Command Palette
Search for a command to run...
VoxCeleb2-Spracherkennungsdatensatz
Datum
Größe
Veröffentlichungs-URL
Paper-URL
Lizenz
CC BY 4.0
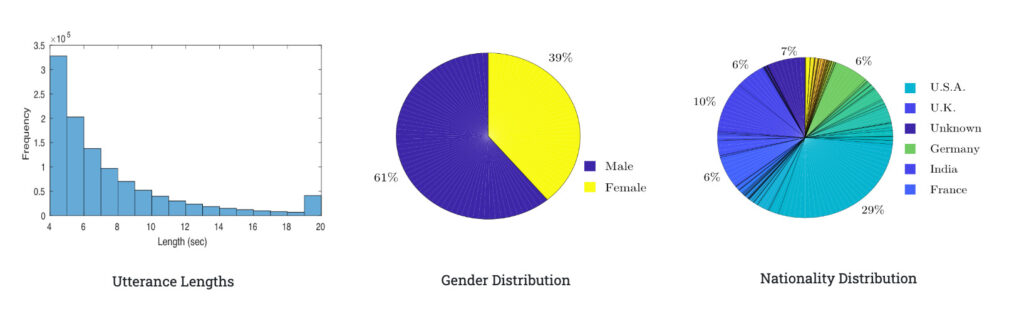
VoxCeleb2 ist ein umfangreicher Datensatz zur Sprechererkennung, der aus Open-Source-Medien stammt und aus einer Million Korpora von mehr als 6.000 Sprechern besteht. Da der Datensatz in natürlichen Szenen gesammelt wird, mangelt es in den Sprachclips nicht an Störungen wie Lachen, Gesprächen, Kanaleffekten, Musik usw.
Das Korpus in VoxCeleb2 ist mehrsprachig und umfasst Sprecher aus 145 Ländern mit einer großen Bandbreite an Akzenten, Altersgruppen, Ethnien und Sprachen. Gleichzeitig enthält dieser Datensatz Audio und Video und eignet sich auch zur Lösung von Problemen wie visueller Sprachsynthese, Sprachtrennung, kreuzmodaler Konvertierung von Gesicht und Stimme und Video-Gesichtserkennung.
Details zum Datensatz:
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.