Command Palette
Search for a command to run...
Thema Superauflösung | 3 Methoden, 4 Tutorials, 10 Datensätze – Die Wichtigsten Wissenspunkte in Einem Artikel

Dezember 2010,Su Guangda, Professor am Institut für Elektrotechnik der Tsinghua-Universität, erhielt einen ungewöhnlichen AnrufEin Polizeibeamter des Jungar-Kriminalpolizeiteams der Autonomen Region Innere Mongolei bat Su Guangda um Hilfe, da ihm ein verschwommenes Gesichtsbild des Verdächtigen vorlag.
„Dieses Bild wurde von einer Überwachungskamera am Straßenrand aufgenommen. Die Pixel sind sehr niedrig und mit bloßem Auge überhaupt nicht erkennbar“, erinnerte sich Su Guangda. Dieses verschwommene Bild übertrug er damals mithilfe der Super-Resolution-Technologie in die von ihnen entwickelte Software und rekonstruierte es. Anhand des rekonstruierten hochauflösenden Bildes konnte die Polizei von Junggar den Verdächtigen schnell identifizieren und den Mordfall aufklären.

Tatsächlich ist dieser Fall kein Einzelfall. Wenn die Polizei einen Fall untersucht, kann sie über Überwachungskameras Bilder des Verdächtigen erhalten und so den Prozess der Aufklärung des Falles beschleunigen. Bei der Vergrößerung von Fotos von Überwachungskameras werden jedoch häufig Einzelheiten unscharf, was die Effizienz der Polizei bei der Beschaffung wichtiger Beweise erheblich einschränkt.
Mit der Entwicklung der Superauflösungstechnologie haben sich diese Probleme umgekehrt und werden nach und nach gelöst.
Dieser Artikel beginnt mit dem Konzept, stellt die gängigen Superauflösungsalgorithmen und ihre Vor- und Nachteile vor und demonstriert ihre Anwendung in verschiedenen Szenarien wie öffentliche Sicherheit, medizinische Diagnose, Satellitenfernerkundung, digitale Unterhaltung usw. Darüber hinaus wurden auf der offiziellen Website von HyperAI Super Neural zahlreiche öffentliche Tutorials und öffentliche Datensätze zum Thema Superauflösung veröffentlicht. Sie können sie gerne ausprobieren!
Was ist Superauflösung?
Super-Resolution (SR), kurz gesagt,Dabei wird das Bild mit niedriger Auflösung (LR) durch einen Algorithmus auf eine hohe Auflösung (HR) aufgewertet.Im Vergleich zu Bildern mit niedriger Auflösung weisen hochauflösende Bilder eine höhere Pixeldichte und reichere Texturdetails auf und sind zuverlässiger.

Diese Technologie kann Probleme wie Bildunschärfe und schlechte Bildqualität, die durch die Einschränkungen des Bilderfassungssystems oder der Erfassungsumgebung selbst verursacht werden, überwinden oder kompensieren und bietet wichtige Unterstützung für die nachfolgende Bildverarbeitung, wie etwa Merkmalsextraktion und Informationserkennung.
Klassifizierung von Superauflösungsalgorithmen
Derzeit werden Superauflösungsmethoden hauptsächlich in drei Kategorien unterteilt: interpolationsbasierte Methoden, rekonstruktionsbasierte Methoden und lernbasierte Methoden.
* Interpolationsbasierte Methoden
Die Interpolationsmethode vergrößert die Größe des Bildes, indem sie neue Pixel um die ursprünglichen Pixel des Bildes herum einfügt und diesen Pixeln Werte zuweist, um den Bildinhalt wiederherzustellen und den Effekt einer Verbesserung der Bildauflösung zu erzielen.
*Pixel: Das grundlegendste Einheitselement eines Bildes, also ein Punkt. Jeder Pixel hat seinen eigenen Farbwert. Je mehr Pixel pro Flächeneinheit vorhanden sind, desto klarer ist das Bild.
