Command Palette
Search for a command to run...
Pyramidal Flow Matching für eine effiziente Video-Generativmodellierung
Pyramidal Flow Matching für eine effiziente Video-Generativmodellierung
Zusammenfassung
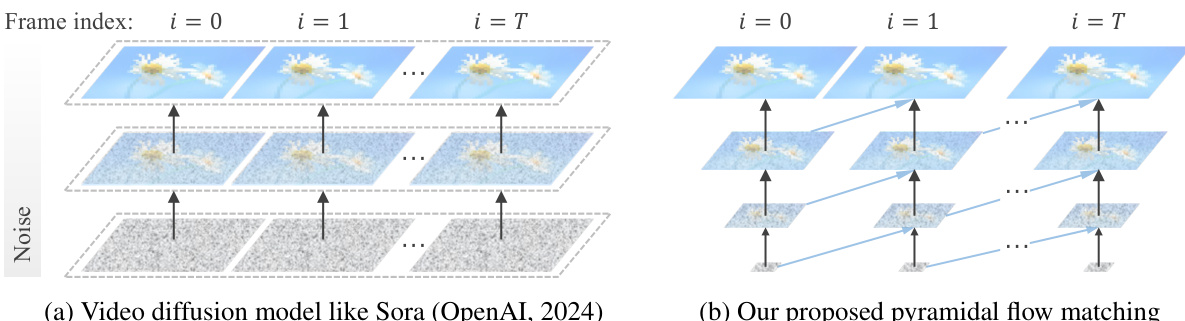
Die Videogenerierung erfordert die Modellierung eines umfangreichen spatiotemporalen Raums, was erhebliche Rechenressourcen und Datenverbrauch mit sich bringt. Um die Komplexität zu reduzieren, setzen die gängigen Ansätze eine kaskadierte Architektur ein, um eine direkte Trainingsphase mit voller Auflösung im latente Raum zu vermeiden. Obwohl dies die rechnerischen Anforderungen senkt, behindert die getrennte Optimierung jeder Teilstufe den Wissensaustausch und führt zu einer Einschränkung der Flexibilität. In dieser Arbeit stellen wir einen einheitlichen pyramidalen Flussübereinstimmungsalgorithmus vor. Er interpretiert die ursprüngliche Entrauschungstrajektorie neu als eine Folge von Pyramidenstufen, wobei lediglich die letzte Stufe mit voller Auflösung arbeitet, wodurch eine effizientere Modellierung von Videos ermöglicht wird. Durch unsere anspruchsvolle Architektur können die Flüsse verschiedener Pyramidenstufen miteinander verknüpft werden, um Kontinuität zu gewährleisten. Zudem entwickeln wir eine autoregressive Videogenerierung mit einer zeitlichen Pyramide, um die vollauflösende Historie zu komprimieren. Der gesamte Rahmen kann end-to-end optimiert werden und nutzt dabei einen einzigen, einheitlichen Diffusion Transformer (DiT). Umfangreiche Experimente zeigen, dass unsere Methode die Erzeugung von hochwertigen Videos mit einer Länge von 5 Sekunden (bis zu 10 Sekunden), einer Auflösung von 768p und einer Bildwiederholfrequenz von 24 FPS innerhalb von 20.700 GPU-Stunden auf A100-Grafikkarten ermöglicht. Der gesamte Quellcode und die Modelle sind unter https://pyramid-flow.github.io öffentlich zugänglich.
One-sentence Summary
The authors from Peking University, Kuaishou Technology, and Beijing University of Posts and Telecommunications propose a unified pyramidal flow matching framework that reinterprets video generation as a multi-stage process, enabling end-to-end training with a single Diffusion Transformer while reducing computational cost through hierarchical flow interlinking and autoregressive temporal pyramid compression, achieving high-quality 768p 24 FPS video generation up to 10 seconds with only 20.7k A100 GPU hours.
