Command Palette
Search for a command to run...
In-Context Edit: Ermöglichen von Anweisungs-basierten Bildbearbeitungen mittels In-Context-Generierung in großen Diffusions-Transformer-Modellen
In-Context Edit: Ermöglichen von Anweisungs-basierten Bildbearbeitungen mittels In-Context-Generierung in großen Diffusions-Transformer-Modellen
Zechuan Zhang Ji Xie Yu Lu Zongxin Yang Yi Yang
Zusammenfassung
Anweisungsbasierte Bildbearbeitung ermöglicht präzise Modifikationen über natürlichsprachliche Prompts, doch bestehende Methoden leiden unter einem Kompromiss zwischen Genauigkeit und Effizienz: Fine-Tuning erfordert riesige Datensätze (über 10 Mio.) und erhebliche Rechenressourcen, während trainingsfreie Ansätze unter einer schwachen Auffassungsfähigkeit von Anweisungen leiden. Wir begegnen diesem Problem mit dem Vorschlag von ICEdit, das die inhärente Verständnis- und Generationsfähigkeit großer Diffusion-Transformers (DiTs) durch drei zentrale Innovationen nutzt: (1) Ein kontextbasiertes Bearbeitungsschema ohne Architekturmodifikationen; (2) Minimale parameter-effizientes Fine-Tuning zur Verbesserung der Qualität; (3) Frühe Filter-Inferenzzeit-Skalierung, die visuell-sprachliche Modelle (VLMs) nutzt, um hochwertige Rauschproben zur Effizienzsteigerung auszuwählen. Experimente zeigen, dass ICEdit eine state-of-the-art-Bearbeitungsleistung erreicht, wobei lediglich 0,1 % des Trainingsdatensatzes und 1 % der trainierbaren Parameter gegenüber früheren Methoden benötigt werden. Unser Ansatz etabliert eine neue Paradigma zur Balance zwischen Präzision und Effizienz in der anweisungsbasierten Bildbearbeitung. Der Quellcode und Demonstrationen sind unter https://river-zhang.github.io/ICEdit-gh-pages/ verfügbar.
One-sentence Summary
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, and Yi Yang from ReLER, CCAI, Zhejiang University and DBMI, HMS, Harvard University propose ICEdit, a novel instruction-based image editing method that achieves state-of-the-art performance with only 0.1% training data and 1% trainable parameters by leveraging in-context editing, minimal parameter-efficient fine-tuning, and early filter inference-time scaling via VLMs, enabling high-precision, efficient editing without architectural changes.
Key Contributions
- ICEdit introduces an in-context editing paradigm that leverages the intrinsic language and generation capabilities of large-scale Diffusion Transformers (DiTs) without architectural changes, enabling precise instruction following by reformulating editing commands into descriptive prompts the model naturally understands.
- The method achieves state-of-the-art editing performance with only 0.1% of the training data and 1% of the trainable parameters required by prior approaches, using minimal parameter-efficient fine-tuning to enhance instruction comprehension and layout preservation.
- By integrating Early Filter Inference-Time Scaling with vision-language models, ICEdit efficiently filters low-quality noise samples during early denoising stages, improving output fidelity and robustness while maintaining high inference efficiency on benchmarks like Emu Edit and MagicBrush.
Introduction
Instruction-based image editing enables precise image manipulation via natural language, but existing methods face a fundamental trade-off: fine-tuning-based approaches achieve high precision at the cost of massive data and computational demands, while training-free methods are efficient yet struggle with complex instructions and layout preservation. Prior work has largely relied on architectural modifications or large-scale datasets, limiting scalability and generalization. The authors propose ICEdit, a novel framework that leverages the intrinsic capabilities of large-scale Diffusion Transformers (DiTs) without architectural changes. By introducing an in-context editing paradigm that reformulates direct instructions into descriptive prompts, applying minimal parameter-efficient fine-tuning, and employing Early Filter Inference-Time Scaling with vision-language models to select high-quality noise samples, ICEdit achieves state-of-the-art performance using only 0.1% of the training data and 1% of the trainable parameters compared to prior methods. This approach establishes a new balance between precision and efficiency, enabling robust, scalable instruction-based editing while preserving image structure and reducing resource overhead.
