Command Palette
Search for a command to run...
EmergentTTS-Eval: Bewertung von TTS-Modellen hinsichtlich komplexer Prosodie-, Ausdruckskraft- und sprachlicher Herausforderungen unter Verwendung von Modell-als-ein-Richter
EmergentTTS-Eval: Bewertung von TTS-Modellen hinsichtlich komplexer Prosodie-, Ausdruckskraft- und sprachlicher Herausforderungen unter Verwendung von Modell-als-ein-Richter
Manku Ruskin Raj Tang Yuzhi Shi Xingjian Li Mu Smola Alex
Zusammenfassung
Text-to-Speech-(TTS)-Benchmarks erfassen oft nicht ausreichend, wie gut Modelle feinabgestimmte und semantisch komplexe Texte verarbeiten. Aufbauend auf extitEmergentTTS stellen wir extitEmergentTTS−Eval vor, einen umfassenden Benchmark, der sechs anspruchsvolle TTS-Szenarien abdeckt: Emotionen, Paralinguistik, Fremdwörter, syntaktische Komplexität, komplexe Aussprache (z. B. URLs, Formeln) sowie Fragen. Entscheidend ist, dass unser Framework sowohl die Generierung von Testfällen als auch die Evaluation automatisiert, wodurch der Benchmark leicht erweiterbar ist. Aus einer kleinen Menge menschlich verfasster Ausgangs-Prompts erweitern wir diese iterativ mithilfe von großen Sprachmodellen (LLMs), um gezielt strukturelle, phonetische und prosodische Herausforderungen abzubilden, was zu insgesamt 1.645 vielfältigen Testfällen führt. Zudem setzen wir einen „Model-as-a-Judge“-Ansatz ein, bei dem ein großes Audio-Sprachmodell (LALM) die gesprochene Ausgabe anhand mehrerer Dimensionen bewertet, darunter ausgedrückte Emotion, Prosodie, Intonation und Aussprachegenauigkeit. Wir evaluieren aktuelle, offene und proprietäre TTS-Systeme wie 11Labs, Deepgram und OpenAI’s 4o-mini-TTS auf EmergentTTS-Eval und zeigen damit, dass der Benchmark feinabgestufte Leistungsunterschiede aufdecken kann. Die Ergebnisse belegen, dass der Model-as-a-Judge-Ansatz eine robuste TTS-Bewertung ermöglicht und eine hohe Korrelation mit menschlichen Präferenzen aufweist. Wir stellen den Evaluationscode hrefhttps://github.com/boson−ai/EmergentTTS−Eval−publichier und die Datensammlung hrefhttps://huggingface.co/datasets/bosonai/EmergentTTS−Evalhier öffentlich zur Verfügung.
One-sentence Summary
The authors from Boson AI propose EmergentTTS-Eval, a scalable, LLM-automated benchmark for evaluating TTS systems across six nuanced scenarios, leveraging a model-as-a-judge framework with a Large Audio Language Model to assess prosody, emotion, and pronunciation with high alignment to human preferences, enabling fine-grained comparison of systems like 11Labs and OpenAI's 4o-mini-TTS.
Key Contributions
-
EmergentTTS-Eval introduces a comprehensive benchmark with 1,645 test cases across six challenging TTS scenarios—emotions, paralinguistics, foreign words, syntactic complexity, complex pronunciation (e.g., URLs, formulas), and questions—addressing the limitations of existing benchmarks in covering nuanced, real-world linguistic phenomena.
-
The framework automates test-case generation through an iterative LLM-based refinement process that starts from seed prompts and systematically produces increasingly complex utterances, enabling scalable and controllable evaluation of emergent TTS capabilities.
-
It pioneers the use of Large Audio Language Models (LALMs) as model-as-a-judge to assess speech quality across subjective dimensions like prosody, emotion, and pronunciation accuracy, achieving high correlation with human preferences and offering a reproducible, scalable alternative to costly human evaluations.
Introduction
The authors address the growing gap between the complexity of real-world Text-to-Speech (TTS) applications and the limitations of existing evaluation methods. Modern TTS systems are deployed in diverse, high-stakes contexts—such as audiobooks, navigation, and accessibility tools—where they must handle emotionally expressive speech, syntactically complex sentences, code-switching, foreign words, and paralinguistic cues. However, prior evaluation frameworks rely heavily on small, narrow human judgments or simple metrics like WER and SIM, which fail to capture nuanced prosody, expressiveness, and linguistic diversity. These approaches are costly, non-reproducible, and ill-equipped for multilingual or emotionally rich content.
