Command Palette
Search for a command to run...
Healthcare Agent Erkennt Automatisch Medizinethische Und Sicherheitsrelevante Probleme Und Seine Proaktiven Und Relevanten Konsultationen Übertreffen Closed-Source-Modelle Wie GPT-4.

In den letzten Jahren hat die Anwendung groß angelegter Sprachmodelle (LLMs) in medizinischen Konsultationen zunehmend an Bedeutung gewonnen. Im Gesundheitszentrum des Unterbezirks Zhaotan im Bezirk Yuhu der Stadt Xiangtan in der Provinz Hunan führt Hausarzt Liu Yanbo eine Nachuntersuchung bei dem 72-jährigen Diabetespatienten Wang Guihua durch. Dabei werden Medikamentenempfehlungen und Krankenaktenzusammenfassungen verwendet, die der „intelligente medizinische Assistent“ in Echtzeit generiert. Dieses „KI + Gesundheitswesen“-Anwendungsszenario ist in der primären Gesundheitsversorgung im Bezirk Yuhu zum Standard geworden. Berichten zufolge verbessert der „intelligente medizinische Assistent“ nicht nur die Qualität elektronischer Krankenakten, sondern trägt auch dazu bei, Diagnose- und Behandlungsrisiken zu senken. Seit Einführung dieser Plattform hat die regionale Standardisierungsrate für Krankenakten 96,641 TP3T erreicht und die Diagnosekonformitätsrate ist auf 96,661 TP3T gestiegen.
Jedoch,Die Anwendung des allgemeinen LLM in realen medizinischen Szenarien ist häufig mit vielfältigen Herausforderungen verbunden.Beispielsweise sind KI-Modelle nicht nur nicht in der Lage, Patienten Schritt für Schritt bei der Darstellung ihres Zustands und der damit verbundenen Informationen effektiv anzuleiten, sondern verfügen auch nicht über die notwendigen Strategien und Sicherheitsvorkehrungen, um Fragen der medizinischen Ethik und Sicherheit zu bewältigen, und sind auch nicht in der Lage, Konsultationsgespräche zu speichern und Krankengeschichten abzurufen.
Als Reaktion darauf haben einige Forschungsteams versucht, medizinische LLMs von Grund auf neu zu entwickeln oder allgemeine LLMs mithilfe spezifischer Datensätze zu optimieren, um solche Probleme zu lösen. Dieser einmalige Prozess ist jedoch nicht nur rechenintensiv, sondern weist auch nicht die für praktische Szenarien erforderliche Flexibilität und Anpassungsfähigkeit auf.Agenten können Aufgaben ohne erneute Schulung in überschaubare Teile zerlegen und so besser für komplexe Aufgaben geeignet sein.
In diesem ZusammenhangForschungsteams der Universität Wuhan und der Technischen Universität Nanyang haben gemeinsam einen Gesundheitsagenten entwickelt, der aus drei Komponenten besteht: Dialog, Gedächtnis und Verarbeitung. Er kann die medizinischen Zwecke von Patienten erkennen und automatisch medizinethische und sicherheitsrelevante Probleme aufdecken.Während medizinisches Personal mitten im Satz eingreifen kann, können Benutzer über Healthcare Agent auch schnell Konsultationszusammenfassungen abrufen. Healthcare Agent erweitert die Möglichkeiten von LLM in der medizinischen Konsultation erheblich und bietet ein neues Paradigma für dessen Anwendung im Gesundheitswesen.
Die entsprechenden Forschungsergebnisse wurden in Nature Artificial Intelligence unter dem Titel „Healthcare agent: eliciting the power of large language models for medical consultation“ veröffentlicht.