* Rekonstruktionsbasierter Ansatz
Auf Rekonstruktion basierende Superauflösungsalgorithmen verwenden normalerweise mehrere Bilder mit niedriger Auflösung, die in derselben Szene aufgenommen wurden, als Eingabe und analysieren dann die Frequenzbereichs- oder Raumbereichsbeziehung dieser Bilder. Der Rekonstruktionsprozess wird durch die Einführung von Vorabinformationen gesteuert und eingeschränkt und es wird ein einzelnes hochauflösendes Bild rekonstruiert.
*Frequenzbereich: bezieht sich auf die Eigenschaften des Signals im Frequenzbereich.
*Räumlicher Bereich: bezieht sich auf die Verteilung von Signalen im Raum.
*Vorabinformationen: Diese Informationen liegen „vor dem Experiment“ vor und können allgemein als Domänenwissen verstanden werden.
* Lernbasierte Methoden
Lernbasierte Methoden zur Superauflösung verwenden normalerweise eine große Menge an Trainingsdaten, um die Abbildungsbeziehung zwischen Bildern mit niedriger Auflösung und Bildern mit hoher Auflösung zu erlernen, die in Bildern mit niedriger Auflösung verloren gegangenen hochfrequenten Detailinformationen vorherzusagen und so Bilder mit Superauflösung zu erzeugen.
Zu den auf oberflächlichem Lernen basierenden Methoden zählen hauptsächlich maschinelles Lernen, Manifold Learning, Sample Learning und Sparse Coding, die in Situationen verwendet werden können, in denen die Datenmenge gering ist.
Auf Deep Learning basierende Methoden können in SR-Methoden auf Basis von Convolutional Neural Networks, SR-Methoden auf Basis von Residual Networks (ResNet) und SR-Methoden auf Basis von Generative Adversarial Networks (GAN) unterteilt werden.

Bildquelle: Faxin.com
Die Vor- und Nachteile der oben genannten drei Methoden sind wie folgt:
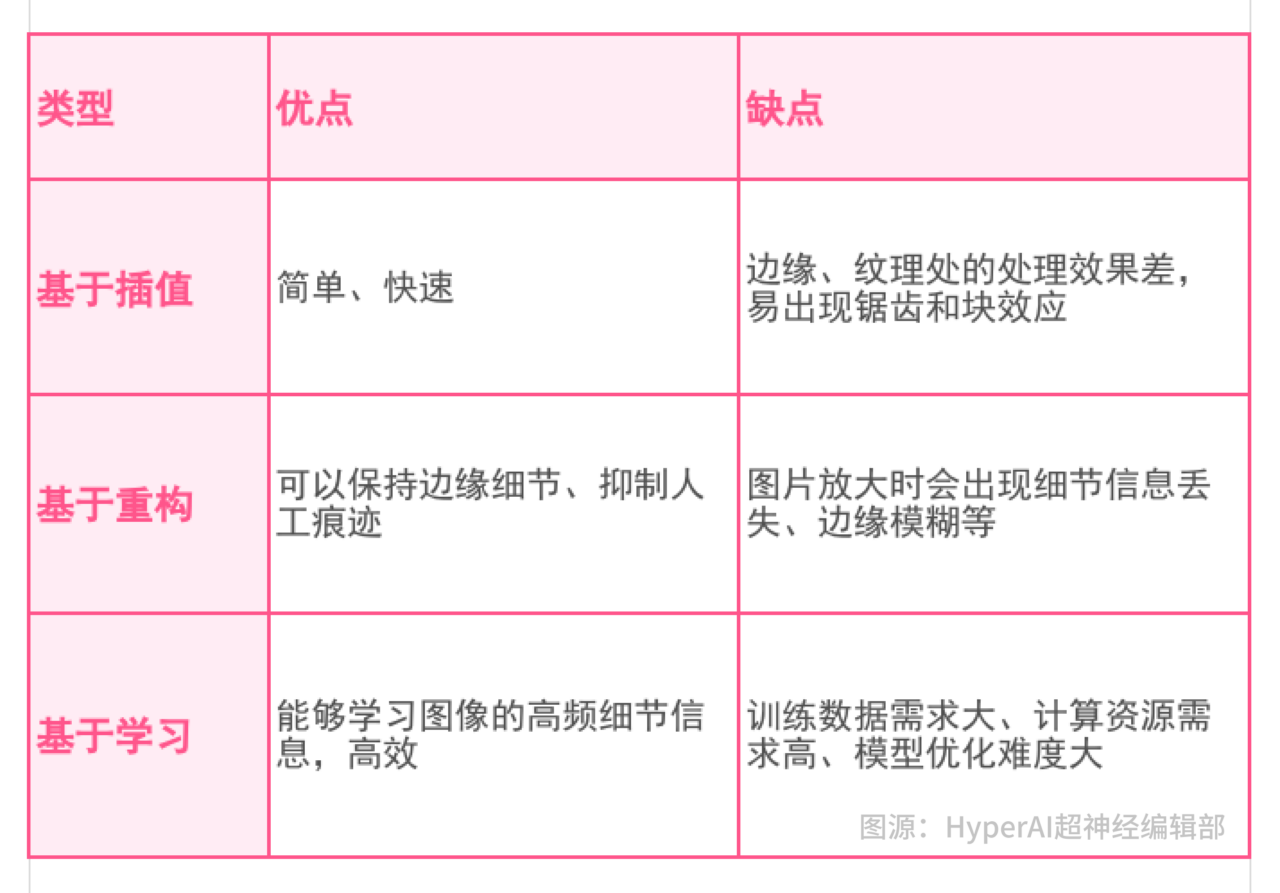