To overcome these challenges, the authors introduce EmergentTTS-Eval, a scalable, automated benchmark that evaluates TTS systems across six critical dimensions: Emotions, Paralinguistics, Syntactic Complexity, Questions, Foreign Words, and Complex Pronunciation. They leverage Large Audio Language Models (LALMs) as model-as-a-judge to provide consistent, reproducible, and human-correlated assessments of subjective qualities like prosody and expressiveness. By using LLM-driven iterative refinement, they generate increasingly complex utterances that stress-test TTS systems at scale. Their approach enables fine-grained, systematic failure analysis and reveals significant performance gaps between open-source and closed-source models, particularly in handling emergent linguistic phenomena.
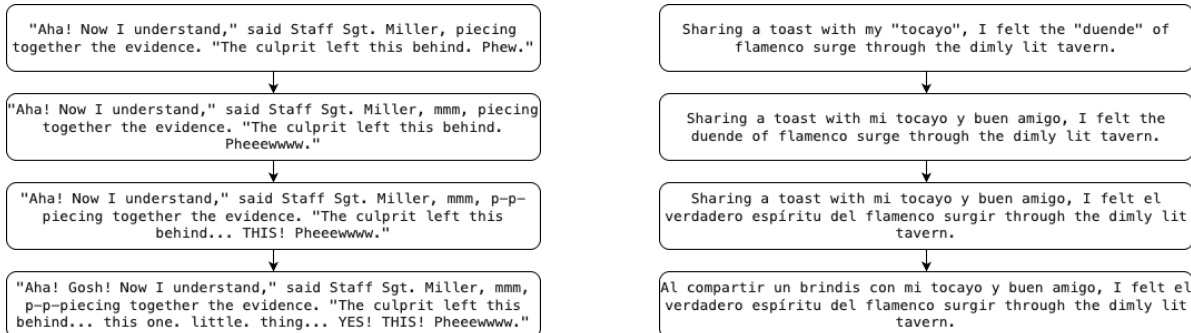
Dataset
-
The EmergentTTS-Eval benchmark comprises six challenging TTS categories: Questions, Emotions, Paralinguistics, Foreign Words, Syntactic Complexity, and Complex Pronunciation. It is built upon 140 human-curated seed prompts from BASE-TTS, with five categories retained and two new ones introduced—Emotions and Complex Pronunciation—while "Compound Nouns" and "Punctuation" were excluded due to limited scope or redundancy.
-
For each of the five BASE-TTS-derived categories, the authors start with 70 seed utterances (20 human-curated + 50 LLM-expanded for breadth), then apply three iterative depth-refinement steps using LLMs to generate increasingly complex variants, resulting in 280 samples per category. The "Complex Pronunciation" category is built from scratch with 60 breadth-expanded samples, also refined through three steps to yield 240 samples. Additionally, five short tongue-twisters are repeated multiple times to test repeated articulation.
-
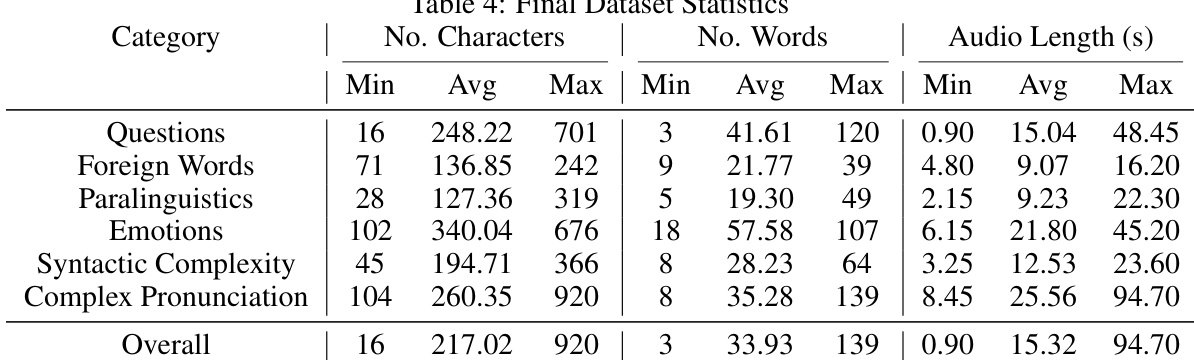
The final dataset contains 1,645 samples: 280 each for Questions, Emotions, Paralinguistics, Foreign Words, and Syntactic Complexity (1,400 total), plus 240 for Complex Pronunciation and 5 for tongue-twisters. The authors use this dataset to train and evaluate TTS models, with training splits constructed by mixing samples across categories at varying ratios to simulate real-world diversity and complexity.