Forschungshighlights:
* Schlägt drei Hauptkomponenten vor: Dialog, Gedächtnis und Verarbeitung, die die medizinischen Beratungsfähigkeiten von LLM ohne Schulung verbessern und Multitasking und sichere Interaktion unterstützen können;
* Aufbau eines Mechanismus zur Gewährleistung von Sicherheit und Ethik, um ethische Risiken, Notfallrisiken und Fehlerrisiken durch eine „Diskutieren-Überarbeiten“-Strategie zu erkennen;
* Kombinieren Sie aktuelle Gesprächsspeicher mit historischen Konsultationszusammenfassungen, um Informationsduplizierung zu vermeiden, die Konsultationskontinuität und die Effizienz der personalisierten Betreuung zu verbessern;
* Verwenden Sie ChatGPT, um virtuelle Patienten zu simulieren und ein automatisiertes Bewertungssystem zu entwickeln, um Modelle basierend auf realen Daten effizient zu testen und die Kosten für manuelle Bewertungen zu senken.
Papieradresse:
https://go.hyper.ai/09lYX
Folgen Sie dem offiziellen Konto und antworten Sie mit „Healthcare Agent“, um das vollständige PDF zu erhalten
Weitere Artikel zu den Grenzen der KI:
Sichten Sie hochwertige Stichproben aus dem Datensatz und erstellen Sie Patientenporträts auf der Grundlage echter Gespräche
Die Studie verwendete MedDialog-Datensatz zum Erstellen und Bewerten von Healthcare Agent.Die Forscher wählten aus dem Datensatz mit über 40 Gesprächsrunden Beispiele aus und erstellten Patientenvignetten auf Grundlage dieser realen Gespräche. Der MedDialog-Datensatz umfasst eine umfangreiche Sammlung realer Arzt-Patienten-Gespräche aus 20 verschiedenen medizinischen Fachgebieten, darunter Onkologie, Psychiatrie und Hals-Nasen-Ohrenheilkunde, und gewährleistet so eine vielfältige und umfassende experimentelle Landschaft. Der Datensatz besteht aus drei Hauptkomponenten: * einer grundlegenden Beschreibung des Patientenzustands; * einer vollständigen Abschrift mehrerer Arzt-Patienten-Gespräche; und * der endgültigen Diagnose und den Behandlungsempfehlungen des medizinischen Personals.
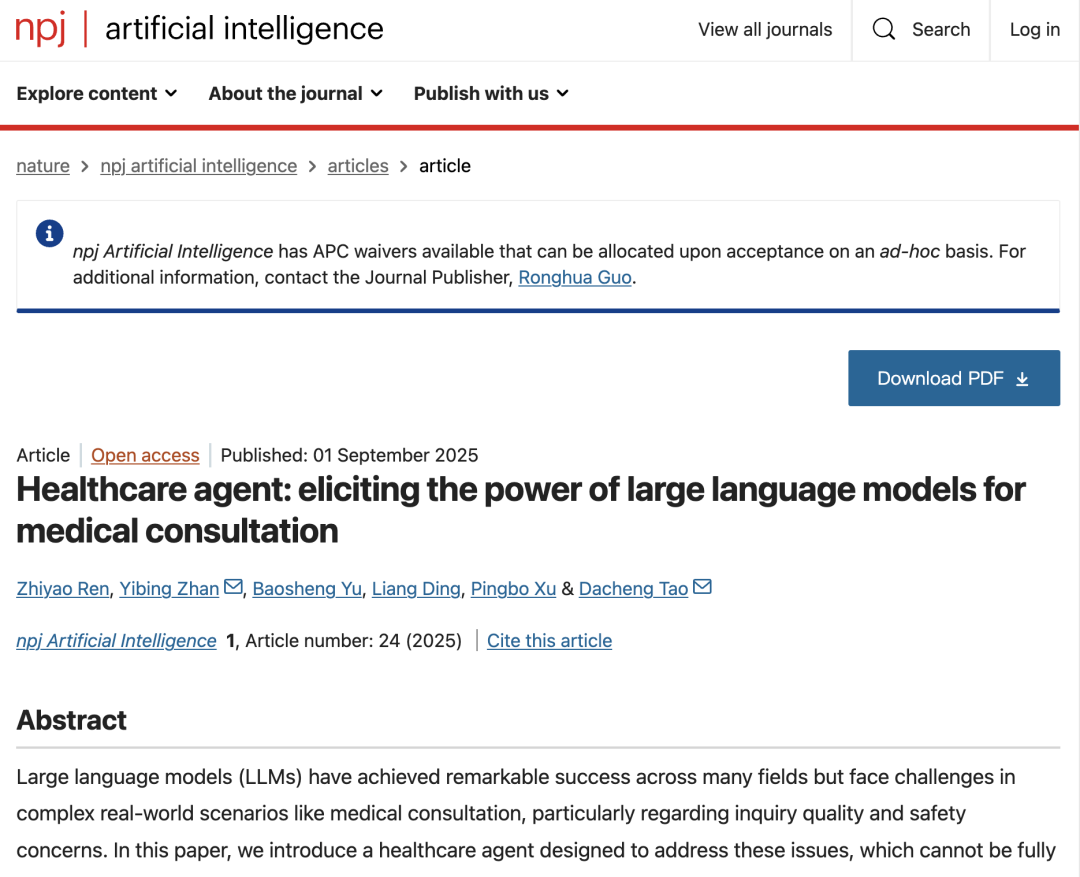
Kernkomponenten und Modellarchitektur des Healthcare Agent
Die Kernarchitektur des Healthcare Agent besteht aus drei eng aufeinander abgestimmten Komponenten: Dialog, Speicher und Verarbeitung:
