Command Palette
Search for a command to run...
TurboQuant: Online-Vektorquantisierung mit nahezu optimaler Verzerrungsrate
TurboQuant: Online-Vektorquantisierung mit nahezu optimaler Verzerrungsrate
Amir Zandieh Majid Daliri Majid Hadian Vahab Mirrokni
Zusammenfassung
Hier ist die professionelle Übersetzung des Textes ins Deutsche, unter Berücksichtigung der wissenschaftlichen Konventionen im Bereich der Informationstheorie und Signalverarbeitung:Die Vektorquantisierung (Vector Quantization), ein Problem, das in Shannons Quellencodierungstheorie verwurzelt ist, zielt darauf ab, hochdimensionale euklidische Vektoren zu quantisieren und dabei die Verzerrung ihrer geometrischen Struktur zu minimieren. Wir schlagen TURBOQUANT vor, um sowohl den mittleren quadratischen Fehler (Mean-Squared Error, MSE) als auch die Verzerrung des Skalarprodukts (Inner Product Distortion) zu adressieren und damit die Einschränkungen bestehender Methoden zu überwinden, die keine optimalen Verzerrungsraten erzielen können. Unsere datenunabhängigen (data-oblivious) Algorithmen, die für Online-Anwendungen geeignet sind, erreichen über alle Bitbreiten und Dimensionen hinweg nahezu optimale Verzerrungsraten (innerhalb eines kleinen konstanten Faktors). TURBOQUANT erreicht dies durch eine zufällige Rotation der Eingangsvektoren, wodurch eine konzentrierte Beta-Verteilung auf den Koordinaten induziert wird; zudem wird die Eigenschaft der nahezu Unabhängigkeit distinkter Koordinaten in hohen Dimensionen genutzt, um pro Koordinate einfach optimale Skalarquantisierer anzuwenden. Da MSE-optimale Quantisierer eine Verzerrung (Bias) bei der Schätzung des Skalarprodukts einführen, schlagen wir einen zweistufigen Ansatz vor: die Anwendung eines MSE-Quantisierers, gefolgt von einer 1-Bit Quantized JL (QJL) Transformation auf das Residuum, was zu einem unverzerrten (unbiased) Skalarprodukt-Quantisierer führt. Wir liefern zudem einen formalen Beweis für die informationstheoretischen unteren Schranken der bestmöglichen erzielbaren Verzerrungsrate durch jeden Vektorquantisierer und zeigen damit auf, dass TURBOQUANT diesen Schranken sehr nahe kommt und sich nur durch einen kleinen konstanten Faktor von ihnen unterscheidet.
One-sentence Summary
TurboQuant is a data-oblivious online vector quantization framework that achieves near-optimal distortion rates within a small constant factor for mean-squared error and inner product distortion across all bit-widths and dimensions by randomly rotating input vectors to enable optimal scalar quantization per coordinate and employing a two-stage approach that applies an MSE quantizer followed by a 1-bit Quantized JL transform on the residual to yield an unbiased inner product quantizer and match information-theoretic lower bounds.
Key Contributions
- The paper introduces TURBOQUANT, a data-oblivious algorithm designed to minimize both mean-squared error and inner product distortion in vector quantization. This method achieves near-optimal distortion rates across all bit-widths and dimensions by randomly rotating input vectors to leverage near-independence properties for scalar quantization.
- A two-stage approach is presented to eliminate bias in inner product estimation by applying an MSE quantizer followed by a 1-bit Quantized JL transform on the residual vector. This composition yields an unbiased inner product quantizer with provably optimal distortion bounds.
- The work provides a formal proof of information-theoretic lower bounds on the best achievable distortion rate for any vector quantizer. TURBOQUANT closely matches these bounds and achieves an exponential improvement over existing methods in terms of bit-width dependence.
Introduction
Vector quantization is essential for compressing high-dimensional vectors in large language models and vector databases to reduce memory demands and inference latency. Prior work often faces a trade-off where algorithms lack accelerator compatibility for real-time applications or suffer from suboptimal distortion bounds relative to bit-width. To overcome these limitations, the authors present TurboQuant, a lightweight online method optimized for modern hardware accelerators. This approach utilizes a two-stage process combining an MSE-optimal quantizer with a residual quantizer to deliver unbiased inner product estimates with provably optimal distortion rates.
Method
The TURBOQUANT framework addresses vector quantization by designing specific maps to minimize Mean-Squared Error (MSE) and inner product distortion. The core objective involves defining a quantization map Q:Rd→{0,1}B and an inverse dequantization map Q−1:{0,1}B→Rd. The authors aim to minimize the expected distortion for worst-case vectors without making assumptions about the input dataset.
