Command Palette
Search for a command to run...
vLLM+Open WebUI-Bereitstellung Phi-4-mini-flash-reasoning
1. Einführung in das Tutorial

Phi-4-mini-flash-reasoning ist ein schlankes Open-Source-Modell des Microsoft-Teams. Es basiert auf synthetischen Daten, konzentriert sich auf hochwertige, intensive Inferenzdaten und wurde weiter optimiert, um fortgeschrittene mathematische Schlussfolgerungsfähigkeiten zu erzielen. Dieses Modell gehört zur Phi-4-Modellfamilie, unterstützt Token-Kontextlängen von bis zu 64.000, verwendet eine Decoder-Hybrid-Decoder-Architektur und kombiniert Aufmerksamkeitsmechanismen mit einem Zustandsraummodell (SSM). Es zeichnet sich durch eine hervorragende Inferenzeffizienz aus. Zugehörige Forschungsarbeiten sind verfügbar. Decoder-Hybrid-Decoder-Architektur für effizientes Schließen mit langer Generierung .
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte. Projektaufforderungen unterstützen Chinesisch und Englisch.
2. Projektbeispiele
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
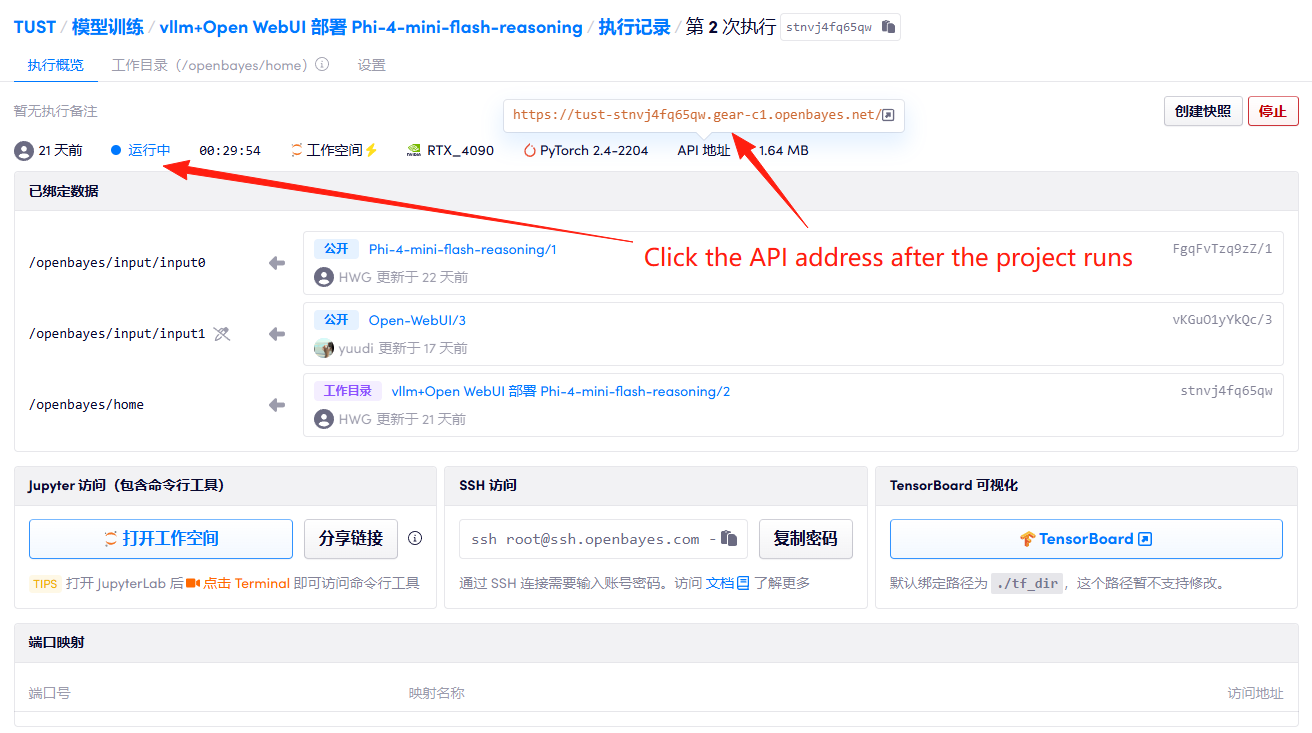
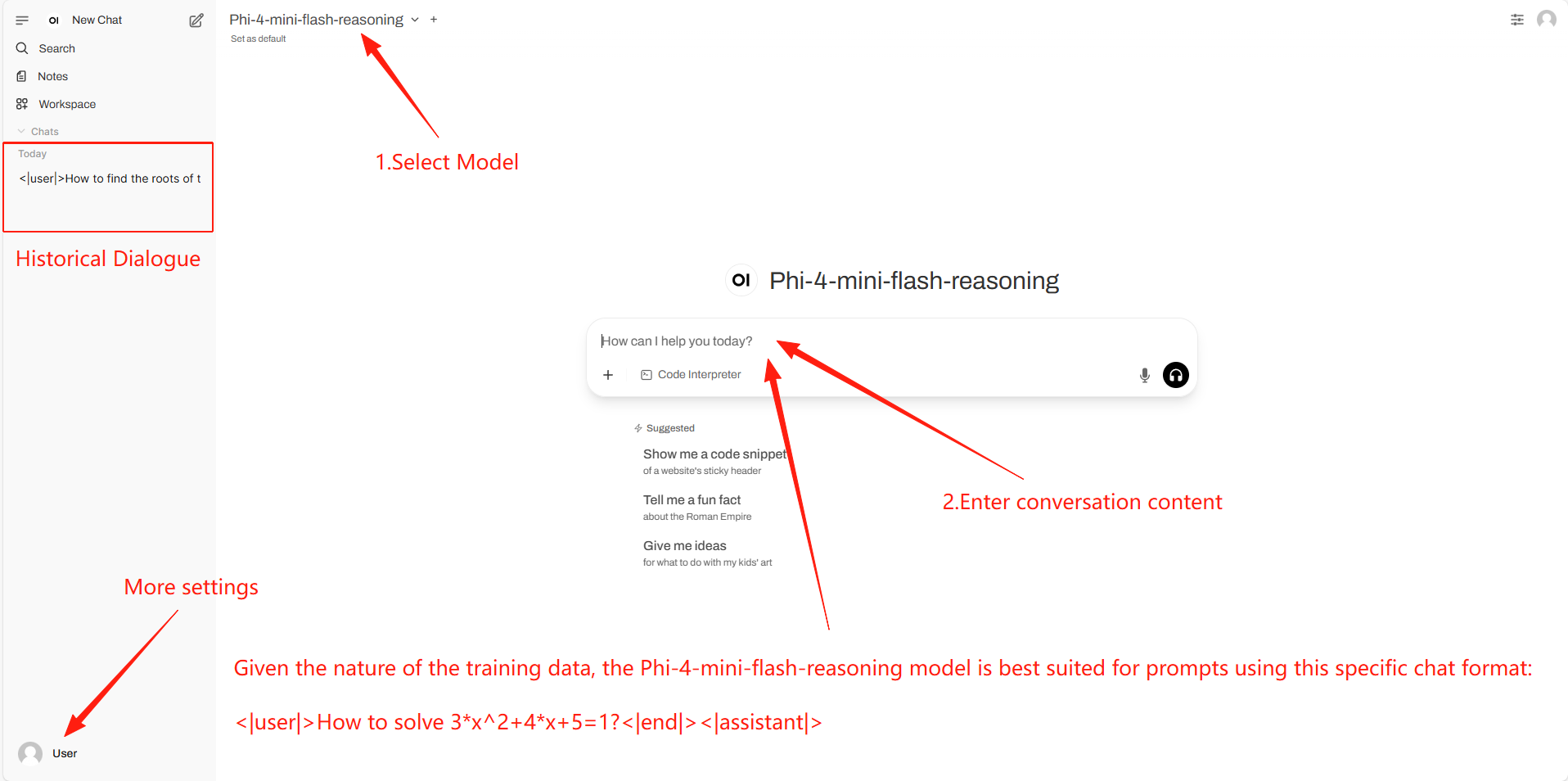
2. Anwendungsschritte
Wenn „Modell“ nicht angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–3 Minuten und aktualisieren Sie die Seite.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@software{archscale2025, title={ArchScale: Simple and Scalable Pretraining for Neural Architecture Research}, author={Liliang Ren and Zichong Li and Yelong Shen}, year={2025}, url={https://github.com/microsoft/ArchScale} }@article{ren2025decoder,
title={Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation},
author={Liliang Ren and Congcong Chen and Haoran Xu and Young Jin Kim and Adam Atkinson and Zheng Zhan and Jiankai Sun and Baolin Peng and Liyuan Liu and Shuohang Wang and Hao Cheng and Jianfeng Gao and Weizhu Chen and Yelong Shen},
journal={arXiv preprint arXiv:2507.06607},
year={2025}
}
Notebook-Übersicht
Stufe
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.