Command Palette
Search for a command to run...
PixelFlow: Pixel-Raum-basierte generative Modelle mit Flow
PixelFlow: Pixel-Raum-basierte generative Modelle mit Flow
Shoufa Chen Chongjian Ge Shilong Zhang Peize Sun Ping Luo
Zusammenfassung
Wir präsentieren PixelFlow, eine Familie von Bildgenerationsmodellen, die direkt im rohen Pixelraum arbeiten, im Gegensatz zu den dominierenden Modellen im latente Raum. Dieser Ansatz vereinfacht den Prozess der Bildgenerierung, indem er die Notwendigkeit eines vortrainierten Variationalen Autoencoders (VAE) entfällt und die gesamte Modellarchitektur end-to-end trainierbar macht. Durch eine effiziente Kaskaden-Flow-Modellierung erreicht PixelFlow eine vertretbare Rechenkostenlast im Pixelraum. Auf dem Benchmark der klassenbedingten Bildgenerierung für ImageNet mit 256×256 erreicht das Modell eine FID von 1,98. Die qualitativen Ergebnisse bei der Text-zu-Bild-Generierung zeigen, dass PixelFlow hervorragende Leistung in Bezug auf Bildqualität, künstlerische Ausprägung und semantische Steuerung erzielt. Wir hoffen, dass dieser neue Paradigma die Entwicklung zukünftiger visueller Generationsmodelle inspirieren und neue Möglichkeiten eröffnen wird. Der Quellcode und die Modelle sind unter https://github.com/ShoufaChen/PixelFlow verfügbar.
One-sentence Summary
The authors from The University of Hong Kong and Adobe propose PixelFlow, a family of end-to-end trainable image generation models operating directly in raw pixel space, eliminating the need for a VAE and enabling efficient cascade flow modeling with state-of-the-art FID of 1.98 on 256×256 ImageNet, achieving superior image quality, artistry, and semantic control in text-to-image generation.
Key Contributions
- PixelFlow introduces an end-to-end trainable image generation framework that operates directly in raw pixel space, eliminating the need for a pre-trained Variational Autoencoder (VAE) and enabling joint optimization of the entire model.
- It employs cascade flow modeling across multi-scale resolutions, progressively denoising and upsampling from low to high resolution, which significantly reduces computational cost while maintaining high fidelity.
- PixelFlow achieves state-of-the-art performance with an FID of 1.98 on the 256×256 ImageNet class-conditional benchmark and strong results on text-to-image evaluation metrics, including 0.64 on GenEval and 77.93 on DPG-Bench.
Introduction
The authors leverage the growing success of latent diffusion models (LDMs) in image generation, which rely on pre-trained VAEs to compress data into a lower-dimensional latent space for efficient diffusion. However, this two-stage design decouples the VAE and diffusion components, limiting end-to-end optimization and complicating model diagnosis. Prior pixel-space approaches, while more direct, suffer from prohibitive computational costs at high resolutions and often adopt cascaded pipelines—first generating low-resolution images and then upsampling—leading to inefficiencies and fragmented training. To address these challenges, the authors introduce PixelFlow, a novel end-to-end framework that performs direct image generation in raw pixel space without requiring a VAE or separate upsampler. By using flow matching across a cascade of progressively higher resolutions, PixelFlow reduces computational burden by denoising at lower resolutions early in the process and gradually upsampling. The model is trained end-to-end on multi-scale noisy samples, enabling efficient inference starting from low-resolution noise and progressively refining to target resolution. PixelFlow achieves competitive performance—1.98 FID on 256×256 ImageNet class-conditional generation and strong results on text-to-image benchmarks—demonstrating that direct pixel-space generation can be both efficient and high-quality.
Method
The authors leverage a flow matching framework to generate images directly in raw pixel space, bypassing the need for a pre-trained Variational Autoencoder (VAE) typically used in latent-space models. This approach enables end-to-end trainability and simplifies the generation pipeline. The core of the method is a cascade flow modeling strategy that progressively increases image resolution through multiple stages. As shown in the framework diagram, the generation process begins with a low-resolution noisy input and iteratively refines it to higher resolutions. At each stage, the model operates on a specific resolution level, transforming an intermediate noisy representation into a more refined version. The process is guided by a flow matching objective, where the model learns to predict the velocity field that maps samples from a prior distribution to the target data distribution. This is achieved by training the model to approximate the derivative of a linear interpolation between a noisy sample and a clean target sample, enabling the transformation from noise to image.