Dataset
- The dataset consists of 50K samples sourced entirely from open-access repositories: 9K from MagicBrush [2] and 40K randomly selected samples from OmniEdit [34].
- Task type distribution is detailed in Table 4, though the dataset was not rigorously curated—fig. 11 reveals the presence of problematic samples, which were retained due to the high time cost of manual cleaning.
- Despite using only 50K samples—far fewer than the 1.2M used by prior SOTA models—the authors' model outperforms those trained on MagicBrush alone and the full OmniEdit dataset, highlighting the effectiveness of their in-context edit approach.
- The training split uses all 50K samples with a mixture ratio derived from the original dataset composition, without additional filtering or balancing.
- No cropping strategy was applied; images are used at their original resolution. Metadata construction follows the original formats from MagicBrush and OmniEdit, with minimal processing to preserve task-specific structure.
Method
The authors leverage the inherent contextual understanding of large-scale Diffusion Transformers (DiTs) to develop an in-context image editing framework, termed ICEdit, which enables instruction-based editing without requiring extensive training or architectural modifications. The core approach is built upon a diptych structure, where a reference image and an edit instruction are jointly processed to generate an edited output. Two training-free frameworks are initially explored: one based on text-to-image (T2I) DiT and another on inpainting DiT. The T2I DiT framework employs image inversion to preserve attention values from the reference image, which are then injected into the left side of a diptych during generation, while the right side is conditioned on the edit instruction. In contrast, the inpainting DiT framework constructs a side-by-side image where the left panel is reconstructed as the reference, and the right panel is generated based on a fixed mask and the edit prompt. As shown in the figure below, the inpainting-based approach is favored for further development due to its simplicity and lack of requirement for image inversion.

To enhance the model's ability to interpret editing instructions, the authors propose an in-context edit prompt (IC prompt) that embeds the instruction within a descriptive structure: "A diptych with two side-by-side images of the same scene. On the right, the scene is identical to the left but {instruction}." This prompt significantly improves the model's performance compared to direct instruction input, as it provides a clearer contextual framework for the DiT to understand the editing task. The authors further refine this approach through fine-tuning to address the limitations of the training-free frameworks, particularly in preserving unedited regions and handling diverse editing tasks.
The fine-tuning strategy is based on the inpainting DiT framework, which is defined as a function E mapping a source image Is and an edit instruction Te to the edited output It. This function is implemented using the inpainting DiT model D, which processes an in-context image IIC (containing Is on the left), a fixed binary mask M to reconstruct the source, and an in-context edit prompt TIC. To improve performance, the authors curate a compact dataset and apply LoRA fine-tuning to the multi-modal DiT blocks. However, a single LoRA structure struggles with diverse editing tasks. To overcome this, they propose a Mixture-of-Experts (MoE) inspired LoRA structure within the DiT block, as illustrated in the figure below. This structure integrates N parallel LoRA experts into the output projection layer of the multi-modal attention block, with a routing classifier selecting experts based on visual tokens and text embeddings. The output is a weighted sum of the base layer and the contributions from the selected experts, enabling the model to adapt to different editing requirements.
