Command Palette
Search for a command to run...
Allgemeine OCR-Theorie: Hin zum OCR-2.0 durch ein einheitliches End-to-End-Modell
Allgemeine OCR-Theorie: Hin zum OCR-2.0 durch ein einheitliches End-to-End-Modell
Zusammenfassung
Traditionelle OCR-Systeme (OCR-1.0) sind aufgrund der wachsenden Nachfrage nach intelligenter Verarbeitung künstlich erzeugter optischer Zeichen zunehmend nicht mehr in der Lage, den Anforderungen der Nutzer gerecht zu werden. In diesem Artikel bezeichnen wir gemeinsam alle künstlichen optischen Signale – beispielsweise Fließtexte, mathematische bzw. molekulare Formeln, Tabellen, Diagramme, Notenschriften sowie sogar geometrische Figuren – als „Zeichen“ und stellen die General OCR-Theorie sowie ein herausragendes Modell, namens GOT, vor, um den Eintritt in die Ära des OCR-2.0 zu fördern. Das GOT-Modell mit 580 M Parametern ist ein einheitliches, elegantes und end-to-end-Modell, bestehend aus einem hochkomprimierenden Encoder und einem langen Kontext berücksichtigenden Decoder. Als OCR-2.0-Modell ist GOT in der Lage, alle oben genannten „Zeichen“ unter verschiedenen OCR-Aufgaben zu verarbeiten. Auf der Eingabeseite unterstützt das Modell übliche Szenen- und Dokumentbilder sowohl im Slice- als auch im Ganzzweistil. Auf der Ausgabeseite kann GOT durch einen einfachen Prompt sowohl unformatierte als auch formatierte Ergebnisse (z. B. in Markdown, TikZ, SMILES, Kern) generieren. Zudem verfügt das Modell über interaktive OCR-Funktionen, beispielsweise eine regionbasierte Erkennung, die durch Koordinaten oder Farben geleitet wird. Darüber hinaus haben wir dynamische Auflösungsanpassung und Multi-Page-OCR-Technologien an das GOT-Modell angepasst, um dessen praktische Anwendbarkeit weiter zu verbessern. In Experimenten liefern wir ausreichende Ergebnisse, die die Überlegenheit unseres Modells belegen.
One-sentence Summary
The authors, from StepFun, Megvii Technology, University of Chinese Academy of Sciences, and Tsinghua University, propose GOT, a 580M-parameter unified end-to-end model for OCR-2.0 that generalizes beyond text to handle diverse artificial optical signals—such as math formulas, tables, charts, and geometric shapes—via a high-compression encoder and long-context decoder, supporting slice/whole-page input, formatted outputs (Markdown/TikZ/SMILES), interactive region-level recognition, dynamic resolution, and multi-page processing, significantly advancing intelligent document understanding.
Key Contributions
- The paper introduces General OCR Theory and proposes GOT, a unified OCR-2.0 model designed to overcome the limitations of traditional OCR-1.0 systems and large vision-language models (LVLMs), by supporting end-to-end processing of diverse artificial optical signals—including text, math formulas, tables, charts, sheet music, and geometric shapes—under a single architecture.
- GOT features a high-compression encoder (80M parameters) and a long-context decoder (580M parameters), enabling efficient handling of both whole-page and sliced inputs, with support for dynamic resolution and multi-page OCR, while allowing interactive region-level recognition via coordinates or colors.
- The model achieves strong performance across diverse OCR tasks through a three-stage training strategy and synthetic data generation, demonstrating superior results on benchmarks involving formatted outputs (e.g., Markdown, TikZ, SMILES) and high-density text scenes.