The multi-scale generation process is structured into S distinct stages, each operating over a defined time interval. For each stage s, the starting and ending states are constructed by linearly interpolating between a downsampled version of the target image and a noise sample. The starting state at stage s is defined as xt0s=t0s⋅Up(Down(x1,2s+1))+(1−t0s)⋅ϵ, and the ending state is xt1s=t1s⋅Down(x1,2s)+(1−t1s)⋅ϵ, where Down(⋅) and Up(⋅) represent downsampling and upsampling operations, respectively. Intermediate representations are sampled by linearly interpolating between these start and end states. The model is trained to predict the velocity vt=xt1s−xt0s, with the objective of minimizing the mean squared error between the predicted and target velocities. This training scheme allows the model to learn a continuous transformation path from noise to the final image across all resolution stages.

The model architecture for the flow matching component, μθ(⋅), is based on a Transformer, specifically a Diffusion Transformer (DiT) with XL-scale configurations. The input image is first processed by a patch embedding layer, which converts the spatial representation into a 1D sequence of tokens through a linear projection. This is a key distinction from prior work, as PixelFlow operates directly on raw pixel inputs rather than VAE-encoded latents. To handle variable resolutions efficiently, a sequence packing strategy is employed, concatenating flattened token sequences of different lengths along the sequence dimension within a single batch. The positional encoding is replaced with Rotary Positional Embedding (RoPE), adapted for 2D data by applying 1D-RoPE independently to the height and width dimensions. To enable the model to distinguish between different resolutions, a resolution embedding is introduced, which is encoded using sinusoidal position embedding and added to the timestep embedding before being passed into the model. For text-to-image generation, a cross-attention layer is added after each self-attention layer in the Transformer blocks, allowing the model to align visual features with textual conditioning signals derived from a language model.

During training, examples are uniformly sampled from all resolution stages using the interpolation scheme described. The sequence packing technique is also used to enable joint training of scale-variant examples within a single mini-batch, improving training efficiency. Inference begins with pure Gaussian noise at the lowest resolution. The generation process then proceeds through multiple stages, with each stage refining the image to a higher resolution. Within each stage, standard flow-based sampling methods, such as the Euler discrete sampler or the Dopr5 solver, are applied to generate samples. To ensure smooth transitions between scales and mitigate the jumping point issue common in multi-scale generation, a renoising strategy is adopted. This strategy helps maintain coherence and continuity in the generated image as it progresses through the resolution cascade.
Experiment
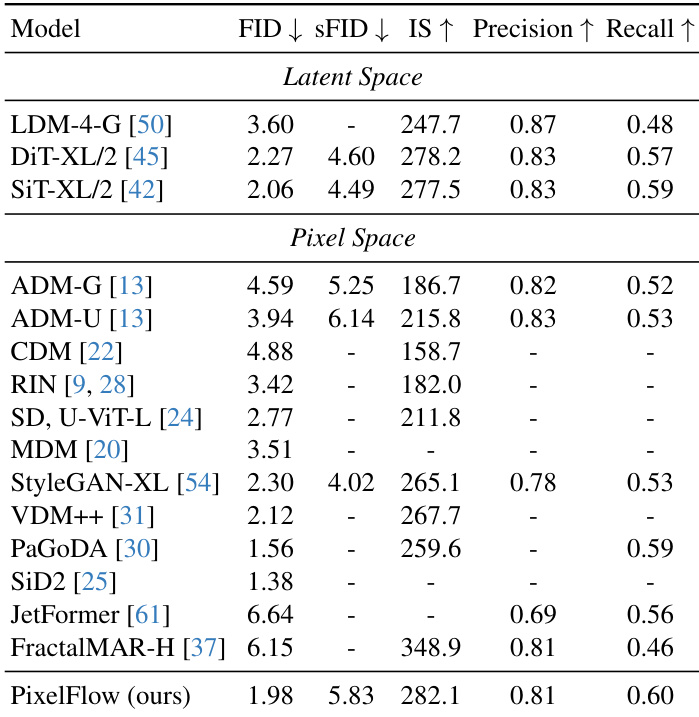
- Evaluated PixelFlow on class-conditional image generation using ImageNet-1K at 256×256 resolution, achieving an FID of 1.98, surpassing LDM (3.60), DiT (2.27), and SiT (2.06), with competitive Inception Score and recall.