Key Contributions
- Existing video generation methods face high computational costs due to modeling large spatiotemporal spaces at full resolution, often relying on cascaded architectures that separately optimize multiple stages, leading to inefficiency and limited knowledge sharing.
- This work introduces a unified pyramidal flow matching framework that reinterprets the generation process as a sequence of spatial and temporal pyramid stages, where only the final stage operates at full resolution, enabling efficient joint optimization through a single Diffusion Transformer.
- The method achieves state-of-the-art video generation quality on 768p at 24 FPS for up to 10-second videos, reducing training tokens by over 85% compared to full-sequence diffusion and demonstrating strong performance on VBench and EvalCrafter benchmarks.
Introduction
Video generation using diffusion and autoregressive models has achieved impressive results in realism and duration, but remains computationally expensive due to the need to model large spatiotemporal spaces. Prior approaches often rely on cascaded architectures that generate video in stages—first at low resolution and then upsampled with separate super-resolution models. While this reduces per-stage computation, it introduces inefficiencies through disjoint model training, limited knowledge sharing, and lack of scalability. The authors propose pyramidal flow matching, a unified framework that reinterprets video generation as a multi-scale process operating across spatial and temporal pyramids. By compressing latent representations at early stages and progressively decompressing them, the method reduces the number of tokens during training—cutting computational load by over 85% for a 10-second video—while maintaining high-quality output. The key innovation is a single diffusion transformer trained end-to-end with a piecewise flow matching objective that links all pyramid stages, enabling simultaneous generation and decompression without separate models. This approach improves training efficiency, simplifies implementation, and supports scalable, high-resolution video synthesis.
Dataset
- The training dataset is a mixed corpus of open-source image and video data, combining multiple high-quality, publicly available sources.
- Image data includes:
- 11 million images from CC-12M, selected for high quality and diversity.
- 6.9 million non-blurred images from SA-1B, filtered to exclude blurred content.
- 4.4 million images from JourneyDB, a curated dataset of high-quality image-text pairs.
- 14 million publicly available synthetic images, generated to augment real-world data.
- A high-aesthetic subset of LAION-5B totaling 11 million images, selected based on aesthetic quality scores.
- Video data includes:
- 10 million videos from WebVid-10M, a large-scale web-crawled video-text dataset.
- 1 million videos from OpenVid-1M, a recently released open video dataset.
- 1 million high-resolution, non-watermarked videos sourced primarily from the Open-Sora Plan (PKU-Yuan Lab, 2024).
- After postprocessing, approximately 10 million single-shot videos are available for training, with consistent formatting and quality filtering.
- The model is trained using a mixture of these datasets, with training splits determined by the original dataset distributions and adjusted for balance. Mixture ratios are optimized to ensure robust performance across diverse visual and temporal patterns.
- Data is processed using a 3D Variational Autoencoder (VAE) with an 8×8×8 downsampling ratio, compressing both spatial and temporal dimensions. The VAE is trained from scratch on WebVid-10M and shares structural similarities with MAGVIT-v2.
- A 3D pyramid structure with three stages is used to represent video data at multiple resolutions.
- To improve training stability, corruptive noise with strength uniformly sampled from [0, 1/3] is applied to the history pyramid conditions, helping mitigate autoregressive generation degradation.
- The model uses a 2B-parameter MM-DiT architecture based on SD3 Medium, with sinusoidal position encoding in spatial dimensions and 1D Rotary Position Embedding (RoPE) for temporal modeling, enabling flexible training across variable video lengths.
Method
The authors leverage a unified pyramidal flow matching framework to address the computational challenges of video generation by reinterpreting the denoising process as a series of spatial pyramid stages. This approach avoids the need for separate models at each resolution, enabling knowledge sharing and a more efficient training process. The core of the method is a spatial pyramid that decomposes the generation process into multiple stages, each operating at a progressively higher resolution. As shown in the framework diagram, the process begins at a low-resolution, noisy latent and proceeds through a sequence of stages, with only the final stage operating at the full resolution. This design significantly reduces computational cost, as most stages are performed at lower resolutions. The flow within each stage is defined by a piecewise interpolation between successive resolutions, where the interpolation is parameterized by a rescaled timestep. The authors further unify the objectives of generation and decompression by curating a probability path that interpolates between different noise levels and resolutions, allowing a single model to handle both tasks. This unified modeling is achieved by defining a conditional probability path for each stage, where the endpoints are sampled in a coupled manner to ensure the flow trajectory is straight. The flow model is trained to regress the velocity field on this conditional vector field, resulting in a single, end-to-end trainable model.