Introduction
The authors address the growing need for intelligent, versatile optical character recognition (OCR) in real-world applications, where users demand processing of diverse artificial visual content—such as text, mathematical formulas, tables, charts, sheet music, and geometric shapes—beyond traditional text-only recognition. Prior OCR systems (OCR-1.0) rely on complex, modular pipelines that suffer from high maintenance costs, error propagation, and poor generalization across tasks. Meanwhile, Large Vision-Language Models (LVLMs), while powerful, are ill-suited for pure OCR due to high parameter counts, inefficient token compression for dense text, and excessive training costs, especially when adding new OCR patterns like languages or formats. To overcome these limitations, the authors propose General OCR Theory (OCR-2.0), introducing GOT—a unified, end-to-end model with 580M parameters. GOT features a high-compression encoder and a long-context decoder, enabling efficient recognition of diverse "characters" from both sliced and whole-page inputs. It supports interactive, region-level recognition via coordinates or colors, dynamic resolution for ultra-high-resolution images, multi-page OCR, and structured output generation (e.g., Markdown, TikZ, SMILES) through prompt control. The model is trained via a three-stage strategy using synthetic data, achieving strong performance across tasks while maintaining low inference and training costs.
Dataset
- The dataset comprises approximately 5 million image-text pairs, sourced from diverse real-world and synthetic data, used across multiple pre-training and fine-tuning stages.
- For scene text OCR, 2 million image-text pairs are derived from Laion-2B (English) and Wukong (Chinese), with pseudo ground truth generated via PaddleOCR. Half are in Chinese, half in English. Text is processed by either flattening content in reading order or cropping text regions into image slices, yielding an additional 1 million slice-type pairs.
- Document-level OCR data includes 1.2 million full-page PDF-image pairs and 0.8 million image slices extracted from Common Crawl PDFs using Fitz, with slices cropped using parsed bounding boxes at line and paragraph levels.
- In joint training, 80% of the 3.2.2 data is used as plain OCR data, augmented with handwritten text from CASIA-HWDB2 (Chinese), IAM (English), and NorHand-v3 (Norwegian). Line-level handwritten samples are grouped and pasted onto blank pages to simulate long-text recognition.
- Mathpix-markdown formatted data includes: 1 million math formula pairs rendered from LaTeX via Mathpix-markdown-it and Chrome-driver; 1 million molecular formula pairs from ChEMBL_25 using Mathpix-markdown-it and rdkit.Chem; 0.3 million table pairs rendered with LaTeX; and 1 million full-page pairs (0.5M English from Nougat, 0.5M Chinese from Vary, plus 0.2M in-house labeled data).
- General OCR data includes 0.5 million sheet music samples from GrandStaff, re-rendered with Verovio using varied backgrounds and metadata; 1 million geometric shape pairs generated using TikZ commands for basic shapes and curves; and 2 million chart data pairs (1M from Matplotlib, 1M from Pyecharts), with randomized text and values from open-access corpora.
- Fine-grained OCR data (600k samples) is sourced from RCTW, ReCTS, ShopSign, and COCO-Text for natural scenes, and from parsed PDFs for document-level tasks. Coordinates are normalized and scaled by 1000x; color-guided samples use red, green, and blue bounding boxes.
- Ultra-large-image OCR data (500k pairs) is generated by stitching single-page PDFs horizontally or vertically, using InternVL-1.5’s tiling method with up to 12 tiles, enabling 1024×1024 sliding window processing.
- Multi-page OCR data (200k pairs) is created by randomly sampling 2–8 pages from Mathpix-formatted PDFs, ensuring each page has under 650 tokens and total length under 8K tokens, with mixed Chinese and English content.
- The model is trained using a mixture of data subsets, with varying ratios tailored to each training stage. Data is processed with consistent formatting, including image cropping, coordinate normalization, and metadata construction for region- and color-guided tasks.
- For evaluation, a 400-image benchmark (200 Chinese, 200 English) is manually corrected, with character-level metrics used due to short text lengths.
Method
The authors leverage a three-stage training framework to develop the General OCR Theory (OCR-2.0) model, referred to as GOT. The overall architecture of GOT consists of three primary components: a vision encoder, a linear layer, and an output decoder. The linear layer serves as a connector, mapping the channel dimension between the vision encoder and the language decoder. The framework is designed to progressively build and refine the model's capabilities across distinct training phases.
