Command Palette
Search for a command to run...
Masked Audio Generation mit einem einzigen nicht-autoregressiven Transformer
Masked Audio Generation mit einem einzigen nicht-autoregressiven Transformer
Alon Ziv Itai Gat Gael Le Lan Tal Remez Felix Kreuk Alexandre Défossez Jade Copet Gabriel Synnaeve Yossi Adi
Zusammenfassung
Wir stellen MAGNeT vor, eine maskierte generative Sequenzmodellierungsmethode, die direkt über mehrere Audio-Token-Ströme operiert. Im Gegensatz zu vorherigen Ansätzen besteht MAGNeT aus einem einstufigen, nicht-autoregressiven Transformer. Während des Trainings prognostizieren wir kontinuierliche Abschnitte maskierter Token, die durch einen Maskierungs-Scheduler generiert werden, während wir während der Inferenz die Ausgabesequenz schrittweise durch mehrere Decodierungsstufen aufbauen. Um die Qualität der generierten Audio-Dateien weiter zu verbessern, führen wir eine neuartige Rescoring-Methode ein, bei der wir ein extern vortrainiertes Modell nutzen, um die Vorhersagen von MAGNeT neu zu bewerten und zu sortieren, welche dann für spätere Decodierungsstufen verwendet werden. Zudem untersuchen wir eine hybride Variante von MAGNeT, bei der wir autoregressive und nicht-autoregressive Modelle kombinieren, um die ersten Sekunden autoregressiv zu generieren, während der Rest der Sequenz parallel decodiert wird. Wir demonstrieren die Effizienz von MAGNeT für die Aufgaben der Text-zu-Musik- und Text-zu-Audio-Generierung und führen eine umfassende empirische Evaluation durch, die sowohl objektive Metriken als auch menschliche Studien einbezieht. Der vorgeschlagene Ansatz ist mit den verglichenen Baselines vergleichbar, ist jedoch deutlich schneller (x7 schneller als die autoregressive Basislinie). Durch Ablation-Studien und Analysen beleuchten wir die Bedeutung jedes einzelnen Komponenten von MAGNeT und verdeutlichen die Trade-offs zwischen autoregressiver und nicht-autoregressiver Modellierung im Hinblick auf Latenz, Durchsatz und Generierungsqualität. Beispiele sind auf unserer Demo-Seite verfügbar unter: https://pages.cs.huji.ac.il/adiyoss-lab/MAGNeT.
One-sentence Summary
The authors from Meta FAIR, Kyutai, and The Hebrew University of Jerusalem propose MAGNET, a single-stage non-autoregressive transformer for text-to-music and text-to-audio generation that uses masked token prediction and a novel rescoring mechanism with an external pretrained model, achieving up to 7× faster inference than autoregressive baselines while maintaining competitive quality, with a hybrid variant enabling early autoregressive refinement for improved coherence.
Key Contributions
- MAGNET introduces a single-stage, non-autoregressive transformer model that generates audio directly from multi-stream discrete tokens by predicting masked spans during training and iteratively refining the output during inference, enabling faster generation compared to autoregressive baselines while maintaining high quality.
- The method incorporates a novel rescoring mechanism that leverages an external pretrained model to rank and refine MAGNET's predictions, significantly improving audio quality without increasing latency during inference.
- A hybrid variant of MAGNET combines autoregressive and non-autoregressive decoding—generating the initial segment autoregressively and the remainder in parallel—achieving a balance between quality, latency, and throughput, with evaluations showing x7 faster inference than autoregressive models on text-to-music and text-to-audio tasks.
Introduction
The authors leverage recent advances in self-supervised audio representation learning and sequence modeling to address the challenge of high-quality, low-latency conditional audio generation—critical for interactive applications like music creation in digital audio workstations. Prior work relies on either autoregressive models, which suffer from high inference latency due to sequential token generation, or diffusion models, which require hundreds of steps for high fidelity and struggle with long-form audio synthesis. The authors introduce MAGNET, a single non-autoregressive Transformer model that generates audio by iteratively predicting masked spans of a multi-stream discrete representation, enabling parallel decoding and significantly faster inference. Their key contributions include a novel masked generative framework that achieves 30-second audio generation with up to 7× speedup over autoregressive baselines, a rescoring method using an external pre-trained model to enhance quality, and a hybrid variant that combines autoregressive and non-autoregressive decoding for improved performance.