* Dialogkomponente:Verantwortlich für die Interaktion mit Patienten. Seine internen Funktionsmodule können anhand der Patienteneingaben automatisch den aktuellen Aufgabentyp bestimmen. Wenn die Patienteninformationen nicht ausreichen, kann das Planungsmodul das Abfragemodul aufrufen, um den Patienten durch gezielte Befragung bei der Ergänzung wichtiger Symptome und der Krankengeschichte zu unterstützen. Nach Abschluss der Informationssammlung kann das System eine vorläufige Diagnose, eine Erklärung der Krankheitsursache oder Behandlungsempfehlungen bereitstellen.
* Speicherkomponente:Das System besteht aus einem Gesprächs- und einem Verlaufsspeicher und kann den Kontext des aktuellen Gesprächs auf Grundlage einer zweistufigen Struktur vollständig aufzeichnen. Dies gewährleistet Kontinuität und Personalisierung des Gesprächs. Darüber hinaus speichert es wichtige Informationen aus früheren Gesprächen in zusammengefasster Form, um das Verständnis des Langzeitzustands des Patienten zu verbessern. Dadurch wird sichergestellt, dass das System wiederholte Fragen vermeidet und die Betriebseffizienz aufrechterhält.
* Verarbeitung:Es ist für die Zusammenfassung und Archivierung nach der Konsultation verantwortlich, beispielsweise für die Verwendung von LLM zum Erstellen strukturierter medizinischer Berichte, die Organisation des gesamten Gesprächs und die Erstellung eines Berichts, der eine Beschreibung des Zustands, eine Diagnose, eine Erklärung und Vorschläge zur Weiterbehandlung enthält, wodurch Patienten und Ärzten eine klare Konsultationszusammenfassung und Besuchszusammenfassung zur Verfügung gestellt wird.
In,Als zentrale Schnittstelle zur Interaktion mit Patienten enthält die „Dialogkomponente“ drei Untermodule:* Funktionsmodul:Verwenden Sie einen Planer, um die Konsultationsabsicht (wie Diagnose, Erklärung oder Empfehlung) dynamisch zu identifizieren und das „Anfrage-Untermodul“ zu steuern, um mehrere Runden proaktiver Befragung durchzuführen und die Patienten dazu zu bringen, umfassendere Informationen bereitzustellen.
* Sicherheitsmodul:Durch unabhängige Ethik-, Notfall- und Fehlererkennungsmechanismen werden generierte Antworten mithilfe einer „Diskutieren-und-Überarbeiten“-Strategie überprüft und überarbeitet, um die Einhaltung medizinischer Vorschriften und Sicherheitsstandards sicherzustellen.
* Arztmodul:Ermöglicht es medizinischem Fachpersonal, direkt einzugreifen oder Antworten durch natürliche Sprachführung zu modifizieren, wodurch ein Überwachungsmechanismus für die Mensch-Maschine-Zusammenarbeit geschaffen wird.