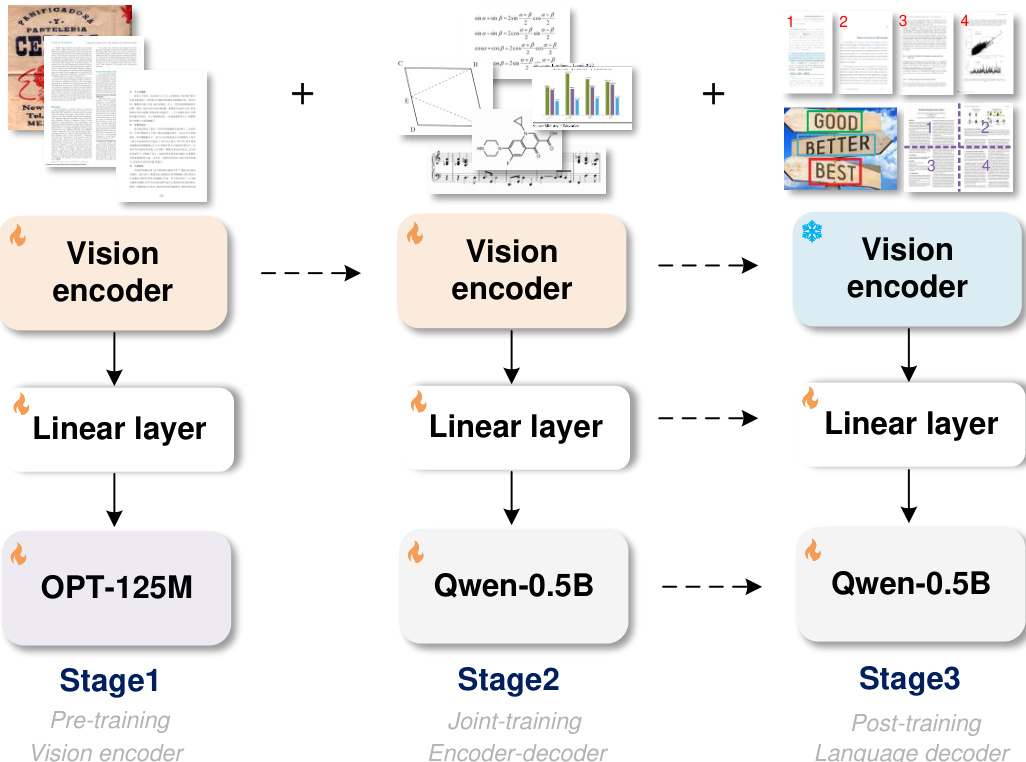
As shown in the figure below, the first stage focuses on pre-training the vision encoder. In this phase, a small decoder, specifically OPT-125M, is used to pass gradients back to the encoder, which enhances training efficiency and conserves GPU resources. The vision encoder is trained on a diverse set of images, including scene texts and document-level characters, to ensure it acquires the necessary encoding capabilities for both common text recognition tasks. This stage establishes a robust foundation for the encoder's ability to process various visual inputs.

In the second stage, the pre-trained vision encoder is integrated with a larger decoder, Qwen-0.5B, to form the complete GOT architecture. This stage involves scaling up the model's knowledge by utilizing a broader range of OCR-2.0 data, such as sheet music, mathematical and molecular formulas, and geometric shapes. This expansion allows the model to handle a wider variety of optical character recognition tasks, enhancing its generalization capabilities.
The final stage is dedicated to post-training the decoder to customize the model for new features. This process does not require modifications to the vision encoder. Instead, fine-grained and multi-crop/page synthetic data are generated and incorporated to enable advanced functionalities like region prompt OCR, huge image OCR, and batched PDF OCR. This approach allows the model to be tailored to specific user needs without retraining the entire system, making it highly adaptable and efficient.
Experiment
- Conducted three-stage training on 8×8 L40s GPUs: pre-training (3 epochs, batch size 128, learning rate 1e-4), joint-training (1 epoch, max token length 6000), and post-training (1 epoch, max token length 8192, learning rate 2e-5), with 80% data retention from prior stages to preserve performance.
