Command Palette
Search for a command to run...
MonSter: Die Verbindung von Monodepth mit Stereo entfesselt Kraft
MonSter: Die Verbindung von Monodepth mit Stereo entfesselt Kraft
Zusammenfassung
Wir stellen MonSter++ vor, ein geometrisches Grundmodell für die Tiefenschätzung aus mehreren Ansichten, das die korrigierte Stereo-Abgleichung und die unkorrigierte Mehransichts-Stereo (Multi-View Stereo, MVS) vereint. Beide Aufgaben zielen darauf ab, metrische Tiefen aus der Korrespondenzsuche zu rekonstruieren und stehen daher vor demselben Dilemma: Schwierigkeiten bei der Behandlung schlecht gestellter Regionen mit begrenzten Abgleichhinweisen. Um dieses Problem anzugehen, schlagen wir MonSter++ vor – eine neuartige Methode, die monokulare Tiefenprioritäten in die Mehransichtstiefenschätzung integriert und somit die ergänzenden Stärken von Einzelansicht- und Mehransichtsignalen effektiv kombiniert. MonSter++ nutzt eine dual-bäumige Architektur, um monokulare und Mehransichtstiefen zu fusionieren. Eine vertrauensbasierte Steuerung wählt adaptiv zuverlässige Mehransichts-Hinweise aus, um die Skalenambiguität in der monokularen Schätzung zu korrigieren. Die verbesserten monokularen Vorhersagen wiederum leiten effektiv die Mehransichtsschätzung in schlecht gestellten Regionen an. Diese iterative gegenseitige Verbesserung ermöglicht es MonSter++, grobe objektbasierte monokulare Prioritäten in fein granulierte, pixelgenaue Geometrie zu transformieren und somit das volle Potenzial der Mehransichtstiefenschätzung auszuschöpfen. MonSter++ erreicht neue SOTA-Ergebnisse (State-of-the-Art) sowohl bei der Stereo-Abgleichung als auch bei der Mehransichts-Stereo. Durch die effektive Integration monokularer Prioritäten mittels unseres kaskadierten Such- und mehrskaligen Tiefenfusionsschemas übertrifft unsere Echtzeitvariante RT-MonSter++ auch deutlich frühere Echtzeitmethoden. Wie in Abb. 1 gezeigt, erzielt MonSter++ signifikante Verbesserungen gegenüber früheren Ansätzen auf acht Benchmarks aus drei Aufgabenbereichen – Stereo-Abgleichung, Echtzeit-Stereo-Abgleichung und Mehransichts-Stereo – und demonstriert damit die starke Allgemeingültigkeit unseres Ansatzes. Neben hoher Genauigkeit zeigt MonSter++ zudem eine hervorragende Fähigkeit zur Zero-Shot-Verallgemeinerung. Wir werden sowohl das große Modell als auch die Echtzeitvariante öffentlich zugänglich machen, um deren Nutzung durch die Open-Source-Community zu fördern.
One-sentence Summary
The authors, affiliated with Huazhong University of Science and Technology, Meta, and Autel Robotics, propose MonSter++, a unified geometric foundation model for multi-view depth estimation that integrates monocular depth priors through a dual-branched architecture with confidence-guided iterative refinement, enabling state-of-the-art performance in stereo matching, multi-view stereo, and real-time inference by jointly resolving scale ambiguity and enhancing ill-posed regions, with applications in autonomous driving and robotics.
Key Contributions
-
MonSter++ addresses the fundamental challenge of ill-posed regions in multi-view depth estimation—such as textureless areas and occlusions—by unifying stereo matching and multi-view stereo through a novel integration of monocular depth priors, enabling robust depth recovery where traditional correspondence-based methods fail.
-
The method introduces a dual-branched architecture with Stereo Guided Alignment (SGA) and Mono Guided Refinement (MGR) modules, which iteratively refine monocular depth by correcting scale and shift using reliable multi-view cues, while simultaneously enhancing multi-view depth estimation in ambiguous regions through adaptive guidance from refined monocular priors.
-
MonSter++ achieves state-of-the-art performance across eight benchmarks spanning stereo matching, multi-view stereo, and real-time stereo tasks, with RT-MonSter++ delivering 47 ms inference time and outperforming prior accuracy-focused methods like IGEV++ (280 ms), while also demonstrating strong zero-shot generalization on unseen datasets.