-
Processing includes LLM-driven breadth expansion and depth refinement, where each refinement step systematically increases complexity—e.g., adding code-switching in Foreign Words, layered paralinguistic cues in Paralinguistics, or emotional arcs in Emotions. For Foreign Words, outputs are post-processed via Gemini-2.5-Pro to fix grammar and syntax. All text remains in standard Latin characters to test emergent pronunciation capabilities without relying on multilingual character support. No meta-textual formatting (e.g., italics, parentheses) is used, ensuring cues are embedded directly in the text for realistic TTS rendering.
Method
The authors leverage a multi-stage framework to enhance the complexity and realism of text-to-speech (TTS) evaluation datasets, focusing on both breadth expansion and depth refinement. The overall architecture consists of two primary phases: breadth expansion and depth refinement, each employing distinct large language models (LLMs) and carefully designed prompting strategies to generate challenging text inputs for TTS systems.
For breadth expansion, the framework utilizes long-thinking LLMs such as Gemini 2.5 Pro, GPT-o3, and Claude 3.7 Sonnet. These models are prompted with a standardized breadth expansion prompt, and the best-performing model for each category is selected through manual analysis. This ensures that the expanded text corpus captures a wide range of linguistic and contextual variations relevant to TTS evaluation. The selected model's output forms the basis for subsequent depth refinement.
Depth refinement is exclusively performed using Gemini-2.5-Pro, which is tasked with transforming the original text into a more complex and challenging version. The process follows a structured template that includes the original text (text_to_synthesize) and a category-specific refinement method (complex_prompt_method). The LLM is instructed to rewrite the text to increase its difficulty for TTS systems while preserving the original emotional and narrative intent. A key component of the refinement prompt is the tts_synthesis_diversity field, which requires the LLM to provide a detailed rationale for how the complexity is introduced, ensuring that the resulting text incorporates diverse and challenging linguistic features.
The refinement process is guided by a set of strict constraints and guidelines that ensure the output maintains high evaluative clarity and natural spoken style. These include requirements for clear emotional identification, natural textual cues, and adherence to structural rules. The framework also enforces the preservation of the original emotion and tone, with specific instructions for modifying quoted dialogue and narrative text to deepen emotional expressiveness. For Method B, the system evaluates four possible emotional arcs and eliminates invalid orders that result in consecutive quoted dialogues, selecting the most appropriate one based on a comprehensive analysis.
To support the generation of high-quality audio outputs, the framework employs category-specific descriptions for strong prompting with audio-capable LLMs such as Hume AI and gpt-4o-mini-tts. These descriptions cover various linguistic dimensions, including emotional expressiveness, paralinguistic cues, syntactic complexity, foreign words, questions, and complex pronunciation. The descriptions are used to guide the TTS systems in producing realistic and contextually appropriate speech.
The evaluation of TTS performance is conducted through detailed reasoning guidelines tailored to each linguistic category. For emotional expressiveness, the analysis focuses on the clarity and distinctness of emotional transitions between quoted dialogues and narrative text. For paralinguistics, the evaluation examines the naturalness of interjections, onomatopoeia, and prosodic features such as stuttering and pacing. Syntactic complexity is assessed by analyzing the prosody used to clarify complex sentence structures and handle homographs. Pronunciation is evaluated by identifying critical parts of the text that require precise articulation and providing precise timestamps for their correct synthesis.
Finally, the framework includes a text normalization module that converts raw text into a spoken form suitable for TTS processing. This module, implemented using GPT-4.1-mini, handles a wide range of content types, including numbers, symbols, abbreviations, and specialized formats such as URLs and email addresses. The normalization process ensures that all text elements are rendered in a natural and comprehensible manner, maintaining the flow and clarity of the spoken output.
Experiment
- Introduced EmergentTTS-Eval, a benchmark with 1,645 test cases across six challenging TTS scenarios: emotions, paralinguistics, foreign words, syntactic complexity, complex pronunciation, and questions, generated via LLM-based iterative refinement.