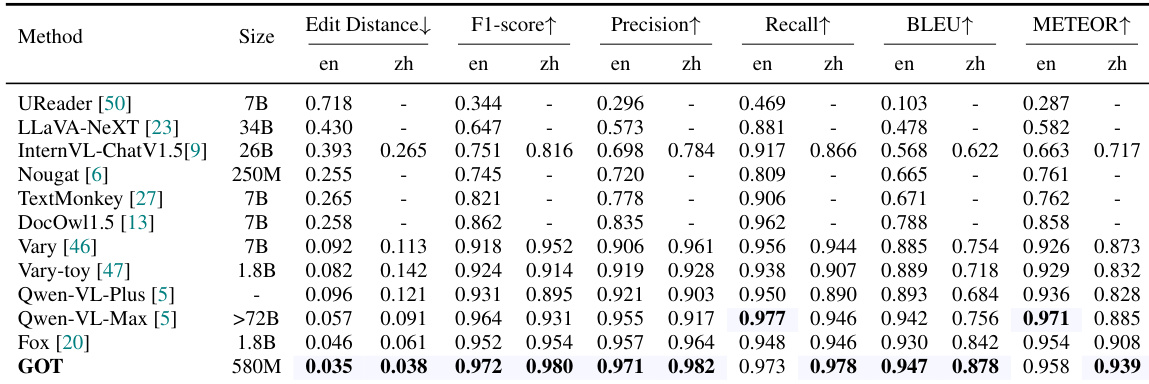
- Achieved state-of-the-art results on document-level OCR for both English and Chinese, outperforming prior models on the Fox benchmark with 580M parameters, as shown in Table 1.
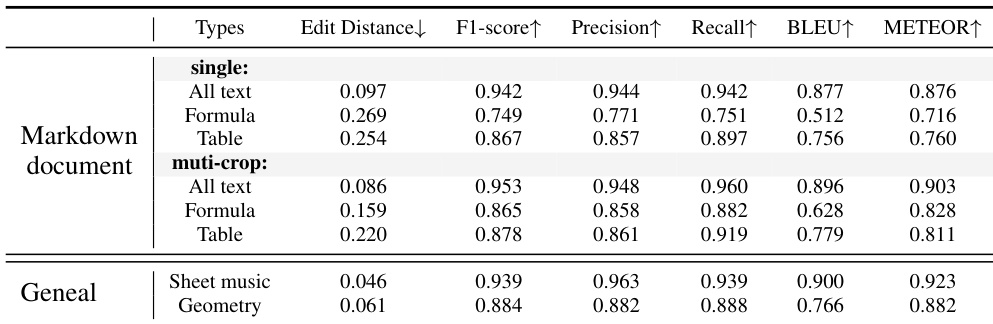
- Demonstrated strong performance on plain document OCR (Table 1), scene text OCR (Table 2), and formatted document OCR (Table 3), with multi-crop inference significantly improving results on small text, formulas, and tables.
- Excelled in fine-grained OCR tasks, surpassing Fox on both bounding box-based and color-based referential OCR, indicating robust interactive OCR capabilities (Table 4).
- Achieved superior performance on general OCR tasks, including sheet music, geometry, and charts, with chart OCR results exceeding those of specialized models and popular LVLMs (Table 5).
- Validated dynamic resolution and multi-page OCR capabilities, enabling effective processing of high-resolution and multi-page documents, as illustrated in Figures 7 and 8.