Introduction
The authors address the challenge of accurate multi-view depth estimation—critical for applications like autonomous driving and robotics—where traditional stereo matching and multi-view stereo methods struggle in ill-posed regions such as textureless areas, occlusions, and thin structures due to unreliable correspondence matching. Prior approaches have attempted to improve robustness by enhancing feature representations or incorporating coarse structural priors, but these often fail to resolve scale and shift ambiguities in monocular depth estimates, limiting their effectiveness when fused with multi-view data. To overcome this, the authors propose MonSter++, a unified framework that integrates monocular depth priors into a dual-branched architecture with iterative mutual refinement. By using confidence-guided, adaptive fusion through Stereo Guided Alignment and Mono Guided Refinement modules, MonSter++ corrects scale and shift errors in monocular depth while leveraging the refined priors to guide multi-view depth estimation in challenging regions. This synergistic design enables the model to evolve coarse monocular priors into fine-grained, pixel-level geometry, achieving state-of-the-art performance across stereo matching, multi-view stereo, and real-time inference benchmarks. The real-time variant, RT-MonSter++, further delivers superior speed-accuracy trade-offs, outperforming prior real-time methods by up to 20% on KITTI while maintaining strong zero-shot generalization.
Method
The authors propose MonSter++, a unified framework for accurate metric depth estimation applicable to both stereo matching and multi-view stereo. The architecture, illustrated in the framework diagram, consists of three primary components: a monocular depth estimation branch, a stereo matching branch, and a mutual refinement module. The two branches operate in parallel to generate initial estimates of relative monocular depth and stereo disparity, which are then iteratively refined through mutual feedback.
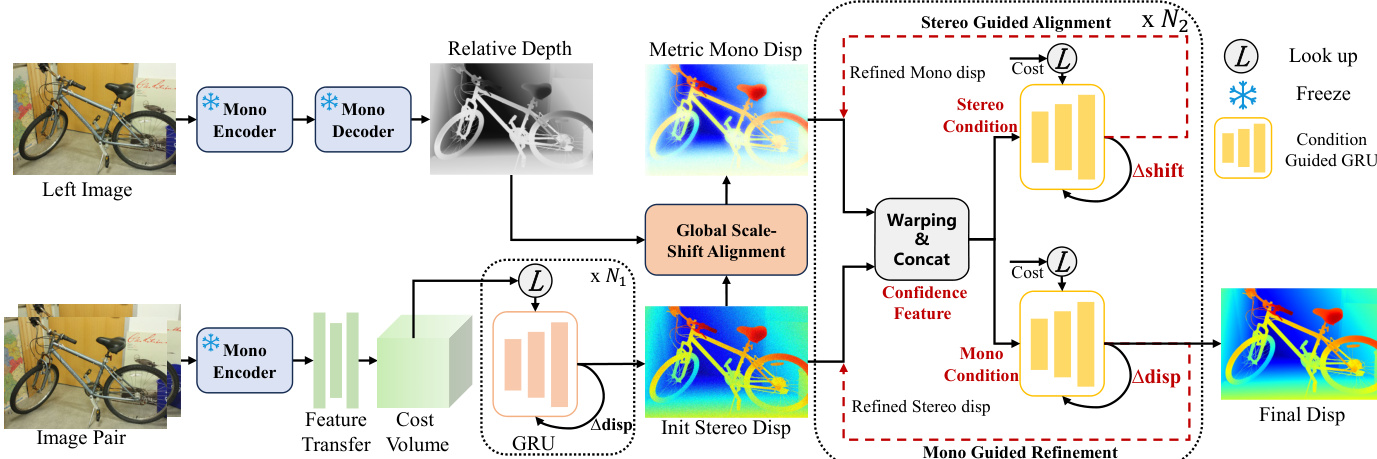
The monocular depth branch leverages a pretrained model, specifically DepthAnythingV2, which uses DINOv2 as its encoder and DPT as its decoder. To efficiently utilize this pre-trained model, the stereo matching branch shares the DINOv2 ViT encoder, with its parameters frozen to preserve the monocular model's generalization ability. The ViT encoder produces a single-resolution feature map, which is then processed by a feature transfer network—a stack of 2D convolutional layers—to generate a multi-scale feature pyramid F={F0,F1,F2,F3}, where Fk∈R25−kH×25−kW×ck. This pyramid is used to construct a Geometry Encoding Volume, and the initial stereo disparity is obtained using the same iterative optimization process as in IGEV, involving ConvGRUs, but limited to N1 iterations for efficiency.