Zweistufiger Bewertungsprozess: Doppelte Überprüfung der automatischen Bewertung und der Arztbewertung
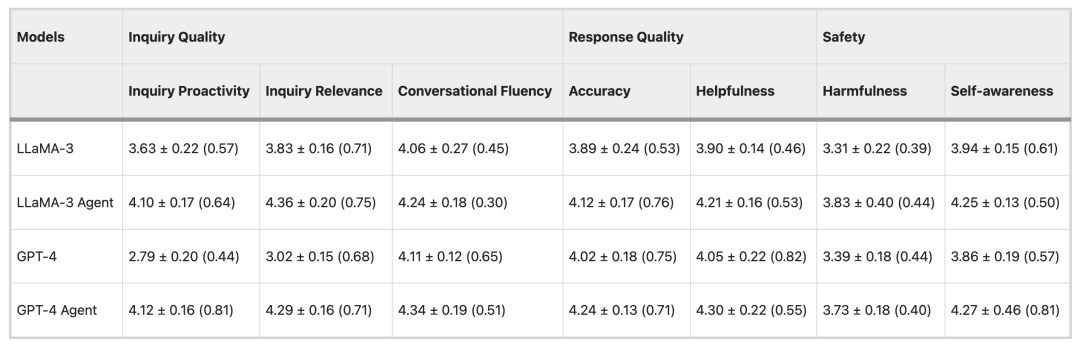
Der Bewertungsprozess gliedert sich in zwei Phasen: die automatische Bewertung und die Arztbewertung. Bei der automatischen Bewertung wird ChatGPT als Bewerter eingesetzt, während bei der Arztbewertung ein Gremium aus sieben Ärzten die Beratungsgespräche überprüft und bewertet. Die Bewertungsergebnisse zeigen, dassHealthcare Agent verfügt im Vergleich zu allgemeinen LLMs wie Claude, GPT4 und Gemini über eine deutlich verbesserte Selbstwahrnehmung, Genauigkeit, Hilfsbereitschaft und Schädlichkeit.Gleichzeitig zeigt Healthcare Agent auch eine starke Generalisierungsfähigkeit.
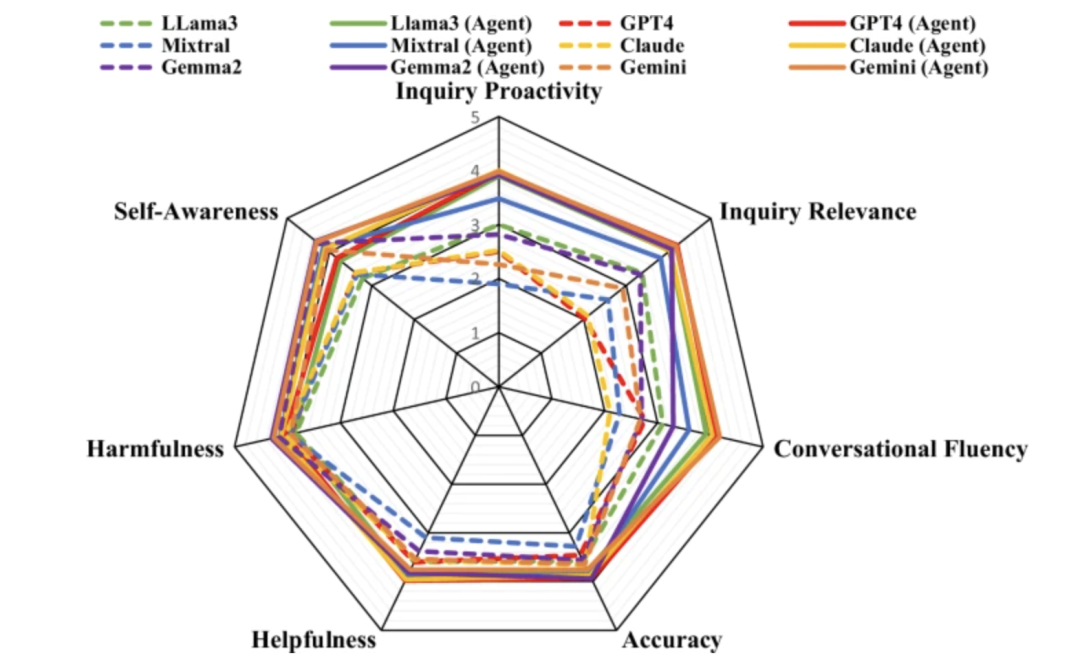
Automatische Auswertungsergebnisse
Im automatisierten Auswertungsexperiment verwendete das Forschungsteam drei beliebte Open-Source-LLMs (LLama-3, Mistral und Gemma-2) und drei Closed-Source-LLMs (GPT-4, Claude-3.5 und Gemini-1.5) als Basismodelle und wertete 50 Datensätze aus.