For MSE optimization, the method employs a random rotation strategy to simplify the quantization landscape. The process begins by multiplying the input vector x with a random rotation matrix Π∈Rd×d. This rotation ensures that the resulting vector is uniformly distributed on the unit hypersphere. Consequently, each coordinate of the rotated vector follows a Beta distribution, which converges to a Gaussian distribution in high dimensions. Leveraging the near-independence of distinct coordinates in high dimensions, the authors apply optimal scalar quantizers to each coordinate independently. Optimal centroids for the Beta distribution are precomputed using the Max-Lloyd algorithm and stored in codebooks. During quantization, the algorithm identifies the nearest centroid for each rotated coordinate. Dequantization involves retrieving these centroids and applying the inverse rotation Π⊤ to reconstruct the vector in the original basis. A pseudocode for these procedures is given in Algorithm 1.
To handle inner product estimation, the authors recognize that MSE-optimal quantizers introduce bias. They propose a two-stage algorithm to achieve unbiased inner product estimates. The first stage applies the MSE-optimized quantizer Qmse using a bit-width of b−1. The second stage processes the residual error vector using a 1-bit Quantized Johnson-Lindenstrauss (QJL) transform. The QJL map projects the residual onto a random matrix with Gaussian entries and applies a sign function. The final reconstruction combines the MSE-dequantized vector and the scaled QJL reconstruction of the residual. This hybrid approach ensures the inner product estimator remains unbiased while maintaining low distortion rates. A pseudocode for this procedure is given in Algorithm 2.
Theoretical analysis establishes that TURBOQUANT achieves near-optimal distortion rates. By leveraging Shannon's lower bound and Yao's minimax principle, the authors prove that the MSE distortion is within a small constant factor of the information-theoretic lower bound. Similarly, the inner product distortion bounds are proven to be nearly optimal for any given bit-width. These guarantees hold across all bit-widths and dimensions, validating the efficiency of the proposed data-oblivious algorithms for online applications.
Experiment