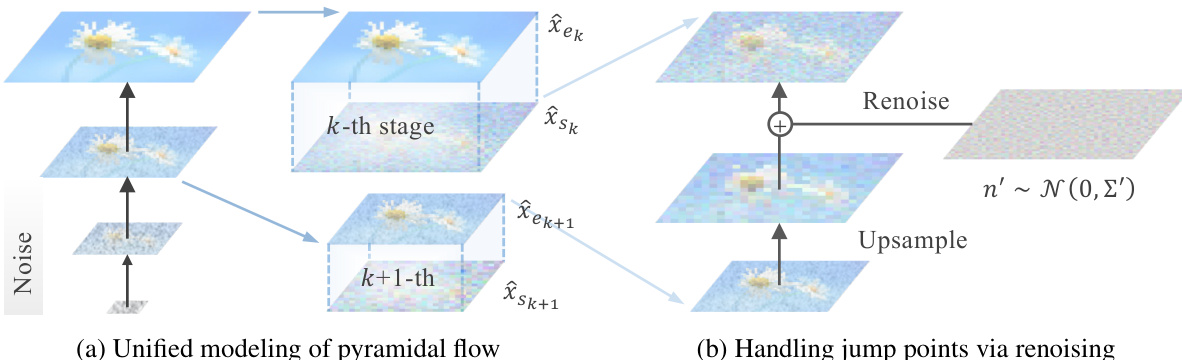
During inference, the method must carefully handle the jump points between successive pyramid stages to ensure continuity of the probability path. The authors propose a renoising scheme to address this. The process begins by upsampleing the previous low-resolution endpoint, which results in a Gaussian distribution. To match this distribution with the starting point of the next stage, a linear transformation and corrective noise are applied. The rescaling coefficient ensures the means of the distributions match, while the corrective noise, with a weight determined by the upsampling function, matches the covariance matrices. For nearest neighbor upsampling, the authors derive a specific renoising rule that involves a rescaling factor and a noise term with a covariance matrix designed to reduce correlation within each block. This ensures that the probability path remains continuous across stages, allowing for smooth generation.
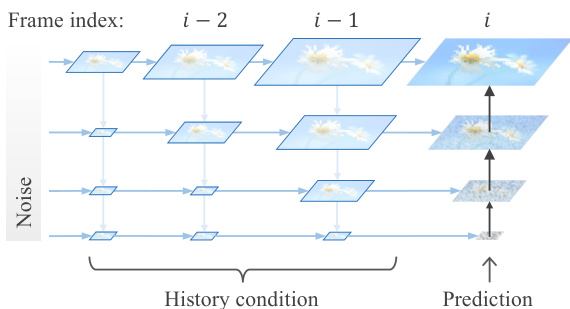
To further improve training efficiency, the authors introduce a temporal pyramid design for autoregressive video generation. This design reduces the computational redundancy in the full-resolution history condition by using compressed, lower-resolution history for each prediction. As illustrated in the figure, at each pyramid stage, the generation is conditioned on a history of past frames that have been progressively downsampled. This significantly reduces the number of training tokens, as most frames are computed at the lowest resolution. The method also employs a compatible position encoding scheme that extrapolates in the spatial pyramid to preserve fine-grained details and interpolates in the temporal pyramid to ensure spatial alignment of the history conditions. This allows the model to efficiently learn from long video sequences while maintaining high-quality generation.