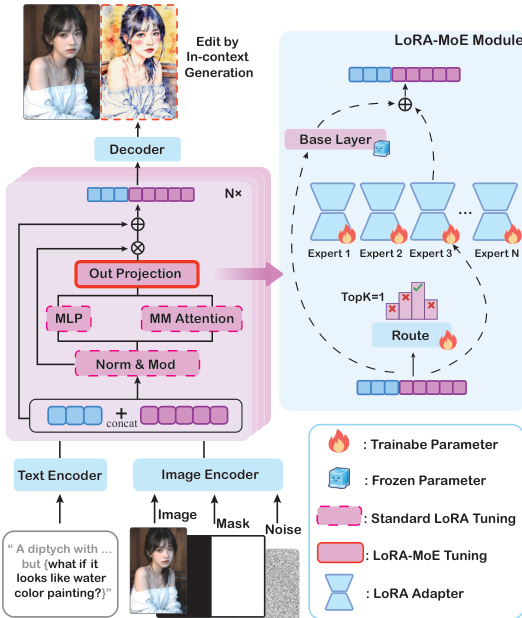
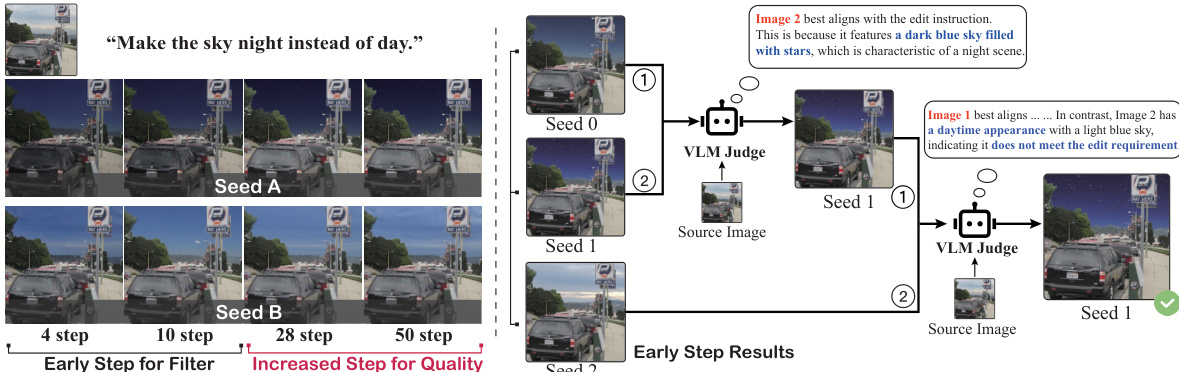
The MoE module is implemented with 4 expert LoRAs, each of rank 32, and a routing network using a single linear layer with TopK set to 1. The model is trained with a batch size of 1 and gradient accumulation over 2 steps, using the Prodigy optimizer. During inference, the model is run on an A100 GPU. The authors also introduce an early filter inference-time scaling strategy to optimize initialization noise. This strategy uses a Vision-Language Model (VLM) judge to assess the quality of early denoising steps from multiple seeds, selecting the optimal initial noise for high-quality generation. The process is illustrated in the figure below, where the VLM judge evaluates the alignment of intermediate results with the edit instruction, filtering out poor-quality outputs to improve the final edit outcome.
Experiment
- Early Filter Inference Time Scaling: Evaluates multiple initial noise candidates with few denoising steps (m ≪ n), uses Qwen-VL-72B for VLM-based pairwise comparison to select the best seed, then refines with full steps (n). Achieves 19% higher SC score and 16% higher overall VIE-Score, with reduced computational cost (NFE).
- Model Structure Ablation: LoRA-MoE with in-context prompting outperforms standard LoRA and direct instructions, increasing GPT score by 13% and 70% respectively; full module fine-tuning is essential for optimal performance.
- Data Efficiency: Achieves 180% GPT-score improvement over training-free baseline using only 0.05M training samples (0.1% of prior models), demonstrating high data efficiency.
- On Emu Test Set: Matches or surpasses SOTA in instruction adherence and image fidelity; GPT-4o scores rival closed-source Emu Edit despite using 0.5% training data.
- On MagicBrush Test Set: Closely matches ground truth edits, with strong performance in CLIP, DINO, and L1 metrics; outperforms open-source baselines and approaches SeedEdit in quality.
- VIE-Score Evaluation: Our method surpasses open-source SOTA and exceeds SeedEdit in overall VIE-Score with inference scaling; excels in unedited region preservation despite SeedEdit’s higher visual quality (PQ).
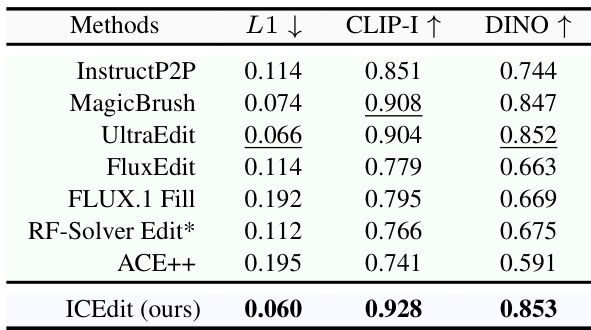
Results show that ICEdit achieves the lowest L1 score and the highest CLIP-I and DINO scores among all compared methods, indicating superior performance in preserving image fidelity and aligning with editing instructions. The authors use these metrics to demonstrate that their approach outperforms existing baselines on the MagicBrush test set.