Heutzutage ist Deep Learning die gängige Methode im Bereich der Superauflösung.
Im Jahr 2014 haben Dong et al. wandte Deep Learning erstmals im Bereich der Bildrekonstruktion mit superhoher Auflösung an.Das Netzwerkmodell SRCNN (Super-Resolution Convolutional Neural Network) wurde vorgeschlagen.Dieses Ergebnis wurde auf arXiv unter dem Titel „Image Super-Resolution Using Deep Convolutional Networks“ veröffentlicht. Seitdem wurde im Bereich der Superauflösungsrekonstruktion eine Welle des Deep Learning ausgelöst.
Papieradresse:
https://arxiv.org/pdf/1501.00092

Als erstes Modell, das Deep-Learning-Methoden auf die Bild-Superauflösung anwendete, erreichte SRCNN durch die Verwendung von nur drei Faltungsschichten einen PSNR-Wert, der den herkömmlicher Methoden weit übertraf.
Konkret wird ein Bild mit niedriger Auflösung eingegeben, das Bild wird mithilfe einer bikubischen Interpolation auf die Zielgröße vergrößert, und dann wird ein dreischichtiges Convolutional Neural Network verwendet, um die nichtlineare Abbildung zwischen dem Bild mit niedriger Auflösung und dem Bild mit hoher Auflösung anzupassen, und schließlich wird das rekonstruierte Bild mit hoher Auflösung ausgegeben.
*PSNR-Wert: Spitzensignal-Rausch-Verhältnis. Je höher der Wert, desto besser ist die Qualität des ausgegebenen HR-Bildes.
Aufgrund seiner Einfachheit und hohen Effizienz ist SRCNN zu einem wichtigen Meilenstein auf dem Gebiet der Bild-Superauflösung geworden.Seitdem hat sich die auf Deep Learning basierende Super-Resolution-Technologie rasant weiterentwickelt, von der frühen Super-Resolution-Technologie auf Basis von Convolutional Neural Networks (CNN) bis hin zur aktuellen Technologie auf Basis von Generative Adversarial Networks.
