HyperAI
Command Palette
Search for a command to run...
MinerU2.5-2509-1.2B:文档解析 Demo
一、教程简介

MinerU2.5-2509-1.2B 是由 OpenDataLab 与上海 AI 实验室于 2025 年 9 月推出的视觉语言模型,专为高精度、高效率的文档解析任务而设计。它是 MinerU 系列的最新迭代版本,聚焦于将 PDF 等复杂格式文档转化为结构化的机器可读数据(如 Markdown 、 JSON 等)。相关论文成果为 MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing 。
本教程采用资源为单卡 RTX 4090 。
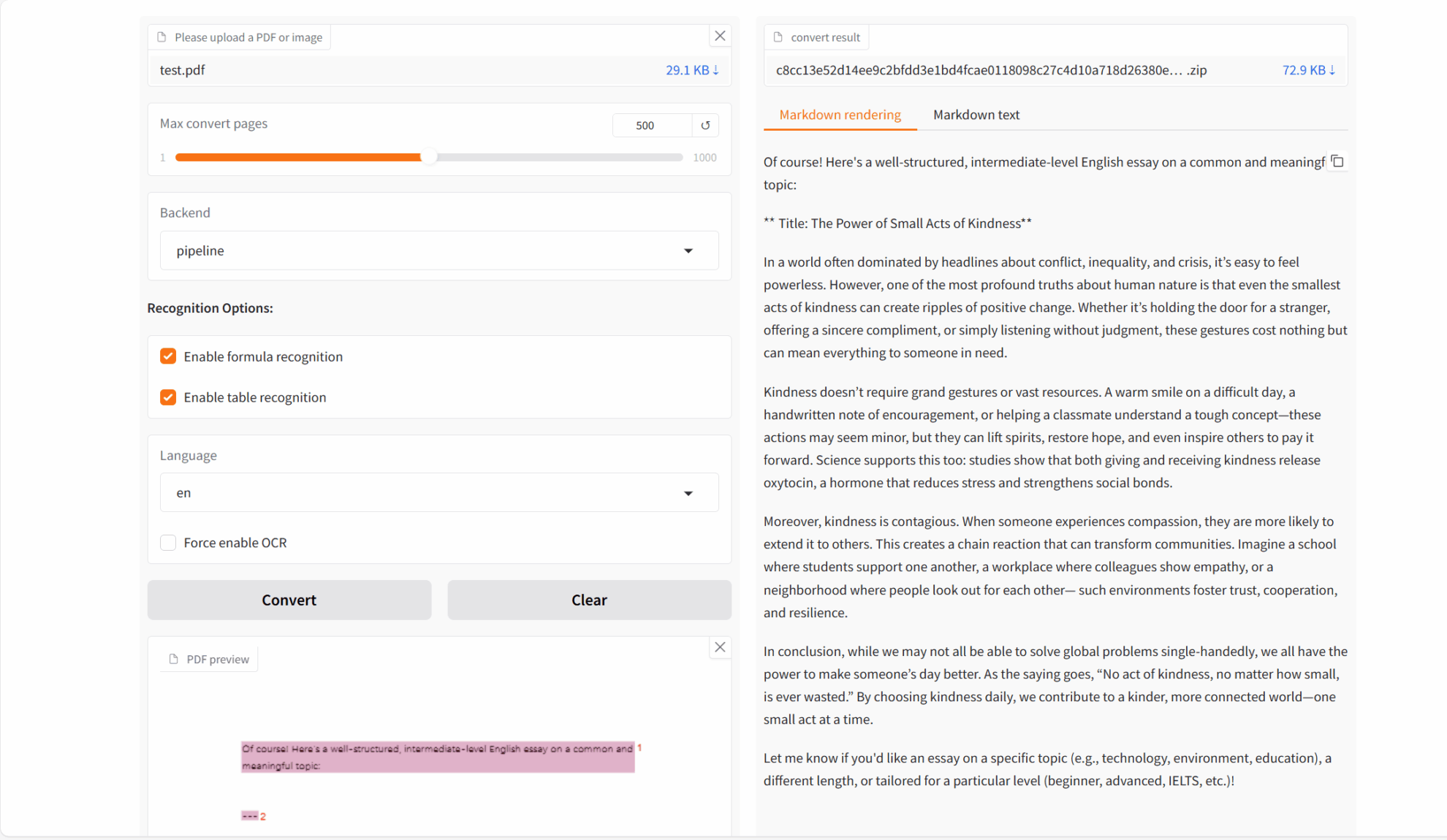
二、项目示例
三、运行步骤