In Bezug auf die Beratungsqualität geben LLMs wie Mixtral und GPT-4 in der Regel direkte Antworten, anstatt proaktiv Fragen zu stellen, während die Beratungen von Healthcare Agent vergleichsweise proaktiver und relevanter sind. In Bezug auf die Antwortqualität verringert Healthcare Agent die Leistungslücke zwischen Open-Source- und Closed-Source-Modellen deutlich. In puncto Sicherheit reduziert Healthcare Agent die Schädlichkeit von Antworten effektiv durch die ethischen, Notfall- und Fehlererkennungsmechanismen des Sicherheitsmoduls.
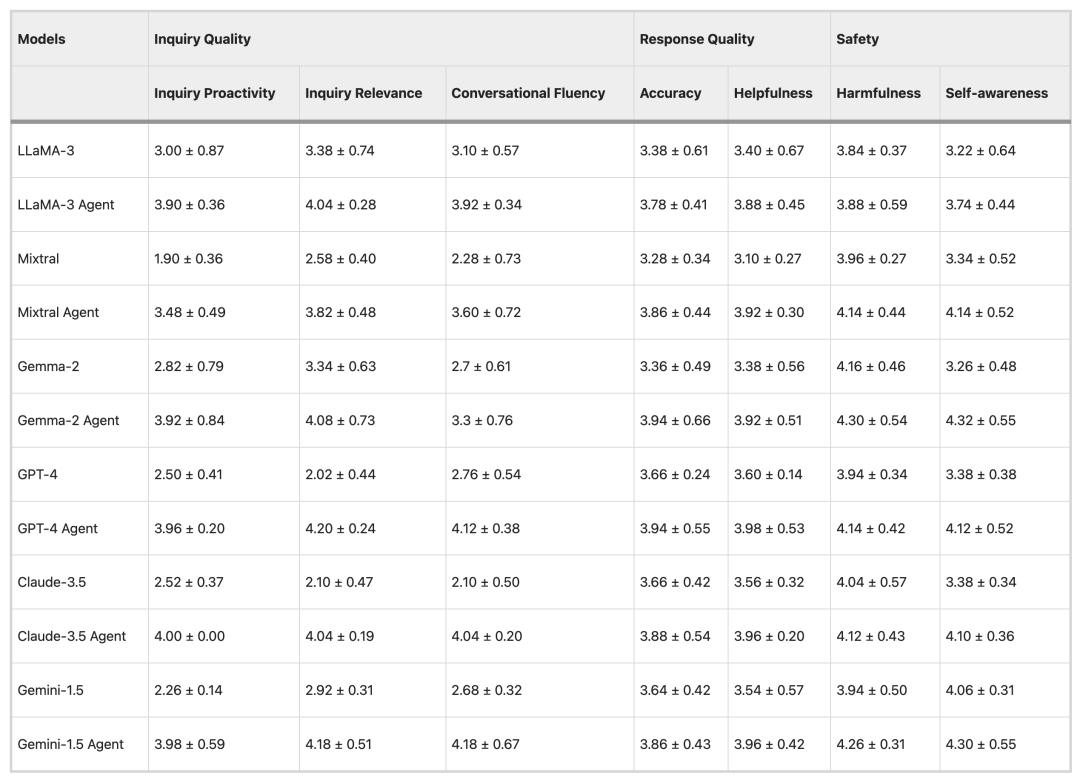
Ergebnisse der ärztlichen Untersuchung
Um die Zuverlässigkeit der automatischen Bewertungsmethode zu überprüfen, wurden im Experiment 15 Datensätze mit den Modellen LLaMA-3 und GPT-4 ausgewertet und anschließend sieben Ärzte zur Teilnahme an der Bewertung eingeladen. Die Ergebnisse zeigten, dassEs besteht ein hohes Maß an Übereinstimmung zwischen der ärztlichen Beurteilung und den Ergebnissen der automatisierten Auswertung.Bei zwei Indikatoren, nämlich der Gesprächsflüssigkeit und der Schädlichkeit, gab es nur geringfügige Unterschiede, was die Genauigkeit der automatisierten Bewertungsmethode und ihre potenzielle Anwendung in der groß angelegten klinischen Bewertung bestätigte.