Deep Learning + Superauflösung: Vielfältige Anwendungen von der öffentlichen Sicherheit bis zur digitalen Unterhaltung
Die Nachfrage treibt die technologische Entwicklung voran und die technologische Iteration unterstützt die Implementierung von Anwendungen. Heutzutage wird die Superauflösungstechnologie häufig in der öffentlichen Sicherheit, der medizinischen Diagnostik, der Satellitenfernerkundung, den Unterhaltungsmedien und anderen Bereichen eingesetzt.
* Bereich der öffentlichen Sicherheit
Öffentliche Überwachungsvideos werden durch Faktoren wie Wetter und Entfernung beeinflusst und die Bilder sind oft unscharf und haben eine niedrige Auflösung. Durch den Einsatz von Super-Resolution-Technologie kann die Polizei Gesichter, Nummernschilder und andere wichtige Informationen deutlich erkennen und so zur Aufklärung von Fällen beitragen.
Feng Shunli vom Jilin Police College verwendete ESRGAN- und BSRGAN-Netzwerke, um Porträts und Naturszenerien in verschiedenen Umgebungen zu analysieren, und untersuchte die Machbarkeit der Anwendung von Superauflösungstechnologie in der öffentlichen Sicherheit und vor Gericht.
Das Ergebnis wurde im Journal der Armed Police Academy unter dem Titel „Anwendung der Bild-Superauflösungs-Rekonstruktionstechnologie in der Polizeiarbeit“ veröffentlicht.
Papieradresse:
https://www.faxin.cn/lib/Flwx/FlqkContent.aspx?gid=F805122&libid=040106
Zunächst reproduzierten, trainierten und testeten die Forscher die ESRGAN- und BSRGAN-Modelle, um die optimalen Modellparameter zu erhalten. Anschließend wird das trainierte Modell verwendet, um eine Superauflösungsrekonstruktion der gesammelten Bilder mit geringer Qualität wie Porträts und Naturlandschaften durchzuführen und die Rekonstruktionsergebnisse von ESRGAN und BSRGAN zu erhalten.

Die Forscher verglichen die rekonstruierten Bilder von ESRGAN und BSRGAN mit den Originalbildern.Die Ergebnisse zeigen, dass die rekonstruierten Porträts in Frontalansicht, schrägen Winkeln und komplexen Szenen deutliche Verbesserungen in der Bildqualität und Wiedergabetreue aufweisen.

Beim Vergleich natürlicher Szenen ist der Rekonstruktionseffekt von BSRGAN besser als der von ESRGAN.Es kann unbekanntes, komplexes Rauschen effektiv aus dem ursprünglichen Bild mit niedriger Qualität entfernen und klare Kanten und feine Details erzeugen.
* Medizinisches Diagnosefeld
Aufgrund der Einschränkungen bei der Bildgebungsausrüstung und der komplexen klinischen Umgebungen weisen im medizinischen Bereich aufgenommene Bilder häufig eine unzureichende Auflösung auf, was sich direkt auf die Genauigkeit der Diagnose und Behandlungsentscheidungen der Ärzte bei Krankheiten auswirkt.

Peng Bo und andere vom Sichuan People's Hospital verwendeten als grundlegende Methode das Generative Adversarial Network (SRGAN) zur Rekonstruktion natürlicher Bilder mit Superauflösung.Die Netzwerkstruktur wurde durch Reduzierung von 2 Eingangskanälen und Löschen von 1 Restblock geändert, die Netzwerkverlustfunktion wurde verbessert und ein neuer Datensatz zur Unschärfeverarbeitung wurde hinzugefügt, um ein medizinisches Ultraschallbild mit klaren Kanten und ohne Artefakte zu rekonstruieren, das 4-fach vergrößert wurde.