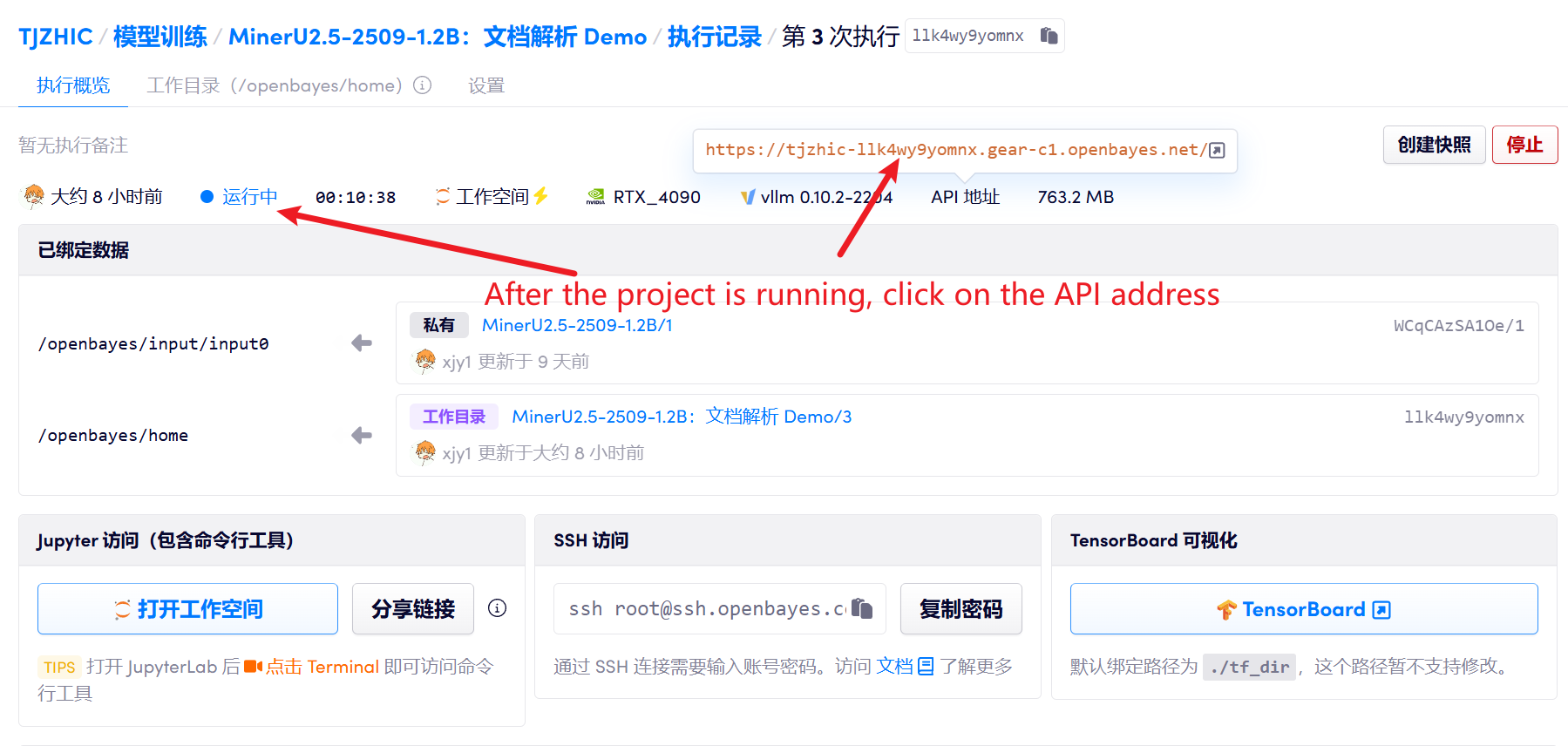
1. 启动容器后点击 API 地址即可进入 Web 界面
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
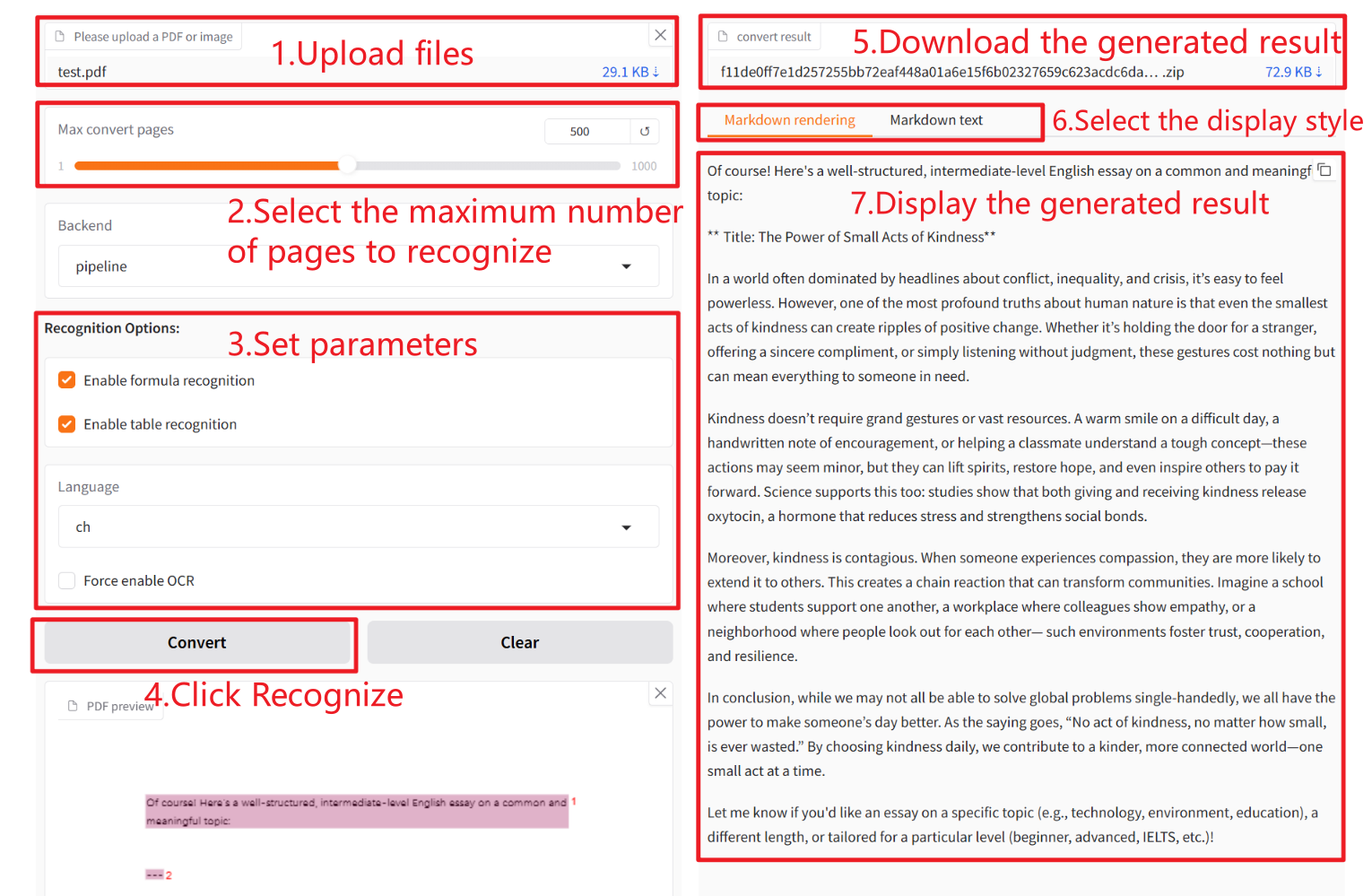
参数说明
- Enable formula recognition:是否启用公式识别,启用后,系统会识别文档中的数学公式并将其转换为 LaTeX 格式。
- Enable table recognition:是否启动表格识别功能,启用后,系统会识别文档中的表格并将其转换为 HTML 格式。
- Language:用于指定文档的语言。它可以提高 OCR 的准确率。
- orce enable OCR:强制启用 OCR 功能。
引用信息
本项目引用信息如下:
@misc{niu2025mineru25decoupledvisionlanguagemodel,
title={MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing},
author={Junbo Niu and Zheng Liu and Zhuangcheng Gu and Bin Wang and Linke Ouyang and Zhiyuan Zhao and Tao Chu and Tianyao He and Fan Wu and Qintong Zhang and Zhenjiang Jin and others},
year={2025},
eprint={2509.22186},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.22186},
}该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。