HyperAI
Command Palette
Search for a command to run...
DeepSeek-OCR:「视觉压缩」替代传统字符识别
一、教程简介

DeepSeek-OCR 是深度求索公司于 2025 年 10 月发布的模型,是通过图像对长上下文进行压缩的可行性初步研究。 DeepEncoder 是核心引擎,旨在在高分辨率输入下保持低激活量,同时实现高压缩比,以确保视觉 token 的数量处于可控且优化的范围内。实验表明,当文本 token 数量不超过视觉 token 的 10 倍(即压缩比 < 10×)时,模型能达到 97% 的解码(OCR)精度。即便在 20× 的压缩比下,OCR 准确率仍约为 60% 。这对历史文献的长上下文压缩以及大模型的记忆衰退机制等研究方向展现了相当的前景。相关论文成果为 DeepSeek-OCR: Contexts Optical Compression 。
本教程默认使用资源为单卡 RTX 5090,最低可用单卡 RTX 4090 启动使用。
二、项目示例
三、运行步骤
1. 启动容器后点击 API 地址即可进入 Web 界面
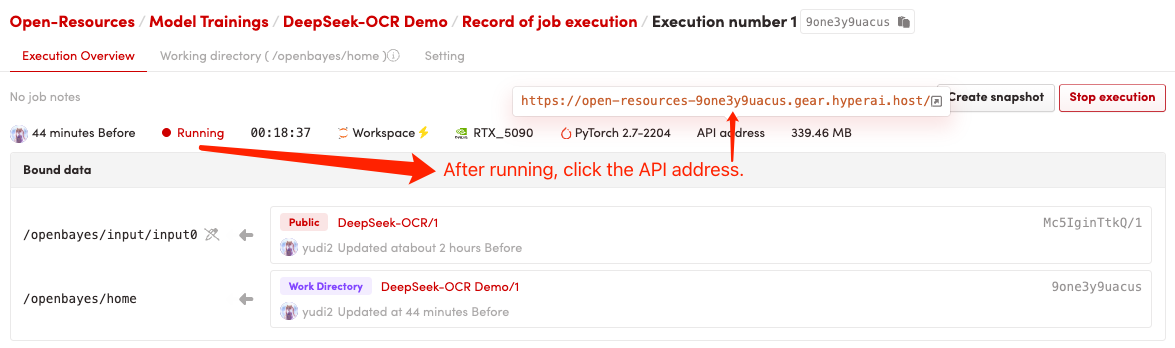
2. 进入网页后,即可上传图片,解析文字
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
使用步骤

3. 输出结果
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@article{wei2025deepseek,
title={DeepSeek-OCR: Contexts Optical Compression},
author={Wei, Haoran and Sun, Yaofeng and Li, Yukun},
journal={arXiv preprint arXiv:2510.18234},
year={2025}
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。