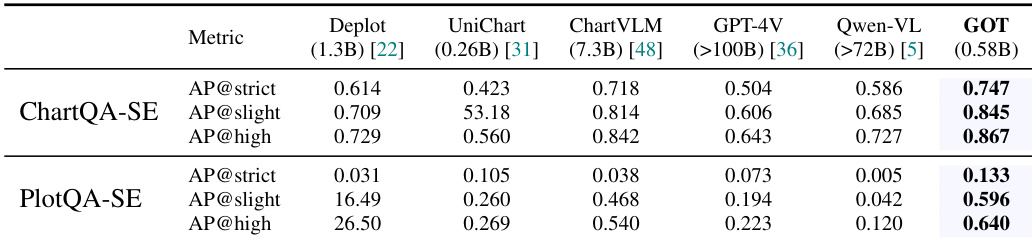
Results show that GOT achieves the highest performance on both ChartQA-SE and PlotQA-SE benchmarks, outperforming all compared models across all metrics. The model's superior results on ChartQA-SE, particularly in AP@high, indicate strong capabilities in structured chart understanding, while its competitive performance on PlotQA-SE demonstrates effectiveness in general chart OCR tasks.
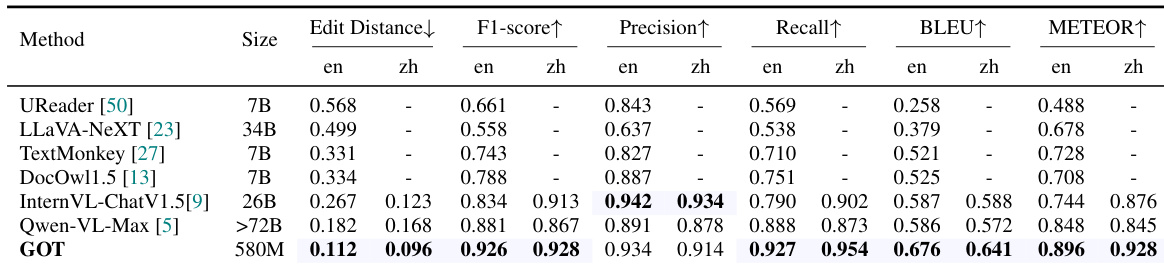
Results show that GOT achieves state-of-the-art performance on document-level OCR tasks, outperforming all baseline models across multiple metrics including F1-score, precision, recall, BLEU, and METEOR for both English and Chinese text. The model's superior performance, particularly in edit distance and F1-score, demonstrates its strong capability in handling dense text and complex document layouts.
Results show that GOT achieves strong performance on formatted document OCR, with multi-crop inference significantly improving accuracy for formulas and tables compared to single-scale input. The model also demonstrates robust capabilities on general OCR tasks, excelling in sheet music and geometry recognition.
Results show that GOT achieves state-of-the-art performance on document-level OCR tasks, outperforming all compared models in both English and Chinese text recognition across multiple metrics including F1-score, precision, recall, BLEU, and METEOR. The model's superior performance, particularly in edit distance and F1-score, demonstrates its strong capability in handling dense text and complex document layouts.
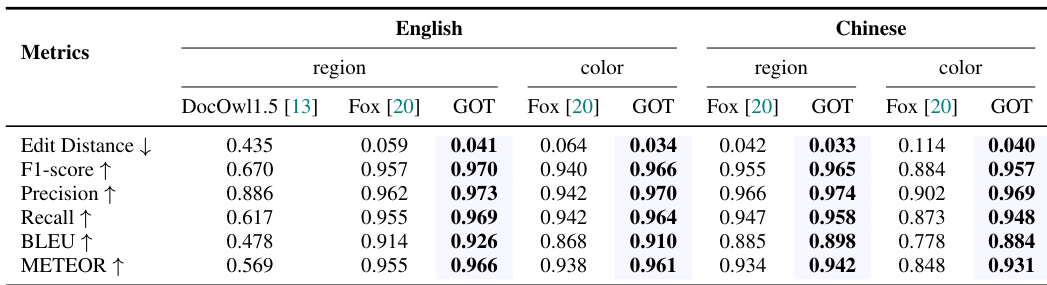
Results show that GOT achieves superior performance compared to Fox [20] across multiple metrics for both English and Chinese document OCR tasks. In particular, GOT outperforms Fox on F1-score, precision, recall, BLEU, and METEOR for English region and color tasks, and on F1-score, precision, recall, BLEU, and METEOR for Chinese region and color tasks, demonstrating strong text recognition and understanding capabilities.