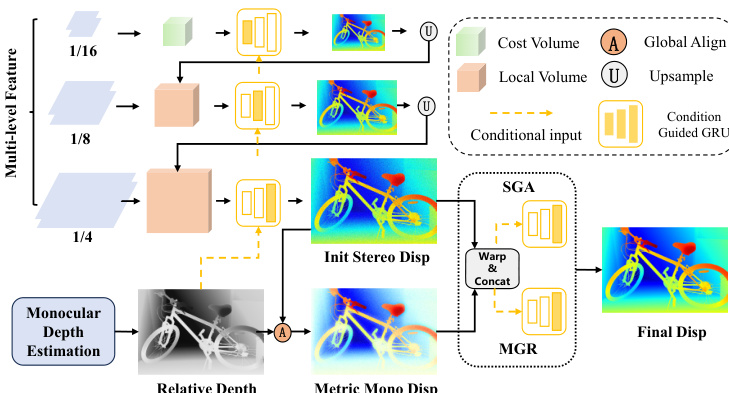
The mutual refinement module is the core of the framework, designed to iteratively improve both the monocular depth and stereo disparity estimates. The process begins with a global scale-shift alignment, which converts the inverse monocular depth into a disparity map and aligns it coarsely with the initial stereo disparity. This is achieved by solving a least squares optimization problem to find a global scale sG and shift tG that minimize the squared difference between the aligned monocular depth and the initial stereo disparity over a reliable region Ω.
Following this alignment, the refinement proceeds through two dual-branched stages. The first stage, Stereo Guided Alignment (SGA), uses stereo cues to refine the monocular disparity. It computes a confidence-based flow residual map FSj from the current stereo disparity DSj and uses it, along with geometry features GSj and the disparity itself, to form a stereo condition xSj. This condition is fed into a condition-guided ConvGRU to update the hidden state of the monocular branch, from which a residual shift Δt is decoded and applied to update the monocular disparity.
The second stage, Mono Guided Refinement (MGR), operates symmetrically to refine the stereo disparity using the aligned monocular prior. It computes flow residual maps and geometry features for both the monocular and stereo branches, forming a comprehensive monocular condition xMj. This condition is used to update the hidden state of the stereo branch's ConvGRU, from which a residual disparity Δd is decoded and applied to refine the stereo disparity. This dual refinement process is repeated for N2 iterations, resulting in the final stereo disparity output.
For the multi-view stereo task, the framework remains structurally identical, with the primary difference being the cost volume construction. Instead of the Geometry Encoding Volume used for stereo matching, a variance-based cost metric is employed to measure feature similarity across multiple unrectified views, which is then aggregated into a cost volume of the same dimensions. The subsequent processing stages, including the mutual refinement, are identical to the stereo matching pipeline.
Experiment
- MonSter++ is implemented with PyTorch using NVIDIA RTX 4090 GPUs, trained with AdamW optimizer, one-cycle learning rate schedule (2e-4), batch size 8, and 200k steps. The monocular branch uses a frozen ViT-large DepthAnythingV2 model. A two-stage training strategy is adopted, using a Basic Training Set (BTS) and an expanded Full Training Set (FTS) with over 2 million image pairs from 14 public datasets.