The table presents a breakdown of the task types in the dataset, with removal and attribute modification being the most frequent categories, each accounting for over 11,000 instances, while swap and addition tasks are less common. The total count of 53,047 instances indicates a diverse and balanced dataset across various editing types, supporting comprehensive evaluation of editing models.
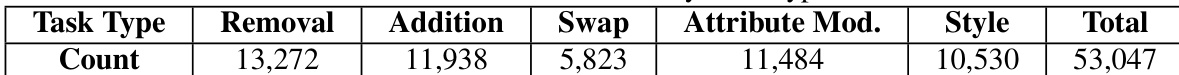
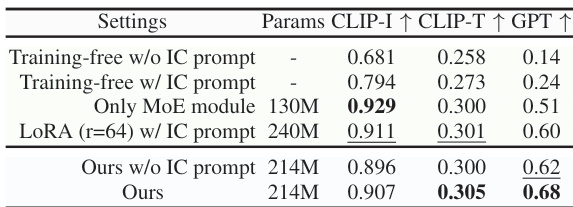
The authors use a training-free framework with an in-context prompt to evaluate editing performance, showing that adding the prompt improves CLIP-I and GPT scores. Their method with LoRA-MoE and an in-context prompt achieves the highest GPT score and competitive CLIP-I and CLIP-T scores, demonstrating improved instruction adherence and visual quality.
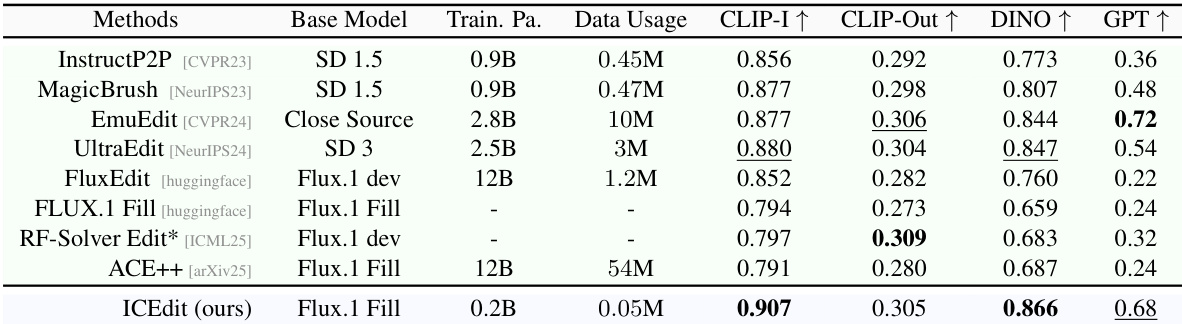
The authors use a DiT-based model with a fine-tuned LoRA-MoE architecture and a training dataset of 50K samples to achieve high editing performance. Results show that their method, ICEdit, outperforms existing open-source models on the Emu test set, achieving the highest scores in CLIP-I, DINO, and GPT-based evaluation, while using significantly fewer parameters and training data.
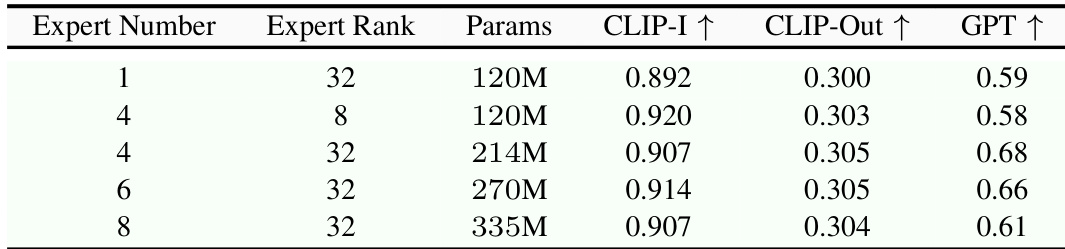
The authors investigate the impact of MoE expert configuration on model performance, finding that increasing the number of experts from 1 to 4 improves results, with the 4-expert, 32-rank setup achieving the highest GPT score of 0.68. However, further increasing the expert count to 8 leads to diminishing returns in performance while significantly increasing model parameters, indicating a trade-off between efficiency and effectiveness.