zeitlich kohärente Videos zu synthetisieren. Umfangreiche Experimente zeigen, dass EX-4D state-of-the-art-Methoden hinsichtlich physikalischer Konsistenz und Qualität bei extremen Ansichten übertrifft und somit eine praktikable 4D-Video-Generierung ermöglicht.
One-sentence Summary
The authors, affiliated with Pico and Bytedance, propose EX-4D, a novel framework for generating high-quality, camera-controllable 4D videos from monocular input under extreme viewpoints. By introducing a Depth Watertight Mesh representation that models both visible and occluded regions, the method ensures geometric consistency and handles boundary occlusions effectively. Unlike prior work relying on paired multi-view data, it uses a simulated masking strategy for training from monocular videos alone, and integrates a lightweight LoRA-based video diffusion adapter to produce physically and temporally coherent results, significantly advancing practical 4D video synthesis.
Key Contributions
- We propose the Depth Watertight Mesh (DW-Mesh) representation, which explicitly models both visible and occluded regions to ensure geometric consistency and eliminate boundary artifacts in extreme camera viewpoints.
- We introduce a simulated masking strategy that generates training data from monocular videos by combining rendered visibility masks and temporally consistent tracking, eliminating the need for paired multi-view datasets.
- We integrate a lightweight LoRA-based video diffusion adapter with the DW-Mesh prior, achieving high-quality, physically consistent, and temporally coherent 4D video synthesis that outperforms state-of-the-art methods, especially under extreme viewing angles.
Introduction
The authors address the challenge of generating high-quality, camera-controllable 4D videos from monocular input, particularly under extreme viewpoints ranging from -90° to 90°. This capability is critical for immersive applications like free-viewpoint video and mixed reality, where physically consistent and temporally coherent novel views are essential. Prior methods either rely on camera-based guidance with limited geometric fidelity or geometry-based approaches that fail to model occluded regions, leading to boundary artifacts and inconsistent appearance in extreme views. The authors introduce EX-4D, a framework that leverages a Depth Watertight Mesh (DW-Mesh) representation to explicitly encode both visible and occluded geometry, ensuring robust geometric consistency across extreme camera poses. To overcome the lack of paired multi-view training data, they propose a simulated masking strategy using rendered and tracked visibility masks derived from the DW-Mesh, enabling effective training from monocular videos alone. A lightweight LoRA-based video diffusion adapter then integrates this geometric prior into a pre-trained diffusion model, producing high-fidelity, temporally coherent videos with minimal computational overhead. The approach achieves state-of-the-art performance in physical consistency and extreme-view quality, especially at challenging angles, as validated by quantitative metrics and user studies.
Dataset
- The authors use OpenVID [27] as the primary training dataset, a large-scale monocular video collection with over 1 million high-quality videos featuring diverse camera motions and dynamic scenes.
- For evaluation, they construct a test set of 150 in-the-wild web videos that capture real-world complexity, including varied dynamics and camera movements.
- The test set is evaluated across four increasingly challenging angular ranges: Small (0°→30°), Large (0°→60°), Extreme (0°→90°), and Full (-90°→90°), using identical camera trajectories for all methods to ensure fairness.
- Training leverages a simulated masking strategy that does not require multi-view data or camera calibration, enabling efficient use of monocular videos from OpenVID.
- The model is trained using a mixture of video sequences from OpenVID, with input videos resized to 512×512 resolution and truncated to 49 frames per sequence.
- A lightweight adapter based on LoRA (rank 16) is trained on top of the frozen Wan2.1 video diffusion backbone, with approximately 140M trainable parameters—just 1% of the full 14B model.
- Depth estimation for DW-Mesh construction is performed using a pre-trained DepthCrafter model [19], with a depth threshold set to 0.013 of the depth range and a maximum depth of 100 for boundary padding.
- Nvdiffrast [23] is used as the renderer during both training and validation.
- The adapter is optimized with AdamW at a learning rate of 3×10⁻⁵, trained on 32 NVIDIA A100 GPUs (80GB), completing training in one day.
- Inference generates each video in about 4 minutes using 25 denoising steps.
- Evaluation metrics include FID and FVD for visual and temporal quality, VBench for perceptual quality across the Full angular range, and a user study to assess human perception.
- All methods are evaluated under identical conditions, including shared camera trajectories and depth inputs for geometry-based baselines, ensuring a fair comparison.
Method
The EX-4D framework synthesizes high-quality 4D videos from monocular input by integrating a geometric prior with a video diffusion model. The overall architecture, as illustrated in the framework diagram, consists of three primary components: the construction of a Depth Watertight Mesh (DW-Mesh) to model scene geometry, the generation of training masks to simulate novel-view occlusions, and a lightweight LoRA-based adapter that conditions the video diffusion process. This modular design enables the synthesis of temporally coherent and geometrically consistent videos under extreme camera viewpoints without requiring multi-view training data.