Dieses Ergebnis wurde im Journal of Terahertz Science and Electronic Information Technology unter dem Titel „Super-resolution Reconstruction of Ultrasound Images Based on Generative Adversarial Networks“ veröffentlicht.
Papieradresse:
http://www.iaeej.com/xxydzgc/article/abstract/202305015


Die Forscher verglichen das verbesserte SRGAN mit drei anderen Algorithmen.Die Ergebnisse zeigen, dass die Rekonstruktionsergebnisse des verbesserten SRGAN insgesamt glatter und die Texturkanten klarer sind.
* Satellitenfernerkundungsfeld
In den letzten Jahren wurden Fernerkundungssatellitenbilder in großem Umfang in Bereichen wie Umweltüberwachung, Rohstofferkundung, Katastrophenwarnung und Militär eingesetzt. Allerdings wird die Klarheit von Fernerkundungssatellitenbildern durch Faktoren wie atmosphärische Veränderungen, Übertragungsrauschen, Bewegungsunschärfe und eine unzureichende Abtastung optischer Sensoren erheblich eingeschränkt. Mithilfe der Superauflösungstechnologie können durch die Verarbeitung und Verbesserung niedrig aufgelöster Bilder die Qualität und Verfügbarkeit von Satellitenfernerkundungsdaten verbessert werden.

Yan Bodhi und andere vom Harbin Institute of Technology führten die detaillierten Merkmalsinformationen lokaler Cluster-Zielbereiche in Fernerkundungsbildern in die Stichprobennahme und Rekonstruktion vollständiger Fernerkundungsbilder ein, extrahierten Bildmerkmale unterschiedlicher Maßstäbe durch mehrschichtige neuronale Netzwerke und fusionierten und rekonstruierten diese Merkmale durch Residuallernen.Mit dieser Methode kann die Detailwirkung des globalen Fernerkundungsbildes deutlich verbessert und die Auflösung des Cluster-Zielbereichs mit Hilfe der Pixelinformationen des lokalen Bildes optimiert werden.
Die Errungenschaft mit dem Titel „Superauflösungsrekonstruktion von Cluster-Zielgebieten durch Fernerkundung kombiniert mit lokalen hochauflösenden Bildern“ wurde im Journal der Nanjing University of Aeronautics and Astronautics veröffentlicht.
Papieradresse:
https://jnuaa.nuaa.edu.cn/njhkht/article/html/202306002

Die in der Studie vorgestellte Vergleichstabelle zeigt, dass diese Methode hinsichtlich der Visualisierungswirkung anderen bestehenden Methoden deutlich überlegen ist.Es eignet sich für Stadt- und Außenaufnahmen und zeigt gute Ergebnisse.
* Digitale Unterhaltung
Eine Animation besteht aus mehreren miteinander verbundenen Standbildern und die Auflösung der Standbilder beeinflusst die Klarheit der endgültigen Animation. Allerdings können vorhandene handgezeichnete oder digitale Zeichnungen keine hohe Auflösung des ersten Entwurfs garantieren, was sich negativ auf das visuelle Erlebnis des Benutzers auswirkt. Durch die Anwendung der Superauflösungstechnologie können diese Bilder mit niedriger Auflösung in Bilder mit höherer Auflösung umgewandelt werden, die mehr Details und Texturen darstellen können, wodurch die Bilder von Animationswerken lebendiger und realistischer werden.
Bilibili hat ein Modell zur Wiederherstellung der Animationsqualität namens Real-CUGAN (Real Cascaded-U-Net-style Generative Adversarial Networks) eingeführt.
Zunächst verwendeten die Forscher das Modell, um die Animationsbilder aufzuteilen, und nutzten das Bildqualitätsbewertungsmodell, um die Kandidatenblöcke zu bewerten und zu filtern. So erhielten sie schließlich einen Trainingssatz mit Millionen qualitativ hochwertiger Animationsbildblöcke.