Dataset
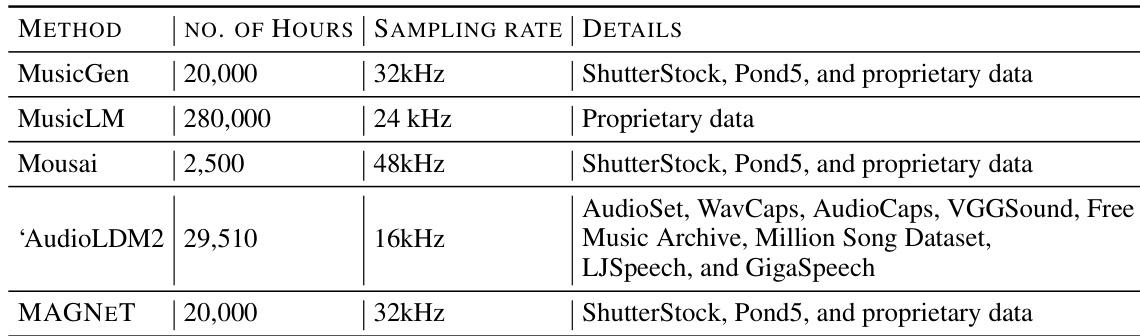
- The dataset comprises 20K hours of licensed music, following the setup from Copet et al. (2023), and is used to train the MAGNET model.
- It includes three main sources:
- 10K high-quality music tracks from a curated collection.
- 25K instrument-only tracks from Shutterstock.
- 365K instrument-only tracks from Pond5.
- All tracks are full-length, sampled at 32 kHz, and come with metadata including textual descriptions, genre, BPM, and tags.
- For evaluation, the authors use the MusicCaps benchmark, which contains 5.5K ten-second samples created by expert musicians, along with a 1K genre-balanced subset.
- Objective metrics are reported on the unbalanced MusicCaps set, while qualitative evaluations use samples from the genre-balanced subset.
- Ablation studies are conducted on the in-domain test set used by Copet et al. (2023).
- The training data is processed to ensure consistent audio format and metadata structure, with no explicit cropping mentioned—full-length tracks are used as-is.
- The model is trained using a mixture of the three data sources, with training split ratios aligned to the original setup in Copet et al. (2023).
Method
The authors leverage a non-autoregressive transformer architecture for audio generation, conditioned on a semantic representation of the input text. The model operates directly on discrete audio tokens obtained from the EnCodec tokenizer, which produces multiple parallel streams of tokens via Residual Vector Quantization (RVQ). Each stream corresponds to a codebook, with the first codebook capturing coarse audio features and subsequent codebooks refining the signal by encoding quantization errors. The core framework of MAGNET is designed to generate these token sequences in a single-stage, non-autoregressive manner, enabling faster inference compared to traditional autoregressive models.
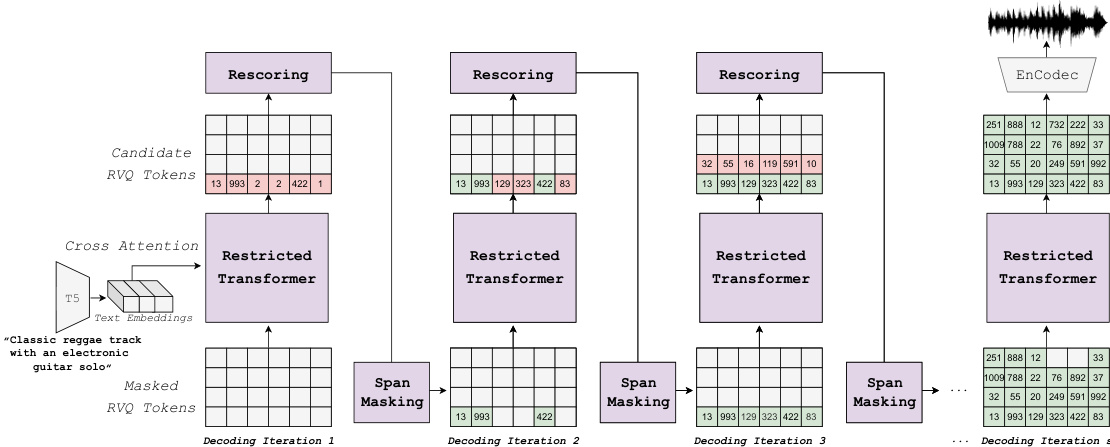
The overall framework, as illustrated in the figure above, consists of iterative decoding steps where the model progressively refines a partially generated sequence. The process begins with a fully masked sequence of tokens. At each decoding iteration, a subset of token spans is masked based on a predefined masking scheduler. The model then predicts the tokens at the masked positions using a restricted transformer architecture. To enhance the quality of the generated audio, a novel rescoring mechanism is employed, where an external pretrained model evaluates and ranks the candidate predictions. The final token selection is based on a convex combination of the model's confidence and the rescoring model's probabilities. This process repeats for a fixed number of decoding steps, gradually constructing the output sequence.