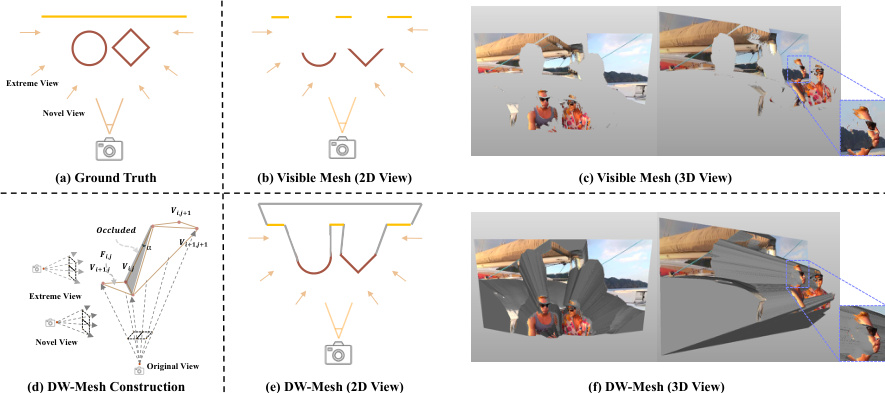
The first component is the Depth Watertight Mesh (DW-Mesh), which addresses the challenge of handling occlusions in extreme viewpoints. As shown in the figure below, the DW-Mesh explicitly models both visible and hidden regions of the scene, ensuring a closed and watertight surface representation. For each input frame, a per-frame depth map is computed using a pre-trained depth estimation model, and each pixel's depth value is unprojected into 3D space to form a vertex. To ensure the mesh remains a closed surface under arbitrary viewpoints, a boundary padding strategy is applied by assigning a maximum depth value to all frame-border pixels. Triangular faces are constructed from adjacent vertices, and two additional faces are added to the mesh boundary to guarantee watertightness. An occlusion attribute is then assigned to each face based on geometric validation, where faces with a minimum angle below a threshold or exhibiting large depth discontinuities are marked as occluded. The texture value for each face is set to the corresponding pixel color if the face is visible, or to black if it is occluded. This process produces a comprehensive geometric representation that captures both visible and hidden surfaces, providing a robust prior for rendering from novel viewpoints.
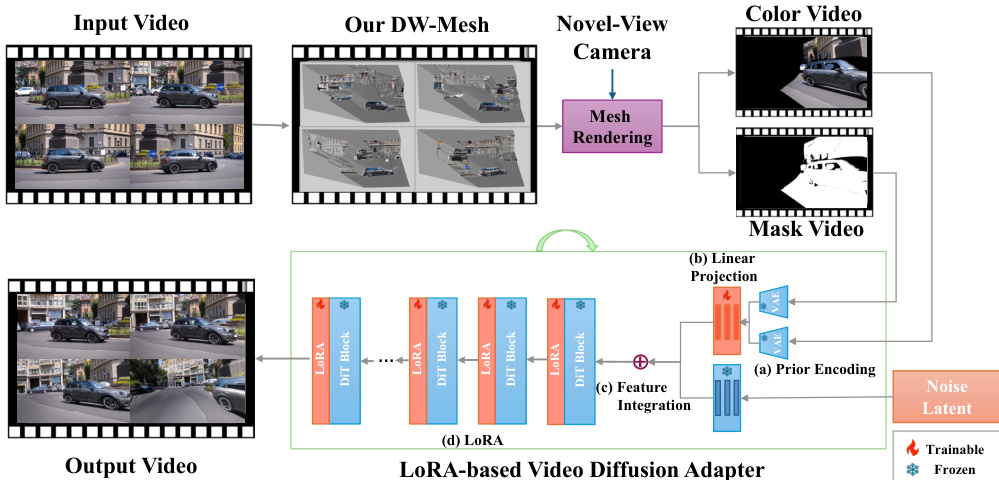
The DW-Mesh is rendered using rasterization under the target camera trajectory to generate a color video and a binary mask video. These outputs serve as geometric priors, conditioning the video diffusion model to synthesize novel-view frames with improved visual consistency and geometric accuracy. The second component, mask generation, is designed to create effective training pairs from monocular videos. This involves two strategies: Rendering Mask Generation and Tracking Mask Generation. Rendering Mask Generation leverages the DW-Mesh to simulate occlusions that would occur in novel viewpoints by rendering the mesh under a full rotation camera trajectory and applying morphological dilation to suppress noise. Tracking Mask Generation ensures temporal consistency by tracking points across frames and marking their surrounding regions as occluded, which physically aligns with the actual visibility transitions observed in novel-view video generation.