- Validated a model-as-a-judge approach using Gemini 2.5 Pro, a Large Audio Language Model (LALM), to assess speech across prosody, emotion, intonation, and pronunciation, achieving high correlation with human preferences (Spearman correlation > 0.90).
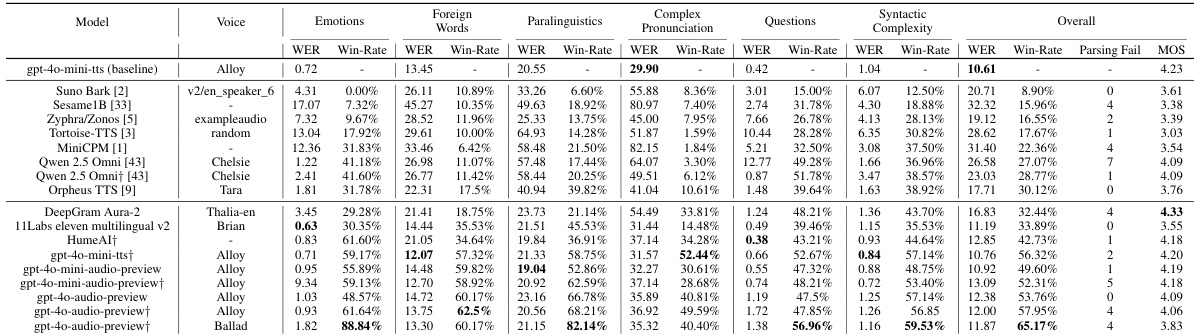
- Evaluated 11 TTS systems (7 open-source, 4 proprietary), with GPT-4o-mini-tts (Alloy voice) achieving the highest win-rate (65.17%) overall, and GPT-4o-Audio (Ballad voice) excelling in emotions (88.84%) and paralinguistics (82.14%).
- Demonstrated that strong prompting significantly improves performance, with GPT-4o-mini-tts increasing win-rate from 50% to 56%.
- Showed that open-source models generally underperform on complex pronunciation and emotions, while commercial models like HumeAI and ElevenLabs show voice-dependent variability, with Emotions and Paralinguistics being most sensitive to voice identity.
- Found that text normalization using LLMs improves complex pronunciation performance, while basic normalization techniques can degrade results due to inappropriate lexical substitutions.
- Confirmed high inter-judge agreement (Kendall’s W = 0.97) across LALMs, validating the robustness of the automated evaluation framework.
- Revealed systematic failure modes: open-source models struggle with pronunciation accuracy and prosodic transitions; commercial models exhibit subtle mispronunciations and synthesis breakdowns under high complexity.
The authors use a comprehensive benchmark to evaluate text-to-speech systems across six challenging scenarios, including emotions, paralinguistics, foreign words, syntactic complexity, complex pronunciation, and questions. The benchmark automates test-case generation and evaluation using a large audio language model as a judge, enabling scalable and reproducible assessment. Results show that the model-as-a-judge approach achieves high correlation with human preferences and reveals fine-grained performance differences among state-of-the-art TTS systems.
The authors evaluate the impact of text normalization (TN) techniques on TTS performance in the Complex Pronunciation category, using GPT-4o-mini-tts as the baseline. Results show that using an LLM-based TN method (GPT-4.1-mini) significantly improves the win-rate to 76.74%, outperforming both no normalization (51.69%) and a standard TN method (WeText TN, 50.06%).

The authors use a model-as-a-judge approach with Gemini 2.5 Pro to evaluate TTS systems across six challenging categories, including emotions, paralinguistics, and complex pronunciation. Results show that GPT-4o-Audio (Ballad voice) achieves the highest overall win-rate, with particularly strong performance in expressive categories, while open-source models generally underperform, especially in complex pronunciation.
The authors use a Large-Audio-Language Model (LALM) as a judge to evaluate TTS systems, with Gemini 2.5 Pro achieving the highest score of 68.60 on the Test-mini benchmark. This indicates that Gemini 2.5 Pro outperforms other LALMs in assessing speech synthesis quality, demonstrating its effectiveness as an automated evaluation tool.

The authors use a model-as-a-judge approach with Large Audio Language Models to evaluate Text-to-Speech systems across six challenging scenarios. Results show that the model judges achieve high correlation with human preferences, with Spearman coefficients above 90% for most judges, and a strong inter-judge agreement of Kendall's W = 0.97, validating the robustness of the evaluation framework.