A key innovation in MAGNET is its masking strategy, which operates on spans of tokens rather than individual tokens. This design choice addresses the issue of information leakage between adjacent tokens due to the receptive field of the audio encoder. The authors evaluate various span lengths and find that a 60ms span length yields optimal performance. The masking process is carefully designed to achieve a desired masking rate by sampling a number of spans such that the expected masking rate matches the scheduler's output. During inference, the model selects the least probable spans for re-masking, which helps to focus on refining the most uncertain parts of the sequence.
To further improve model optimization, MAGNET incorporates a restricted context mechanism. Given the hierarchical nature of RVQ, where later codebooks depend heavily on earlier ones, the self-attention mechanism is constrained to attend only to tokens within a limited temporal window, approximately 200ms. This restriction is based on an analysis of the effective receptive field of the EnCodec encoder, which is found to be bounded despite the presence of an LSTM block. By limiting the context, the model can better focus on relevant information and avoid overfitting to local noise.
The inference process is further enhanced by a classifier-free guidance annealing mechanism. During training, the model is optimized both conditionally and unconditionally, and at inference time, the sampling distribution is a linear combination of these two probabilities. The guidance coefficient is annealed during the iterative decoding process, starting from a high value to ensure strong adherence to the text prompt and gradually decreasing to allow the model to focus on contextual infilling. This approach helps to balance text adherence with audio quality and stability.
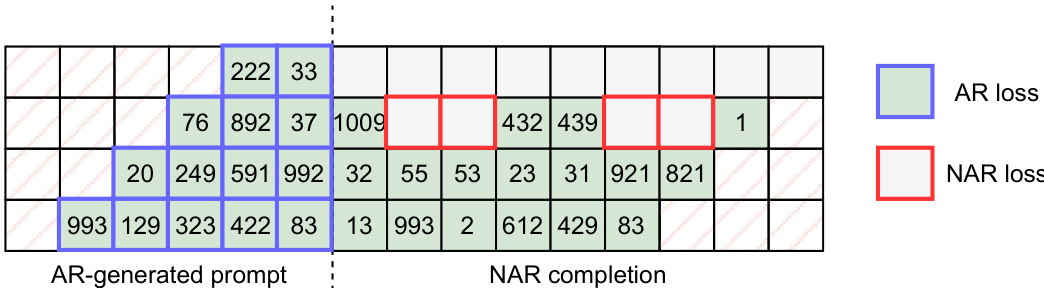
Finally, the authors explore a hybrid version of MAGNET, which combines autoregressive and non-autoregressive modeling. This hybrid approach generates the initial portion of the audio sequence in an autoregressive manner, ensuring high quality, and then switches to non-autoregressive decoding for the remainder of the sequence, achieving significant speed improvements. The training of this hybrid model involves a joint objective that incorporates both autoregressive and non-autoregressive loss functions, with the transition point determined by a randomly sampled timestep.
Experiment
- MAGNET is evaluated on text-to-music and text-to-audio generation tasks using the same training data as Copet et al. (2023) and Kreuk et al. (2022a), with EnCodec as the audio tokenizer and T5 for text conditioning.
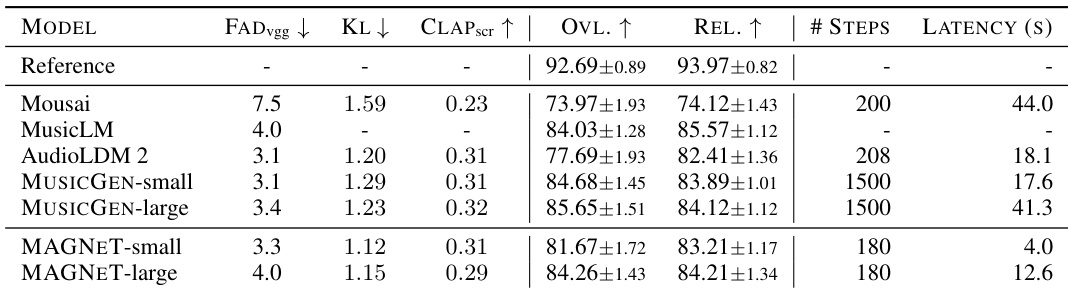
- On the MusicCaps benchmark, MAGNET-small (300M) and MAGNET-large (1.5B) achieve comparable FAD and CLAP scores to MusicGen and AudioLDM2, while being significantly faster—up to 10 times lower latency at small batch sizes.
