Command Palette
Search for a command to run...
COIG-CQIA Hochwertiger Chinesischer Feinabstimmungsdatensatz Für Anweisungen
Datum
Größe
Organisation
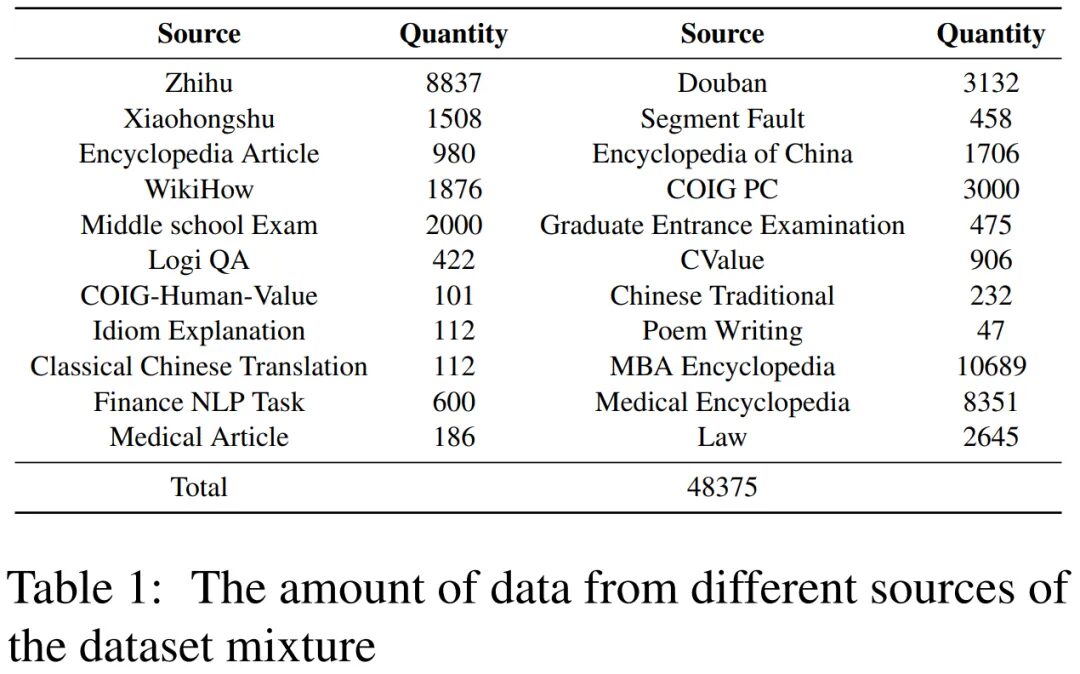
COIG-CQIA steht für Chinese Open Instruction Generalist – Quality is All You Need. Es handelt sich um einen Open-Source-Datensatz zur Feinabstimmung hochwertiger Anweisungen.Ziel ist es, der chinesischen NLP-Community hochwertige Daten zur Feinabstimmung von Anweisungen bereitzustellen, die mit dem menschlichen Interaktionsverhalten übereinstimmen. COIG-CQIA verwendet Fragen und Antworten sowie Artikel aus dem chinesischen Internet als Rohdaten und wird nach gründlicher Bereinigung, Rekonstruktion und manueller Überprüfung erstellt. Dieses Projekt ist von Studien wie LIMA inspiriert: Weniger ist mehr für die Ausrichtung. Mithilfe einer kleinen Menge hochwertiger Daten kann ein großes Sprachmodell menschliche Interaktionsverhaltensweisen erlernen. Daher wird bei der Datenkonstruktion großes Augenmerk auf die Quelle, Qualität und Vielfalt der Daten gelegt. Einzelheiten zum Datensatz finden Sie in der Dateneinführung und im Dokument des Forschungsteams. Datenerfassung
- Das Forschungsteam sammelte zahlreiche manuell verfasste Textdaten aus verschiedenen Quellen im chinesischen Internet, um die Vielfalt und Reichhaltigkeit der Daten sicherzustellen.
- Zu den Datenquellen zählen nicht nur Frage-und-Antwort-Communitys (wie Zhihu, Sifou, Douban, Xiaohongshu und Chiba), sondern auch wiki-ähnliche Wissensplattformen (wie Baidu Encyclopedia), verschiedene Arten von Prüfungsmaterialien (wie Fragen zu Aufnahmeprüfungen für die Mittel- und Oberschule, Fragen zu Prüfungen der beruflichen Qualifikation) und vorhandene NLP-Datensätze.
- Beim Sammeln von Daten konzentrieren wir uns auf die Auswahl relevanter Daten, die die tatsächlichen Interaktionsmuster chinesischer Benutzer widerspiegeln können, um das Verständnis des Modells für den realen Sprachgebrauch zu verbessern.
Zitat
@misc{bai2024coig,
title={COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning},
author={Bai, Yuelin and Du, Xinrun and Liang, Yiming and Jin, Yonggang and Liu, Ziqiang and Zhou, Junting and Zheng, Tianyu and Zhang, Xincheng and Ma, Nuo and Wang, Zekun and others},
year={2024},
eprint={2403.18058},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.