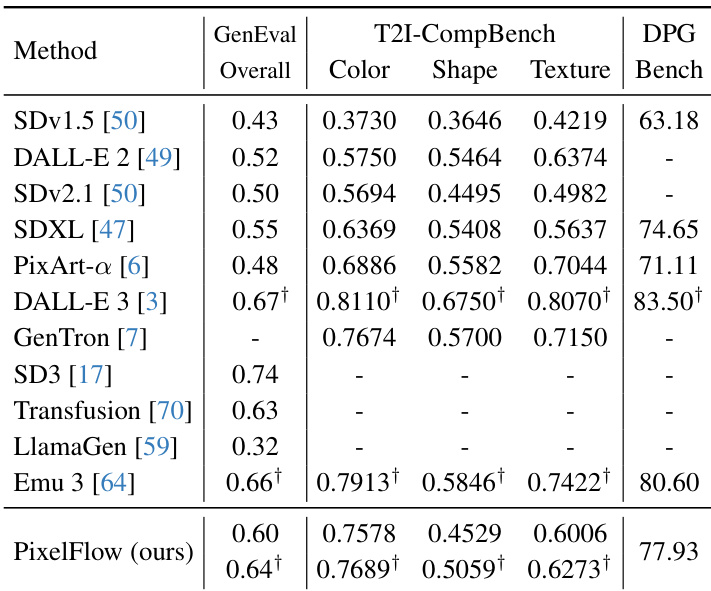
- Demonstrated superior performance in text-to-image generation on T2I-CompBench, GenEval, and DPG-Bench, achieving high scores in color and texture binding, 0.64 on GenEval, and 77.93 on DPG-Bench, outperforming multiple state-of-the-art models.
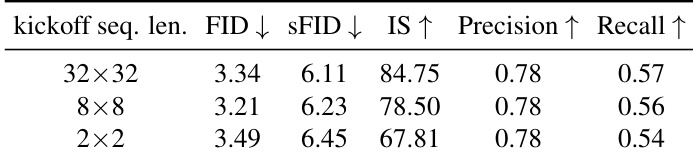
- Found that a kickoff sequence length of 8×8 and patch size of 4×4 optimize the trade-off between generation quality and computational efficiency, with 8×8 achieving comparable FID to 32×32 while improving efficiency.
- Showed that using the Dopri5 ODE solver and a stage-wise classifier-free guidance (CFG) schedule significantly improves sample quality, reducing FID from 2.43 to 1.98.
- Achieved high visual fidelity and strong text-image alignment in qualitative results, effectively capturing fine-grained details and complex semantic relationships across diverse prompts.
Results show that the stage-wise constant CFG schedule with a maximum value of 2.40 achieves a lower FID of 1.98 compared to the global constant schedule with a maximum value of 1.50, which has an FID of 2.43, while maintaining a similar Inception Score. This indicates that the proposed stage-wise CFG schedule improves generation quality by increasing the guidance strength progressively across resolution stages.
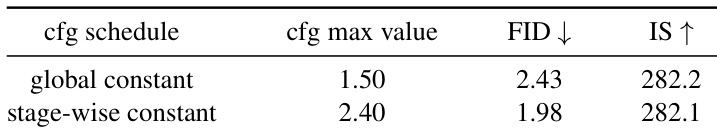
Results show that PixelFlow achieves competitive performance across multiple text-to-image benchmarks, outperforming several state-of-the-art models on T2I-CompBench and achieving strong results on GenEval and DPG-Bench, demonstrating its ability to generate high-quality images with accurate text-image alignment.
Results show that the Dopri5 solver achieves lower FID and sFID scores, higher Inception Score, and slightly better precision compared to the Euler solver, while maintaining similar recall, indicating that the adaptive higher-order solver produces higher-quality samples.

The authors use Table 1 to analyze the effect of kickoff sequence length on image generation performance. Results show that an 8×8 kickoff sequence achieves a lower FID (3.21) and higher Inception Score (78.50) compared to 32×32 (FID 3.34, IS 84.75), indicating better quality and efficiency. However, reducing the kickoff length further to 2×2 degrades performance, with a higher FID (3.49) and lower IS (67.81), suggesting that very low-resolution tokens provide insufficient guidance.
Results show that PixelFlow achieves competitive performance on the ImageNet 256×256 benchmark, outperforming several latent-based models such as LDM, DiT, and SiT, while also surpassing pixel-based methods like ADM-G, CDM, and FractalMAR-H. The model attains an FID of 1.98 and strong scores across all evaluation metrics, demonstrating its effectiveness in high-quality image generation.