Anschließend werden die hochauflösenden Bildblöcke mithilfe eines mehrstufigen Degradationsalgorithmus heruntergesampelt, um Bilder von geringer Qualität zu erhalten. Dadurch kann das Modell den Rekonstruktionsprozess von Bildern von geringer Qualität zu Bildern von hoher Qualität erlernen und optimieren. Nach Abschluss des Trainings kann das Modell echte zweidimensionale Bilder von geringer Qualität in hochauflösende Bilder verarbeiten.
Die Vergleichstabelle der verschiedenen Algorithmen sieht wie folgt aus:

Open-Source-Datensätze und Tutorials mit Superauflösung
derzeit,Auf der offiziellen Website von HyperAI wurden zahlreiche Ressourcen mit Superauflösung veröffentlicht.Enthält öffentliche Tutorials und Datensätze.
* Öffentliche Tutorials
1. APISR Animation Image Super Resolution Enhancer
APISR ist ein Open-Source-Projekt zur Verbesserung der Auflösung von Anime-Bildern und -Videos. Es kann Anime-Bilder und Videoquellen mit niedriger Qualität und Auflösung wiederherstellen und verbessern und verschiedene Bildverschlechterungsprobleme (Unschärfe, Rauschen, Komprimierungsartefakte usw.) beheben.
Adresse des Online-Betriebs:https://hyper.ai/tutorials/31383
2. SUPIR-AI Bildwiederherstellungs-Tutorial
SUPIR kann Bilder mit niedriger Auflösung auf eine hohe Auflösung hochskalieren und dabei Bilddetails und Realismus beibehalten und verschiedene komplexe Verschlechterungssituationen bewältigen.
Adresse des Online-Betriebs:https://hyper.ai/tutorials/30940
3. Bild-Superauflösung durch latente Diffusion
Dieses Tutorial zeigt, wie Sie die Diffusorbibliothek verwenden, um das Superauflösungsmodell für latente Diffusionsbilder zu implementieren.
Adresse des Online-Betriebs:https://hyper.ai/tutorials/26207
4. Bild-Superauflösung durch effizientes Subpixel-CNN
Dieses Tutorial implementiert Superauflösung im BSDS 500-Datensatz mithilfe eines effizienten Subpixelmodells.
Adresse des Online-Betriebs:https://hyper.ai/tutorials/25044
* Öffentliche Datensätze
1. MSU-Datensatz mit Superauflösung
Der Datensatz enthält Innen- und Außenvideos sowie Animationen, und alle Videos haben niedrige SI/TI-Werte und einfache Texturen. Entwickelt, um mögliche Komprimierungsartefakte zu minimieren und Details wiederherzustellen.
Direkte Verwendung:https://hyper.ai/datasets/20401
2. MSU-Video-Super-Resolution-Datensatz
Dieser Datensatz wird für Aufgaben mit Video-Superauflösung verwendet und enthält die komplexesten Inhalte bei Aufgaben zur Detailwiederherstellung: Gesichter, Text, QR-Codes, Nummernschilder, Texturen ohne angezeigte Muster und kleine Details. Das Video enthält verschiedene Bewegungsarten sowie verschiedene Arten der Unschärfe: bikubische Interpolation, Gaußsche Unschärfe und Downsampling.
Direkte Verwendung:https://hyper.ai/datasets/17212
3. DRealSR-Bilddatensatz mit Superauflösung
Bei diesem Datensatz handelt es sich um einen Bilddatensatz mit hoher Auflösung über den tatsächlichen Bildverschlechterungsprozess, der die Einschränkungen der herkömmlichen simulierten Bildverschlechterung lindert. Der Datensatz umfasst Szenen im Innen- und Außenbereich, beispielsweise Werbeplakate, Anlagen, Büros und Gebäude.
