HyperAI
Command Palette
Search for a command to run...
SRPO:图像生成告别 AI 味!
一、教程简介

SRPO 是由腾讯混元团队、香港中文大学(深圳)理学院、清华大学深圳国际研究生院于 2025 年 9 月共同推出的文本到图像生成模型,通过将奖励信号设计为文本条件信号,实现对奖励的在线调整,减少对离线奖励微调的依赖。 SRPO 引入 Direct-Align 技术,通过预定义噪声先验直接从任何时间步恢复原始图像,避免在后期时间步的过度优化问题。在 FLUX.1.dev 模型上的实验表明,SRPO 能显著提升生成图像的人类评估真实感和审美质量,且训练效率极高,仅需 10 分钟即可完成优化。相关论文成果为 Directly Aligning the Full Diffusion Trajectory with Fine-Grained Human Preference 。
该教程算力资源采用单卡 A6000,该模型目前仅支持英文 Prompt 。
二、效果展示

三、运行步骤
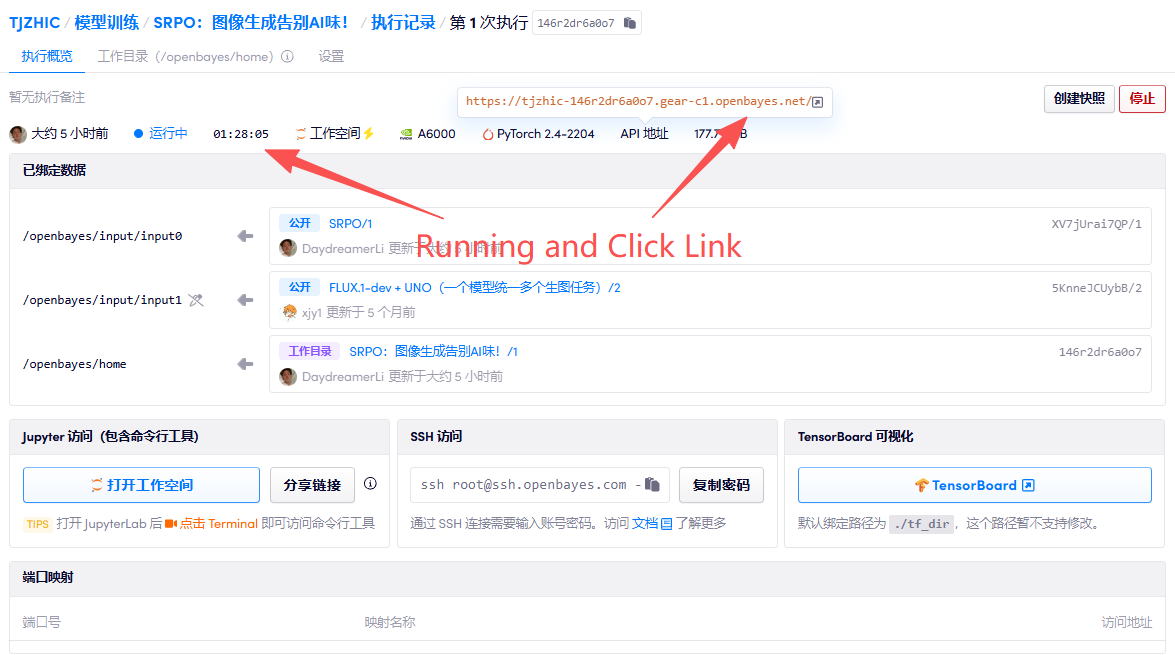
1. 启动容器
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
2. 使用步骤
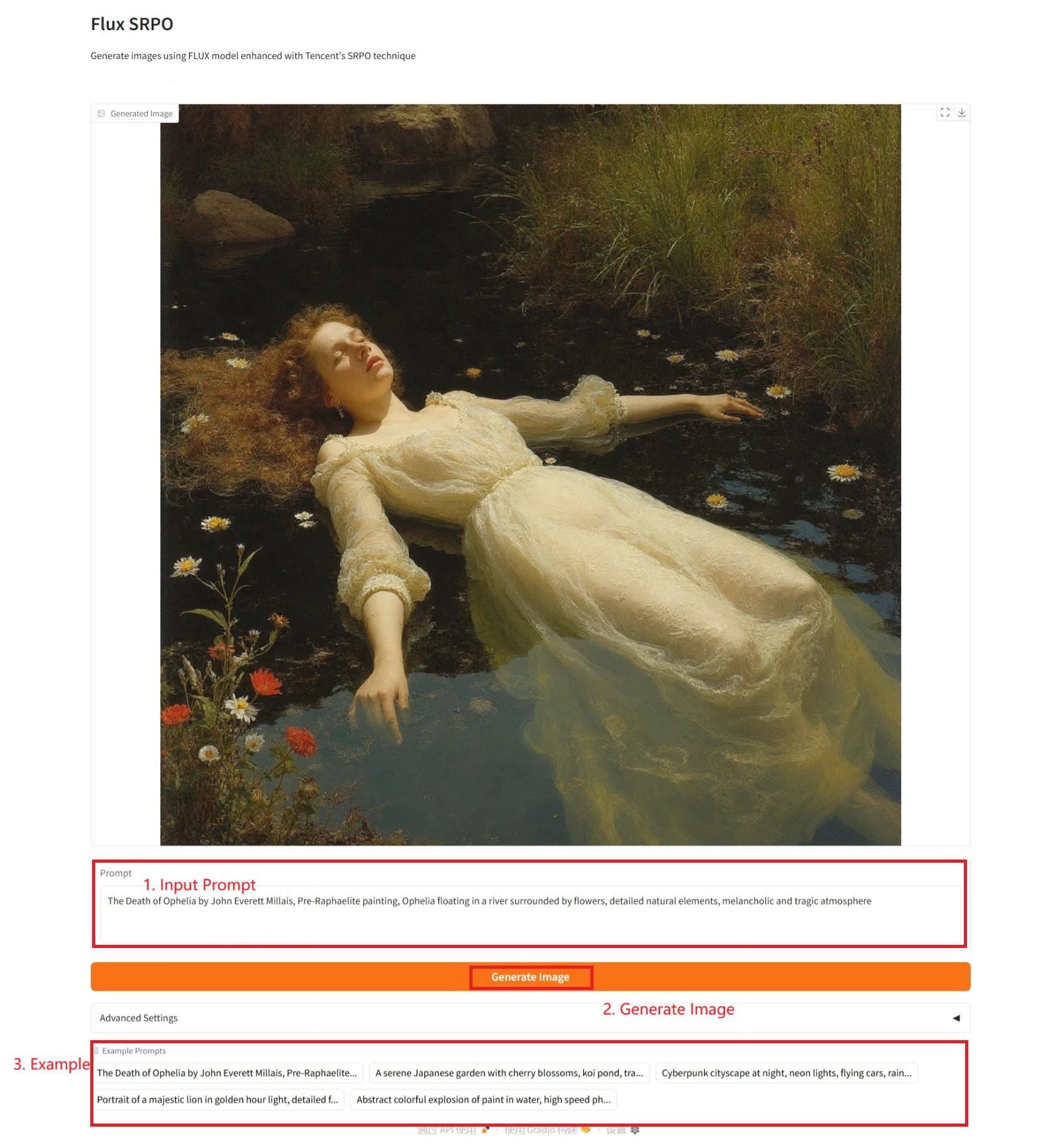
具体参数:
- Prompt:这里可以输入文本描述。
- Width:图片宽。
- Height:图片高。
- Guidance Scale:引导尺度,用于控制生成图像过程中文本提示(prompt)对最终结果的影响程度。
- Inference Steps:推理步数,控制生成过程的迭代次数,影响生成质量和计算时间。
- Seed:随机数种子,用于控制随机性生成过程的初始值。
- Seed Used:使用的种子。
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@misc{shen2025directlyaligningdiffusiontrajectory,
title={Directly Aligning the Full Diffusion Trajectory with Fine-Grained Human Preference},
author={Xiangwei Shen and Zhimin Li and Zhantao Yang and Shiyi Zhang and Yingfang Zhang and Donghao Li and Chunyu Wang and Qinglin Lu and Yansong Tang},
year={2025},
eprint={2509.06942},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2509.06942},
}
该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。