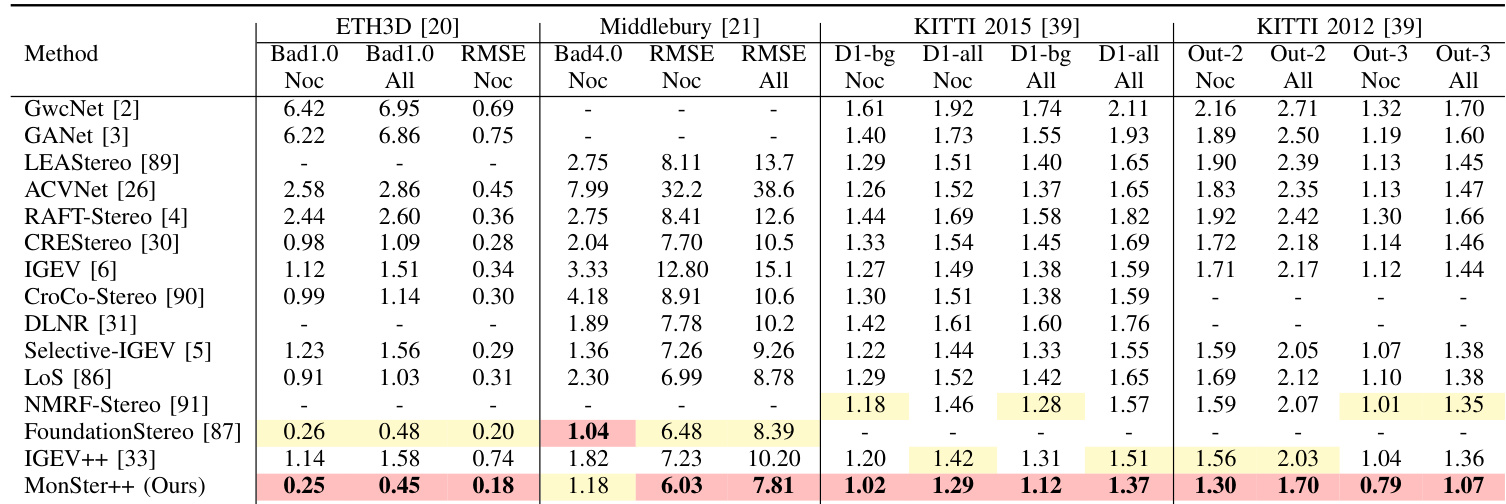
- On stereo matching benchmarks, MonSter++ achieves state-of-the-art results: 0.37 EPE on Scene Flow (21.28% better than baseline [6], 15.91% better than SOTA [5]), ranks 1st on ETH3D (77.68% improvement over IGEV in RMSE Noc), and leads on Middlebury (6.94% improvement over FoundationStereo in RMSE Noc). On KITTI 2012 and 2015, it surpasses CREStereo and Selective-IGEV by 18.93% and 11.61% on D1-all, and achieves 16.26% and 20.74% improvements in Out-2 and Out-3 metrics over IGEV++ and NMRF-Stereo.
- In multi-view stereo, MonSter++ achieves SOTA performance on DDAD (14.8% improvement over [13] in AbsRel) and KITTI Eigen split (18.11% and 21.21% improvement over [15] and [13] in SqRel).
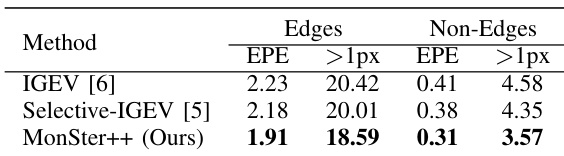
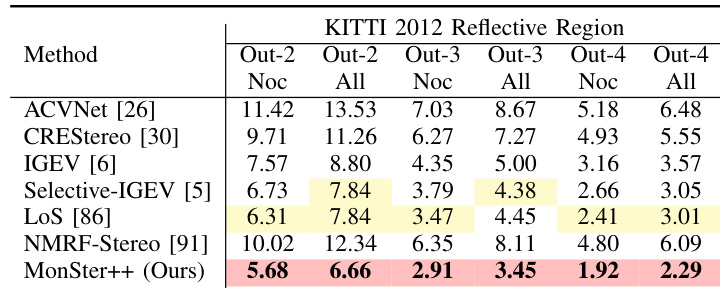
- MonSter++ excels in ill-posed regions: on reflective areas of KITTI 2012, it improves Out-3 and Out-4 by 57.46% and 62.40% over NMRF-Stereo; in edge and non-edge regions of Scene Flow, it outperforms baseline by 14.35% and 24.39%; on distant backgrounds in KITTI 2015, it improves D1-bg by 18.84%.
- The real-time version RT-MonSter++ runs at over 20 FPS at 1K resolution, achieves SOTA accuracy on KITTI 2012 and 2015 (19.23% and 20.75% better than RT-IGEV++ on Out-4 and Out-5), and shows superior zero-shot generalization—especially on Middlebury (34.1% improvement in 2-pixel outlier rate) and ETH3D (32.0% gain over RT-IGEV++), with inference cost only one-third of IGEV.
- MonSter++ demonstrates strong zero-shot generalization: trained on Scene Flow, it reduces average error across KITTI, Middlebury, and ETH3D from 5.03 to 3.70 (26.4% improvement over IGEV); trained on FTS, it improves Middlebury and ETH3D by 39.5% and 60.0%; on DrivingStereo, it achieves 49.3% better performance in rainy conditions and 45.4% lower average error than FoundationStereo.
