Command Palette
Search for a command to run...
Skalierung auf Exzellenz: Modellskalierung für die photo-realistische Bildrekonstruktion in der Wildnis
Skalierung auf Exzellenz: Modellskalierung für die photo-realistische Bildrekonstruktion in der Wildnis
Fanghua Yu Jinjin Gu Zheyuan Li Jinfan Hu Xiangtao Kong Xintao Wang Jingwen He Yu Qiao Chao Dong
Zusammenfassung
Wir stellen SUPIR (Scaling-UP Image Restoration) vor, eine bahnbrechende Methode zur Bildrestaurierung, die generative Prior-Wissen und die Kraft der Modellvergrößerung nutzt. Durch die Kombination multimodaler Techniken und fortschrittlicher generativer Prior-Informationen stellt SUPIR einen bedeutenden Fortschritt im Bereich der intelligenten und realistischen Bildrestaurierung dar. Als zentraler Treiber innerhalb von SUPIR ermöglicht die Modellvergrößerung eine erhebliche Steigerung der Leistungsfähigkeit und eröffnet neue Perspektiven für die Bildrestaurierung. Wir haben eine Datensammlung mit 20 Millionen hochauflösenden, hochwertigen Bildern für das Modelltraining zusammengestellt, wobei jedes Bild durch deskriptive Textannotationen angereichert ist. SUPIR verfügt über die Fähigkeit, Bilder anhand von Textprompten zu restaurieren, was ihren Anwendungsbereich und ihr Potenzial erheblich erweitert. Darüber hinaus führen wir negative Qualitäts-Prompts ein, um die wahrnehmbare Bildqualität weiter zu verbessern. Zudem entwickeln wir eine auf der Restaurierung basierende Sampling-Methode, um das Problem der Fidelity-Verzerrung bei generativen Restaurierungsansätzen zu reduzieren. Experimente belegen die herausragenden Restaurierungsergebnisse von SUPIR sowie ihre innovative Fähigkeit, die Restaurierung durch textbasierte Eingaben gezielt zu steuern.
One-sentence Summary
The authors from Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, Shanghai AI Laboratory, The Hong Kong Polytechnic University, ARC Lab, Tencent PCG, and The Chinese University of Hong Kong propose SUPIR, a scalable generative image restoration model that leverages a 20M-image dataset with text annotations to enable controllable restoration via textual prompts, including negative-quality prompts and restoration-guided sampling, significantly improving perceptual quality and semantic fidelity over prior methods.
Key Contributions
-
SUPIR introduces a large-scale image restoration framework that leverages a 2.6-billion-parameter Stable Diffusion XL (SDXL) model as a generative prior, combined with a novel ZeroSFT connector and a 13-billion-parameter multi-modal language model, enabling highly realistic and intelligent restoration across diverse degradation types without relying on specific degradation assumptions.
-
The method is trained on a newly collected dataset of 20 million high-resolution, high-quality images with detailed text annotations, and incorporates negative-quality prompts and a restoration-guided sampling strategy to enhance perceptual quality while preserving input fidelity, addressing key challenges in generative-based restoration.
-
SUPIR achieves state-of-the-art performance in real-world image restoration, demonstrating superior visual quality and controllability through textual prompts—enabling fine-grained manipulation such as material specification, semantic adjustment, and object restoration—validated through extensive experiments on complex, real-world degradation scenarios.
Introduction
The authors leverage large-scale generative models and model scaling to advance photo-realistic image restoration in real-world scenarios, where images suffer from diverse, complex degradations. Prior methods often rely on task-specific assumptions or limited generative priors, restricting their generalization and perceptual quality. Scaling up such models has been hindered by engineering challenges, including computational costs, architectural incompatibility, and fidelity loss due to uncontrolled generation. To overcome these, the authors introduce SUPIR, a scalable image restoration framework built on Stable Diffusion XL with a novel ZeroSFT connector that enables efficient adaptation without full fine-tuning. They train the model on a 20-million-image dataset with rich text annotations and employ a 13-billion-parameter multi-modal model for accurate prompt generation. Key innovations include negative-quality prompts to guide perceptual quality and a restoration-guided sampling strategy to preserve input fidelity. The result is a highly controllable, state-of-the-art restoration system capable of semantic-aware, text-driven image enhancement.
Dataset
- The dataset consists of 20 million high-resolution 1024×1024 images sourced from a custom collection, selected for high quality and texture richness, addressing the lack of large-scale, high-quality image datasets for image restoration (IR).
- An additional 70,000 unaligned high-resolution facial images from the FFHQ-raw dataset are included to enhance the model’s face restoration capabilities.
- The dataset is used for training with a mixture of data from the custom collection and FFHQ-raw, with the custom images forming the primary training split.
- Textual annotations are collected for all training images to support multi-modal language guidance, enabling the model to use textual prompts during both training and inference.
- A novel strategy involves generating 100,000 low-quality images using SDXL based on negative-quality prompts (e.g., "blur", "low resolution", "dirty") and adding them to the training data to improve the model’s ability to interpret and respond to negative prompts during classifier-free guidance (CFG).