The final component is a lightweight LoRA-based video diffusion adapter that integrates the geometric priors into the video synthesis pipeline. The adapter consists of four main modules: Prior Encoding, Linear Projection, Feature Integration, and LoRA. The Prior Encoding module uses a frozen Video VAE encoder to extract compact latent representations from both the input color video and the corresponding mask video. These latent features are then concatenated and processed through a sequence of 1×1×1 Conv3d layers followed by a final Conv3d layer with kernel size (1,2,2) and stride (1,2,2) to produce patch embeddings that match the expected input shape of the diffusion model. The projected geometric priors are fused with the noise latent features used in the diffusion process through element-wise addition, allowing the model to condition the generation process on both appearance and occlusion information. To enable efficient training, Low-Rank Adaptation (LoRA) is employed, which introduces low-rank updates to specific linear projection weights within the video diffusion backbone, such as the attention projections and feed-forward blocks. This approach allows the pre-trained video diffusion model to remain frozen while only updating a small subset of parameters, resulting in a lightweight and scalable adapter. The training objective adheres to the original diffusion model's denoising objective, ensuring rapid convergence and stable performance.
Experiment
- EX-4D consistently outperforms baselines on quantitative metrics across varying viewpoint ranges: achieves FID scores of 44.19, 50.30, and 55.42 (small, large, extreme), surpassing TrajectoryCrafter and TrajectoryAttention; attains lowest FVD scores (571.18, 685.39, 823.61), indicating superior temporal coherence, with performance gap widening under extreme viewpoints.
- On VBench metrics, EX-4D achieves top scores in aesthetic quality (0.450), imaging quality (0.631), temporal consistency (0.914), subject consistency (0.846), and background consistency (0.872), demonstrating geometric stability via DW-Mesh; slightly trails ReCamMaster in motion smoothness (0.934 vs. 0.938) but leads in overall dynamic performance (0.948).
- User study with 50 participants shows EX-4D is preferred in 70.70% of selections over baselines (TrajectoryCrafter: 14.96%, ReCamMaster: 9.50%, TrajectoryAttention: 4.84%), confirming superior physical consistency and extreme viewpoint quality, with reduced artifacts like warping and flickering.
- Ablation study confirms DW-Mesh is critical: removing it increases FID by 34.1% and FVD by 33.9%; structured masks outperform random ones; both rendering and tracking masks are essential; LoRA-based adapter is efficient and effective, with minimal gains from increasing rank; ControlNet causes out-of-memory errors.
- Failure cases reveal limitations in depth estimation accuracy and fine structure preservation, leading to geometric distortions and loss of thin details, suggesting future improvements via multi-frame depth consistency, uncertainty-aware mesh construction, or neural refinement.
The authors use a quantitative comparison to evaluate their EX-4D method against state-of-the-art baselines, showing that EX-4D achieves the highest scores across most VBench metrics, including aesthetic quality, imaging quality, and dynamic degree. Results show that EX-4D outperforms all baselines in subject and background consistency, demonstrating superior geometric stability and temporal coherence, particularly under extreme viewpoint conditions.

The authors use an ablation study to evaluate the impact of each component in their EX-4D framework, showing that removing the DW-Mesh leads to the largest performance drop, with FID increasing by 34.1% and FVD worsening by 33.9%. Results also indicate that both rendering and tracking masks are essential, and increasing the LoRA rank provides only marginal improvements, highlighting the efficiency of their lightweight adapter.
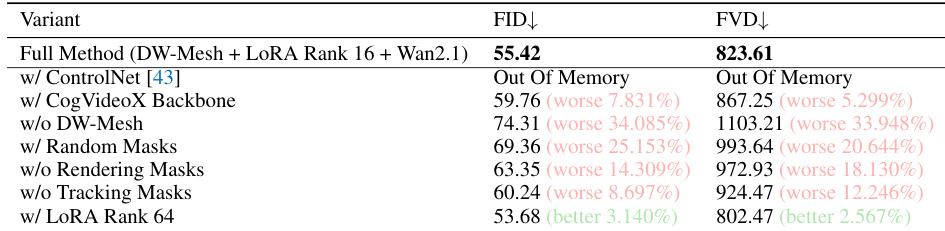
The authors use the table to compare EX-4D against baselines on FID and FVD metrics across different viewpoint ranges. Results show that EX-4D achieves the lowest FID and FVD scores in all categories, with the largest performance gap appearing at extreme viewpoints, indicating superior quality and robustness.