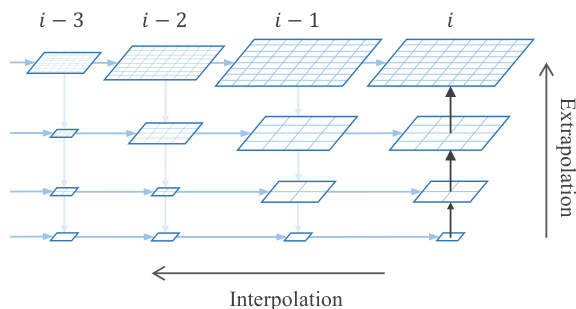
The practical implementation of this framework uses a standard Transformer architecture, specifically a Diffusion Transformer (DiT). The authors adopt full sequence attention, which is made feasible by the reduced number of tokens due to the pyramidal representation. Blockwise causal attention is used to ensure that each token can only attend to its preceding frames, which is crucial for autoregressive generation. The position encoding is designed to be compatible with the pyramid structure, extrapolating in the spatial domain and interpolating in the temporal domain. The model is trained in a three-stage process, starting with image data to learn visual dependencies, followed by low-resolution video training, and finally high-resolution video fine-tuning. This training strategy, combined with the efficient pyramidal designs, enables the model to generate high-quality videos at scale.
Experiment
- Proposed pyramidal flow matching framework reduces computational and memory overhead in video generation training by up to 16^K, enabling training of a 10-second, 241-frame video model in only 20.7k A100 GPU hours—significantly less than Open-Sora 1.2, which requires over 40k GPU hours for fewer frames and lower quality.
- On VBench and EvalCrafter benchmarks, the model achieves state-of-the-art performance among open-source methods, surpassing CogVideoX-5B (twice the model size) in quality and motion smoothness (84.74 vs. 84.11 on VBench), and outperforming Gen-3 Alpha in key metrics despite training on public data only.
- User studies confirm superior preference in aesthetic quality, motion smoothness, and semantic alignment over open-source baselines like CogVideoX and Open-Sora, particularly due to support for 24 fps generation (vs. 8 fps in baselines).
- Ablation studies validate the effectiveness of spatial and temporal pyramids: the spatial pyramid accelerates FID convergence by nearly three times, while the temporal pyramid enables stable, coherent video generation where full-sequence diffusion fails to converge.
- The model demonstrates strong image-to-video generation capability via autoregressive inference, producing 5-second 768p videos with rich motion dynamics, and generates high-quality images even with few million training samples.
- Corrective noise in spatial pyramid inference and blockwise causal attention are critical for reducing artifacts and ensuring temporal coherence, with ablations showing significant degradation in visual quality and motion consistency without them.
- Despite limitations in long-term subject consistency and lack of non-autoregressive generation, the method achieves cinematic-quality video generation with competitive performance against commercial models using a fraction of the training cost.
The authors use a pyramidal flow matching framework to achieve efficient video generation, significantly reducing computational and memory requirements compared to full-sequence diffusion. Results show that their model, trained on public datasets, achieves competitive performance on VBench and EvalCrafter benchmarks, outperforming several open-source models and approaching the quality of commercial systems like Gen-3 Alpha and Kling, particularly in motion smoothness and dynamic degree.