- During training, the model leverages a modified SDXL architecture with a trimmed encoder copy and a ZeroSFT connector for efficient and effective feature fusion.
- Image processing includes degradation-robust encoding of low-quality inputs using a dedicated encoder Edr, followed by a degradation model D to prepare inputs for the LLaVA multi-modal LLM, which generates textual descriptions used as prompts.
- The training process incorporates both positive and negative prompts during CFG, with the model trained to balance these signals, ensuring improved perceptual quality and reduced artifacts.
Method
The authors leverage the SDXL model as a generative prior for image restoration, selecting its Base model due to its direct high-resolution generation capability and suitability for training on high-quality datasets. This choice avoids the redundancy of SDXL's Base-Refine strategy, which is less effective when the goal is to enhance image quality rather than interpret text. To effectively integrate low-quality (LQ) inputs, the framework employs a degradation-robust encoder that is fine-tuned to map LQ images into the same latent space as the pre-trained SDXL model. This fine-tuning process minimizes the discrepancy between the decoded outputs of the degraded and ground truth images, ensuring that the encoder accurately represents the content of the LQ input without misinterpreting artifacts as meaningful features.

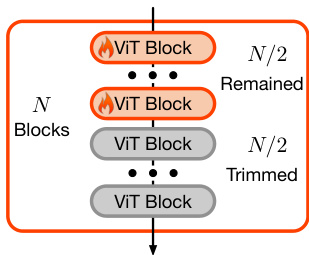
The core adaptation mechanism is implemented through a novel adaptor, referred to as Trimmed ControlNet, which is designed to guide the SDXL model in restoring images based on the provided LQ input. This adaptor is built upon the ControlNet architecture but is engineered for scalability and efficiency. The authors achieve this by trimming half of the Vision Transformer (ViT) blocks within each encoder block of the trainable copy, as shown in the figure below. This trimming strategy maintains the essential characteristics of ControlNet—large network capacity and effective initialization—while making the model feasible for the scale of SDXL. The adaptor is trained to identify the content of the LQ image and exert fine-grained control over the generation process at the pixel level.
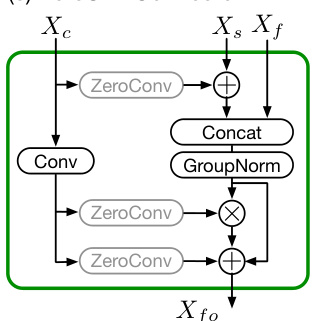
To further enhance the influence of the LQ guidance, the authors redesign the connector between the adaptor and the SDXL model. This new connector, named ZeroSFT, is an extension of the zero convolution operation. It incorporates an additional spatial feature transfer (SFT) operation and group normalization, allowing for more effective modulation of the diffusion process. The ZeroSFT module processes the latent representation of the LQ image and the current diffusion step's latent state, producing a refined guidance signal that is integrated into the generation process.
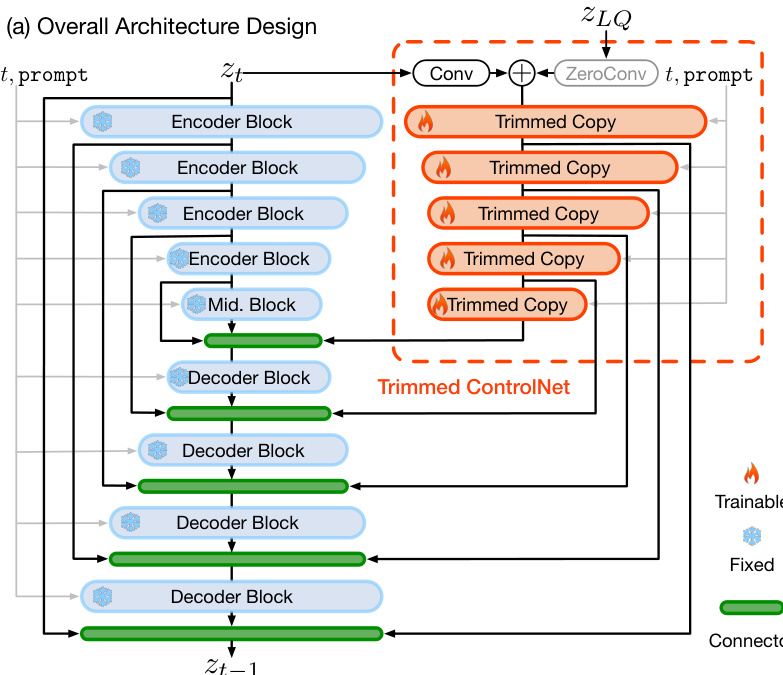
The overall framework, as illustrated in the figure below, integrates these components into a coherent system. The low-quality image is first encoded by the degradation-robust encoder into a latent representation zLQ. This latent representation, along with a text prompt generated by a multi-modal large language model, is fed into the Trimmed ControlNet. The control signal is then used to guide the pre-trained SDXL model through a diffusion process, which is sampled using a restoration-guided method. This method modifies the EDM sampling algorithm to selectively guide the prediction results towards the LQ latent representation in the early stages of diffusion, ensuring fidelity to the input, while allowing for the generation of high-frequency details in later stages.