- MAGNET achieves a 10-second generation FAD of 2.9 and CLAP score of 0.31 when trained on 30-second audio, improving with reduced sequence length.
- Hybrid-MAGNET, which combines autoregressive prompt generation with non-autoregressive completion, outperforms the full autoregressive baseline in FAD (0.61) while reducing latency from 17.6s to 3.2s.
- Ablation studies show that span masking with a span length of 3 (60ms) and temporally restricted context improve FAD, and CFG annealing (λ₀=10, λ₁=1) yields the best performance.
- Rescoring improves metrics but increases inference time, while reducing decoding steps for higher codebook levels has minimal impact on quality, enabling latency reductions to 370ms with only an 8% FAD increase.
- On AudioCaps, MAGNET achieves performance comparable to autoregressive AudioGen with significantly lower latency.
The authors use MAGNET to generate music from text, comparing it to baselines like MusicGen and AudioLDM2. Results show that MAGNET-small achieves lower FAD and CLAP scores than MusicGen-small but matches its subjective quality, while being significantly faster in latency and decoding steps.
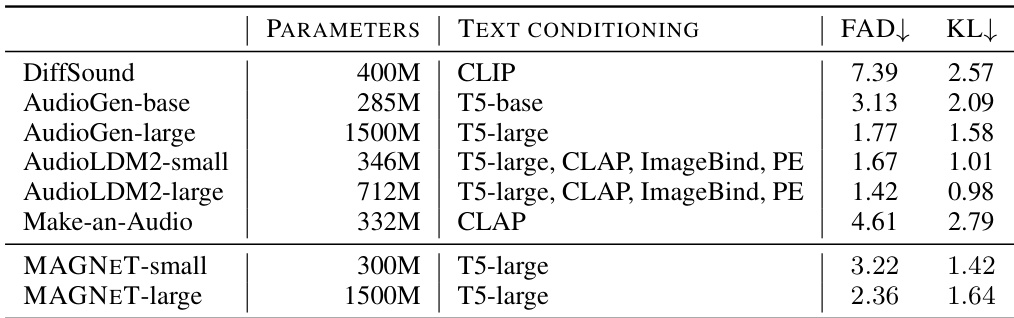
The authors use MAGNET-small and MAGNET-large models to generate music conditioned on text, achieving competitive performance compared to other text-to-music baselines. Results show that MAGNET-small and MAGNET-large achieve lower FAD and KL scores than DiffSound, AudioGen-base, and Make-an-Audio, while performing comparably to AudioLDM2-small and AudioLDM2-large, with MAGNET-large achieving the best FAD and KL scores among all models.
The authors evaluate the effect of conditional guidance (CFG) annealing on model performance, using different configurations for the guidance coefficient λ₀ and λ₁. Results show that annealing from λ₀ = 10 to λ₁ = 1 yields the best FAD score, indicating improved audio quality, while also achieving competitive KL and CLAP scores, suggesting a balance between audio-text alignment and distributional fidelity.

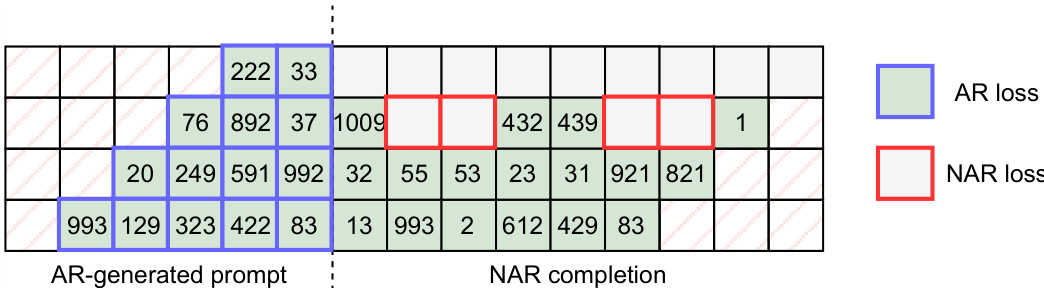
The authors use a hybrid approach where an autoregressive model generates a short audio prompt, which is then completed by a non-autoregressive model. The table illustrates this process, showing the autoregressive generation of initial tokens followed by non-autoregressive completion of the remaining sequence.
The authors use MAGNET for text-to-music generation and compare it to baselines including MusicGen, MusicLM, Mousai, and AudioLDM2, using the MusicCaps benchmark. Results show that MAGNET achieves comparable performance to MusicGen, which uses autoregressive modeling, while being significantly faster in terms of latency and decoding steps.