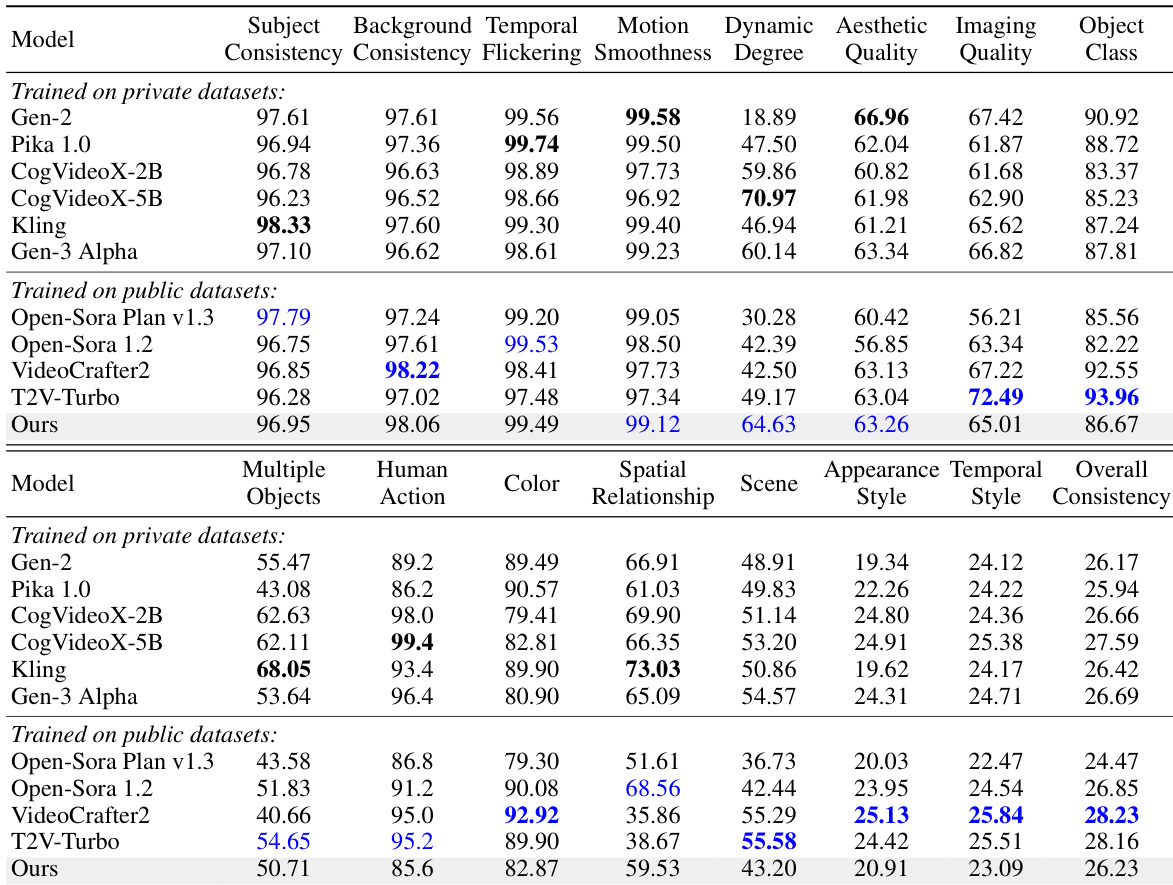
The authors use a pyramidal flow matching framework to achieve efficient video generation, significantly reducing computational and memory requirements compared to full-sequence diffusion. Results show that their method outperforms several open-source and commercial models on key metrics such as visual quality and motion smoothness, achieving competitive performance with models trained on larger proprietary datasets while using only publicly available data.
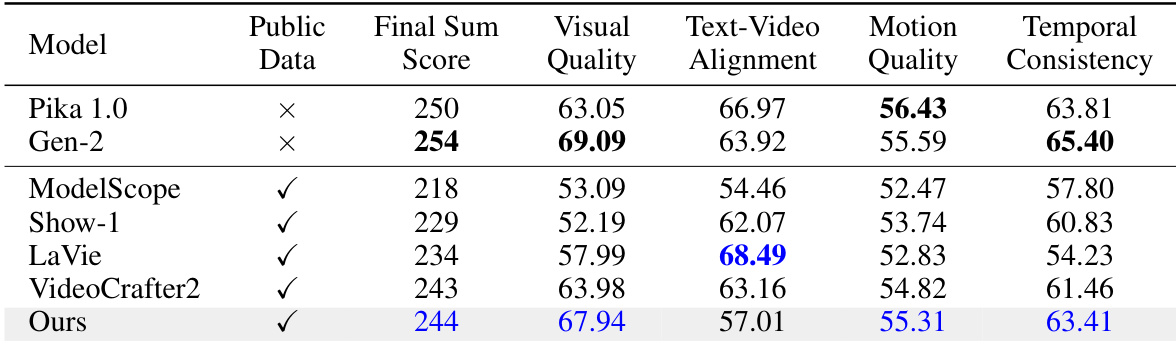
The authors use a pyramidal flow matching framework to achieve efficient video generation, significantly reducing computational and memory requirements compared to full-sequence diffusion. Results show that their model, trained on public datasets, outperforms several open-source and commercial baselines in key metrics such as motion quality and visual fidelity, achieving competitive performance with models trained on larger proprietary data.