- Ablation studies confirm the effectiveness of key components: MGR fusion improves EPE by 6.52% over convolutional fusion; SGA refinement boosts EPE by 9.30% and 1-pixel error by 10.69%; feature sharing improves EPE by 5.13%; MonSter++ remains effective with different monocular models (e.g., MiDaS, [66]); and the method achieves SOTA accuracy with only 4 inference iterations, offering a superior accuracy-speed trade-off.
The authors use the RT-MonSter++ model to evaluate real-time stereo matching performance on KITTI 2012 and KITTI 2015 benchmarks, achieving the best results among real-time methods. Results show that RT-MonSter++ significantly outperforms previous state-of-the-art real-time approaches, with improvements of up to 21.45% on the D1-fg (Noc) metric for KITTI 2015, while maintaining inference speeds over 20 FPS at 1K resolution.
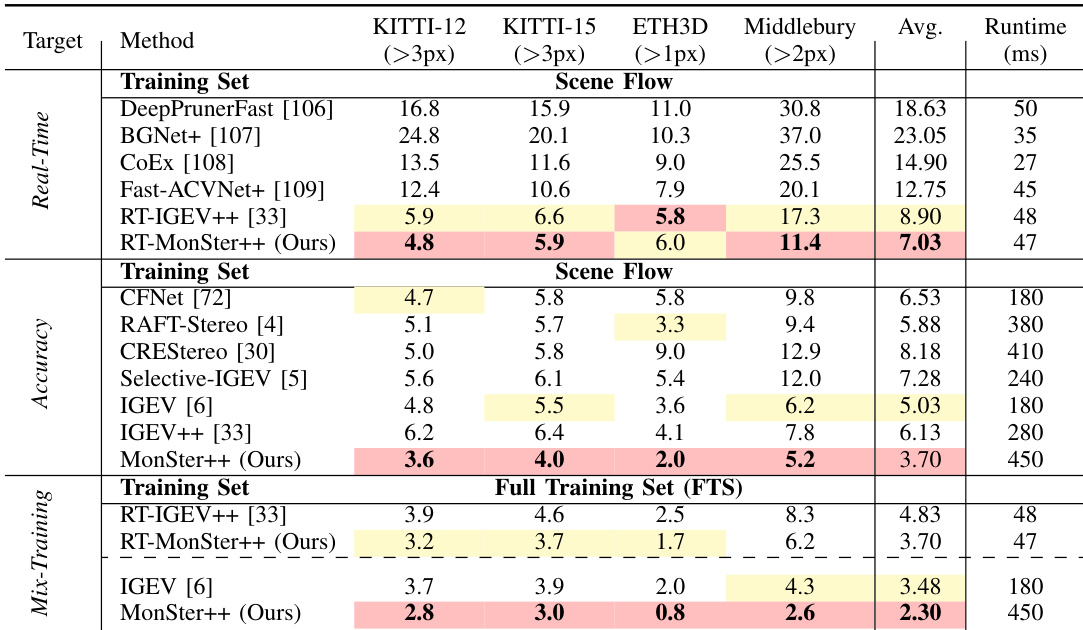
Results show that MonSter++ achieves the lowest EPE metric of 0.37 on the Scene Flow benchmark, outperforming all compared methods by a significant margin, with a 15.91% improvement over the previous state-of-the-art method.

The authors use MonSter++ to achieve state-of-the-art performance on multiple stereo matching benchmarks, with the method ranking first on ETH3D, Middlebury, KITTI 2012, and KITTI 2015. Results show that MonSter++ significantly outperforms existing methods, achieving improvements of up to 77.68% in Bad1.0 (Noc) on ETH3D and 18.93% on D1-all for KITTI 2015, while also demonstrating strong generalization and efficiency in real-time applications.
The authors evaluate MonSter++ on the reflective regions of the KITTI 2012 benchmark, where it achieves the best performance across all reported metrics. MonSter++ surpasses the previous state-of-the-art method NMRF-Stereo by 57.46% and 62.40% on the Out-3 (All) and Out-4 (All) metrics, respectively, demonstrating significant improvements in handling challenging reflective areas.
Results show that MonSter++ outperforms IGEV and Selective-IGEV on both edge and non-edge regions of the Scene Flow test set. On edge regions, MonSter++ achieves a 14.35% improvement in EPE and a 24.39% improvement in the >1px error metric compared to the baseline, while on non-edge regions, it improves EPE by 12.39% and the >1px error by 18.42% compared to the SOTA method [5].