The experiments utilize an NVIDIA A100 GPU to validate theoretical error bounds on the DBpedia dataset and evaluate downstream performance on long-context tasks using Llama-3.1-8B-Instruct and Ministral-7B-Instruct models. Results confirm that the proposed methods align with theoretical predictions by maintaining unbiased inner product estimation and achieving recall scores comparable to full-precision models under significant compression. Furthermore, near-neighbor search evaluations demonstrate consistent superiority over baseline quantization techniques in recall accuracy, highlighting the approach's robustness for high-dimensional search and generation tasks.
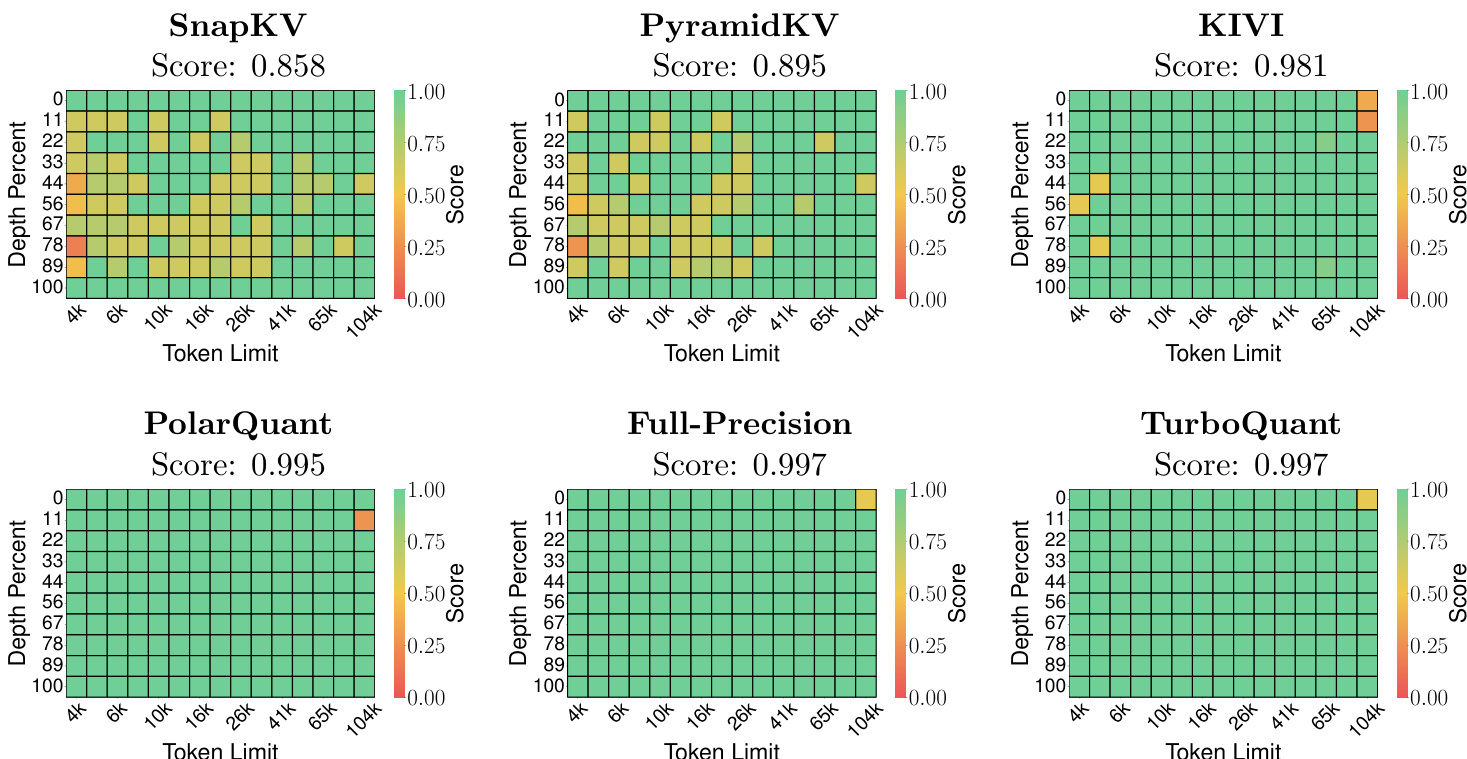
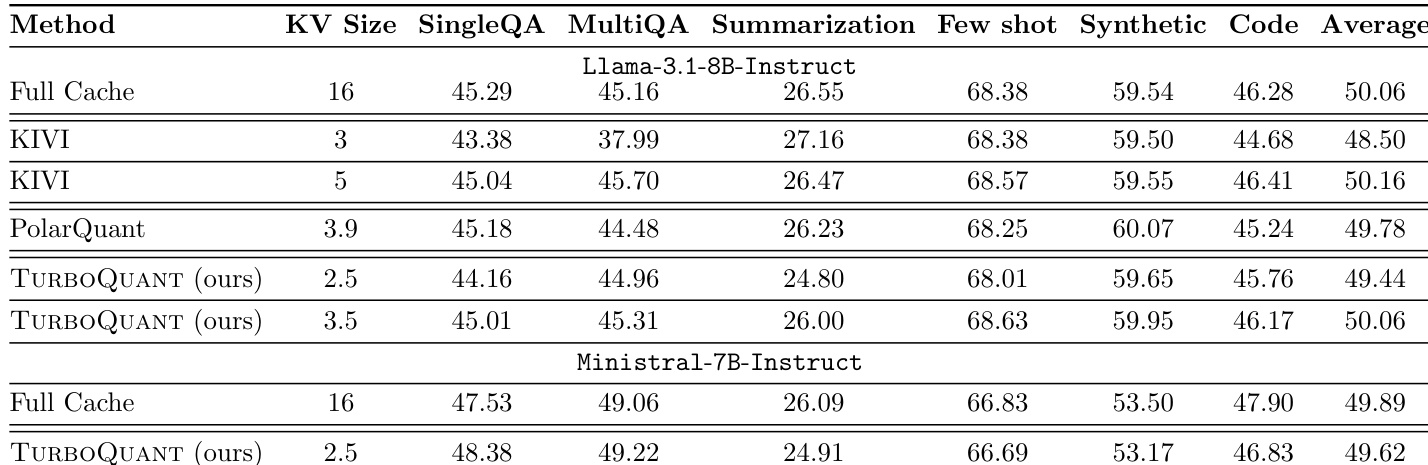
The authors evaluate KV cache compression methods on the LongBench dataset using Llama-3.1-8B-Instruct and Ministral-7B-Instruct models. Results indicate that TURBOQUANT achieves performance comparable to the full-precision baseline while utilizing significantly lower bit precisions. TURBOQUANT achieves average scores comparable to the full-precision baseline on the Llama model. The method maintains high performance on the Ministral model with reduced cache sizes. TURBOQUANT demonstrates competitive results against baselines like KIVI and PolarQuant across various tasks.
The the the table compares the quantization time of three different approaches across varying vector dimensions. TURBOQUANT consistently demonstrates significantly faster processing speeds compared to both Product Quantization and RabitQ. The efficiency advantage of TURBOQUANT becomes increasingly pronounced as the dimensionality of the data grows. TURBOQUANT maintains the lowest time cost across all tested dimensions. RabitQ incurs the highest computational overhead, especially at larger dimensions. Product Quantization is faster than RabitQ but lags significantly behind TURBOQUANT.

The evaluation assesses TURBOQUANT on the LongBench dataset using Llama-3.1-8B-Instruct and Ministral-7B-Instruct models to validate KV cache compression effectiveness. Results indicate that the method achieves performance comparable to full-precision baselines and remains competitive against approaches like KIVI and PolarQuant while utilizing significantly lower bit precisions. Furthermore, quantization time comparisons show that TURBOQUANT consistently processes data faster than Product Quantization and RabitQ across varying vector dimensions, with its efficiency advantage becoming more pronounced as dimensionality grows.