Direkte Verwendung:https://hyper.ai/datasets/20446
4. TextZoom Super-Resolution-Datensatz
Dieser Datensatz besteht aus Paaren von Bildern mit niedriger Auflösung (LR) und hoher Auflösung (HR). Die Bilder wurden in der freien Natur mit Kameras unterschiedlicher Brennweite aufgenommen. Jedes Bildpaar verfügt über eine Beschriftung als Zeichenfolge (einschließlich Zeichensetzung), bei der die Groß- und Kleinschreibung beachtet wird, sowie über den Begrenzungsrahmentyp und die ursprüngliche Brennweite.
Direkte Verwendung:https://hyper.ai/datasets/19550
5.SR-RAW-Bild-Superauflösungsdatensatz
Dieser Datensatz enthält RAW-Sensordaten mit hochauflösenden Ground-Truth-Bildern, die mit hohen optischen Zoomstufen aufgenommen wurden. Jede Sequenz enthält 7 (manche enthalten 6) Bilder, die mit unterschiedlichen Brennweiten aufgenommen wurden.
Direkte Verwendung:
https://hyper.ai/datasets/19743
6.Set5, Set14 Einzelbild-Datensatz mit geringer Komplexität und hoher Auflösung
Dies ist ein hochaufgelöster Einzelbilddatensatz mit geringer Komplexität, der auf einer nicht-negativen Nachbarschaftseinbettung basiert. Der Trainingssatz wird für die Superauflösungsrekonstruktion einzelner Bilder verwendet, wobei hochauflösende Bilder auf der Grundlage von Bildern mit niedriger Auflösung rekonstruiert werden, um detailliertere Informationen zu erhalten. Es wird häufig in den Bereichen Computer Vision und Grafik, medizinische Bildgebung, Sicherheitsüberwachung und anderen Bereichen eingesetzt.
Direkte Verwendung:
https://hyper.ai/datasets/5382
7.DIV2K-Einzelbild-Superauflösungsdatensatz
Dieser Datensatz enthält 1000 Bilder mit niedriger Auflösung und unterschiedlichen Degradationsarten, die zur Rekonstruktion hochauflösender Bilder aus Bildern mit niedriger Auflösung verwendet werden können.
Direkte Verwendung:https://hyper.ai/datasets/15624
8.S2-NAIP US-Fernerkundungsdatensatz mit Superauflösung
Dieser Datensatz enthält gepaarte NAIP- und Sentinel-2-Bilder für die kontinentalen Vereinigten Staaten. Es bietet hochpräzise Datenunterstützung bei der Oberflächenüberwachung, dem Ressourcenmanagement und der Bewertung von Umweltveränderungen.
Direkte Verwendung:
https://hyper.ai/datasets/30427
9. Sun-Hays 80-Datensatz – Bilddatensatz mit Superauflösung
Dieser Datensatz verwendet globale Szenenbeschreibungen, um verwandte Szenen in Bilddatenbanken zu vergleichen und zu suchen. Die Szenen bieten ideale Beispieltexturen, um Probleme bei der Bildabtastung einzuschränken.
Direkte Verwendung:https://hyper.ai/datasets/5391
10. Urban100-Rekonstruktionsdatensatz mit Superauflösung
Der Datensatz enthält anspruchsvolle Stadtszenen mit Details in verschiedenen Frequenzbändern. Durch Herunterskalieren des realen Bilds mithilfe der bikubischen Interpolation können LR/HR-Bildpaare gewonnen werden, um Trainings- und Testdatensätze zu erhalten.
Direkte Verwendung:
https://hyper.ai/datasets/5385
Das Obige ist eine Zusammenfassung der Superauflösungsressourcen auf der offiziellen HyperAI-Website. Wenn Sie hochwertige Projekte sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um sie uns zu empfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, treten Sie der Gruppe bei, um verschiedene technische Probleme zu diskutieren und Anwendungsergebnisse auszutauschen ~
Scannen Sie den QR-Code, um der Tutorial-Austauschgruppe beizutreten