Von der Erstellung medizinischer Aufzeichnungen bis hin zur Beratungsunterstützung beschleunigen große Modelle ihren Einzug in klinische Szenarien.
Angesichts der rasanten Entwicklung des LLM im medizinischen Bereich untersuchen Forscher und Industrie ständig seinen Anwendungswert im klinischen Arbeitsablauf und in der Arzt-Patienten-Kommunikation.Ob es um die Reduzierung des bürokratischen Aufwands für Ärzte oder die Verbesserung der Qualität der Patientenberatung und Diagnose geht – die neuesten Errungenschaften finden nach und nach ihren Weg vom Labor in die klinische Praxis.
Zuvor haben viele Forschungsteams umfangreiche Untersuchungen im Bereich medizinischer Dokumente und Patientenberatung durchgeführt. AI Scribe, ein von Microsoft Nuance entwickelter medizinischer Dokumentationsassistent mit künstlicher Intelligenz, kann Spracherkennung und große Sprachmodelltechnologie nutzen, umAutomatische Transkription, Zusammenfassung und Erstellung standardisierter Krankenakten für Arzt-Patienten-Gespräche in Ambulanzen oder bei Visiten. So wird der Zeitaufwand für die Dokumentation eines einzelnen Besuchs reduziert. Diese Errungenschaft wurde rasch in großen Gesundheitssystemen umgesetzt, darunter im Stanford University Medical Center, im Massachusetts General Hospital und im University of Michigan Medical Center. UC San Diego Health hat ein umfangreiches Sprachmodell in sein Portalsystem integriert, um Arztantworten zu verfassen. Das Ergebnis sind Entwürfe, die den Kontrolltext sowohl in puncto Einfühlungsvermögen als auch in der Präsentationsqualität übertreffen.
Darüber hinaus haben Google DeepMind und Google Research gemeinsam AMIE (Articulate Medical Intelligence Explorer) entwickelt, um intelligente medizinische Beratung und Differentialdiagnose zu fördern. In einer randomisierten Querschnittsstudie simulierter Ambulanzen in mehreren Ländern verglichen die Forscher die Beratungsleistung von AMIE mit der von Allgemeinmedizinern.Die Ergebnisse zeigten, dass Fachärzte 28 von 32 Bewertungsdimensionen besser bewerteten als Allgemeinmediziner und dass AMIE zudem eine höhere diagnostische Genauigkeit aufwies, was die Zuverlässigkeit von AMIE bei der Differentialdiagnose komplexer Fälle bestätigt.
Mit der zunehmenden Anzahl klinischer Studien dürften diese Technologien in Zukunft zu wichtigen Helfern in der klinischen Praxis werden und gleichzeitig Sicherheit und Zuverlässigkeit gewährleisten, wodurch sie gleichzeitig zur Verbesserung der Effizienz und Qualität medizinischer Leistungen beitragen.
Referenzlinks:
1.https://med.stanford.edu/news/all-news/2024/03/ambient-listening-notes.html
2.https://today.ucsd.edu/story/introducing-dr-chatbot
3.https://research.google/blog/amie-a-research-ai-system-for-diagnostic-medical-reasoning-and-conversations/
4.https://hnrb.hunantoday.cn/hnrb_epaper/html/2025-09/06/content_1753017.htm?div=-1