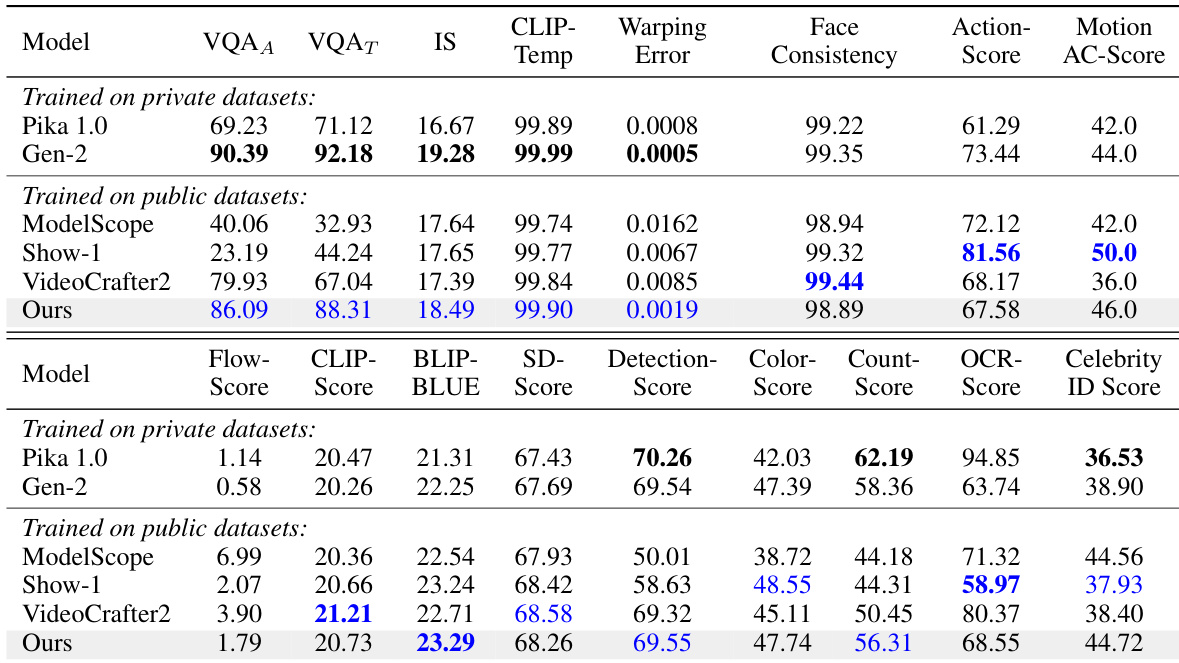
The authors use a pyramidal flow matching framework to achieve efficient video generation, significantly reducing computational and memory requirements compared to full-sequence diffusion. Results show that their method outperforms several open-source and commercial models on VBench, achieving a higher quality score (84.74) and motion smoothness than Gen-3 Alpha, while using only publicly available data and a smaller computational budget.

The authors use a user study to compare their model against several baselines, including Open-Sora, CogVideoX, and Kling, on aesthetic quality, motion smoothness, and semantic alignment. Results show that their model is preferred over open-source models like Open-Sora and CogVideoX-2B, particularly in motion smoothness, due to the efficiency gains from pyramidal flow matching enabling higher frame rates. It also achieves competitive performance against commercial models like Kling and Gen-3 Alpha, especially in motion quality and visual aesthetics.