Experiment
- Trained on 20M high-quality image-text pairs, 70K face images, and 100K negative-quality samples using a synthetic degradation model; achieved high-fidelity restoration on 1024×1024 images with a batch size of 256 across 64 A6000 GPUs over 10 days.
- On synthetic data, outperformed state-of-the-art methods (BSRGAN, Real-ESRGAN, StableSR, DiffBIR, PASD) in non-reference metrics (ManIQA, ClipIQA, MUSIQ), demonstrating superior perceptual quality despite lower PSNR/SSIM, highlighting the misalignment between metrics and human evaluation.
- On 60 real-world LQ images, achieved the highest perceptual quality in user studies with 20 participants, significantly outperforming existing methods, and maintained structural fidelity in complex scenes such as buildings and natural landscapes.
- Ablation studies confirmed the effectiveness of the proposed ZeroSFT connector over zero convolution, showing improved fidelity without sacrificing perceptual quality; training on large-scale data was critical for high-quality restoration.
- Restoration-guided sampling with τ_r = 4 balanced fidelity and perceptual quality, while negative-quality prompts and training samples significantly enhanced output quality and reduced artifacts.
- Degradation-robust encoder effectively reduced noise and blur in low-quality inputs, preventing generative models from misinterpreting artifacts as content.
- Text prompts enabled controllable restoration, allowing accurate reconstruction of missing details (e.g., bike parts, hat texture) and semantic manipulation (e.g., face attributes), though ineffective when prompts contradicted input content.
The authors compare the proposed ZeroSFT connector with zero convolution, showing that ZeroSFT achieves higher performance across all metrics, particularly in full-reference metrics like PSNR and SSIM, while maintaining strong non-reference metric scores. This indicates that ZeroSFT better preserves image fidelity without sacrificing perceptual quality compared to zero convolution.

Results show that the proposed method achieves the best performance on non-reference metrics such as ManIQA, ClipIQA, and MUSIQ across all degradation types, indicating superior perceptual quality. While it performs competitively on full-reference metrics like PSNR and SSIM, it does not consistently outperform other methods, highlighting a trade-off between fidelity and perceptual realism.
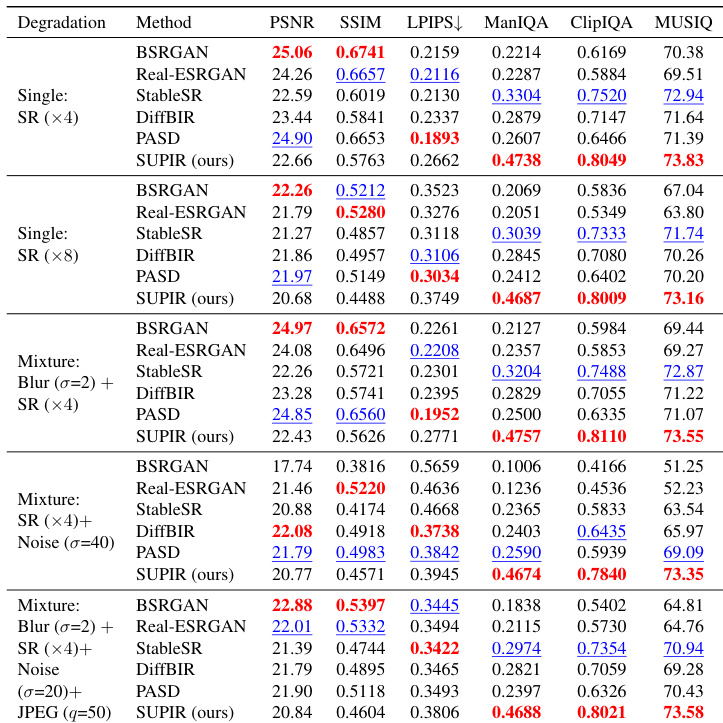
Results show that the proposed method achieves the best performance on non-reference metrics CLIP-IQA, MUSIQ, and MANIQA, outperforming all compared methods. It also achieves the second-best result on PASD, while Real-ESRGAN and StableSR perform better on full-reference metrics like PSNR and SSIM, highlighting a trade-off between perceptual quality and traditional metric scores.

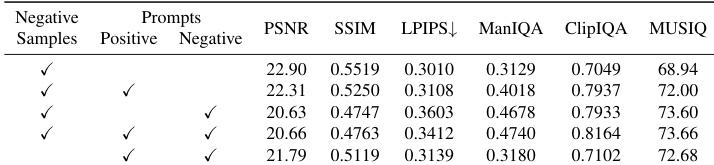
The authors conduct an ablation study to evaluate the impact of negative samples, positive prompts, and negative prompts on image restoration quality. Results show that using negative samples is essential for enabling effective prompt-based improvements, as their absence prevents positive and negative prompts from enhancing perceptual quality. When all three components are used together, the method achieves the best performance across all metrics, particularly in non-reference metrics like ManIQA, ClipIQA, and MUSIQ, indicating superior perceptual quality.