HyperAI
Command Palette
Search for a command to run...
Nanonets-OCR-s:文档信息提取和基准测试工具
一、教程简介

Nanonets-OCR-s 是由 Nanonets 于 2025 年 6 月 10 日发布的光学字符识别(OCR)模型。普通的 OCR 技术主要聚焦于从图像中提取纯文本,而 Nanonets-OCR-s 更进一步,它能识别文档中的多种元素,比如数学公式、图片、签名、水印、复选框和表格,并将它们整理成结构化的 Markdown 格式。这种能力让它在处理复杂文档时表现出色,比如学术论文、法律文件或商业报表。它的输出不仅便于人类阅读,还为下游的自动化处理提供了坚实基础。
本教程采用资源为单卡 RTX 4090 。该教程包含两个功能:1 、从文档中提取信息。 2 、图像和 PDF 转成 Markdown 。
二、项目示例
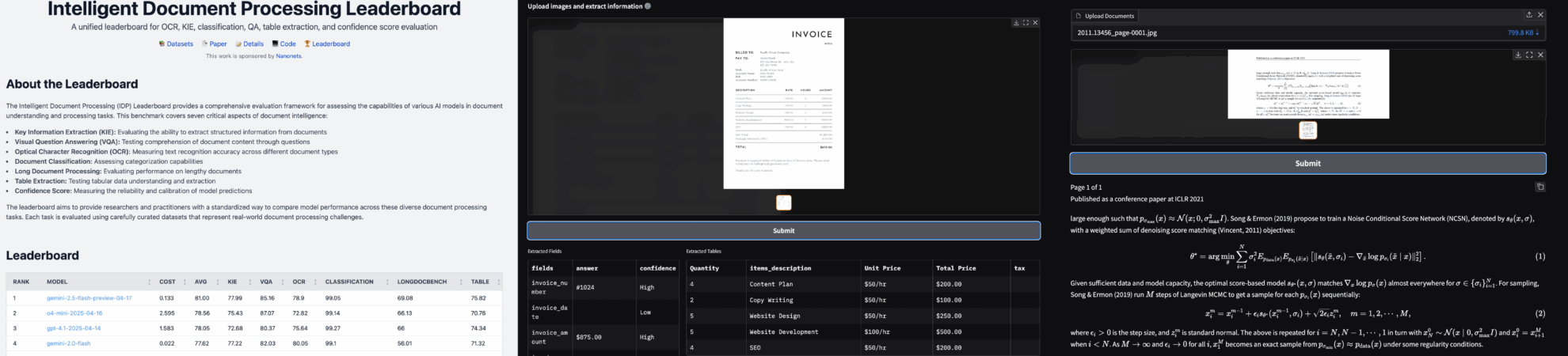
三、运行步骤
1. 启动容器后点击 API 地址即可进入 Web 界面
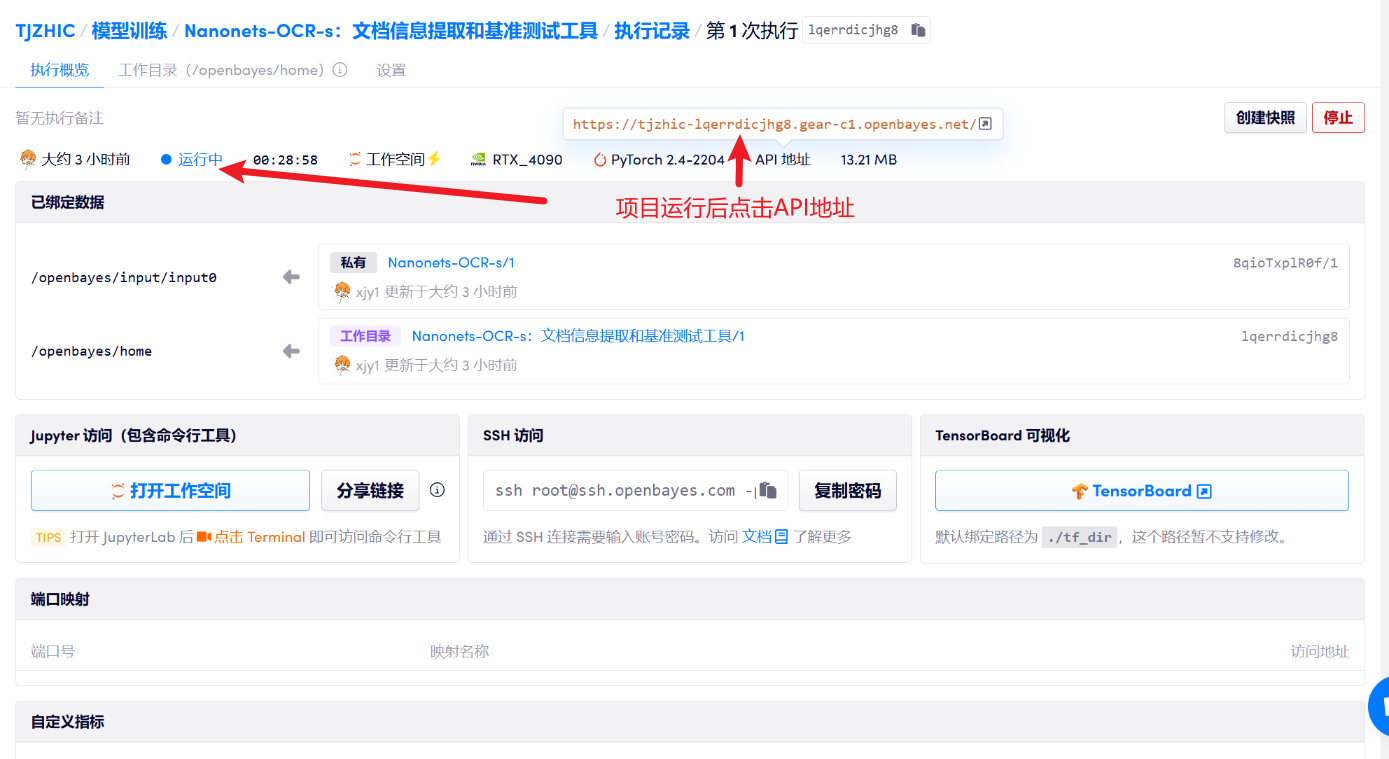
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。
2.1 从文档中提取信息
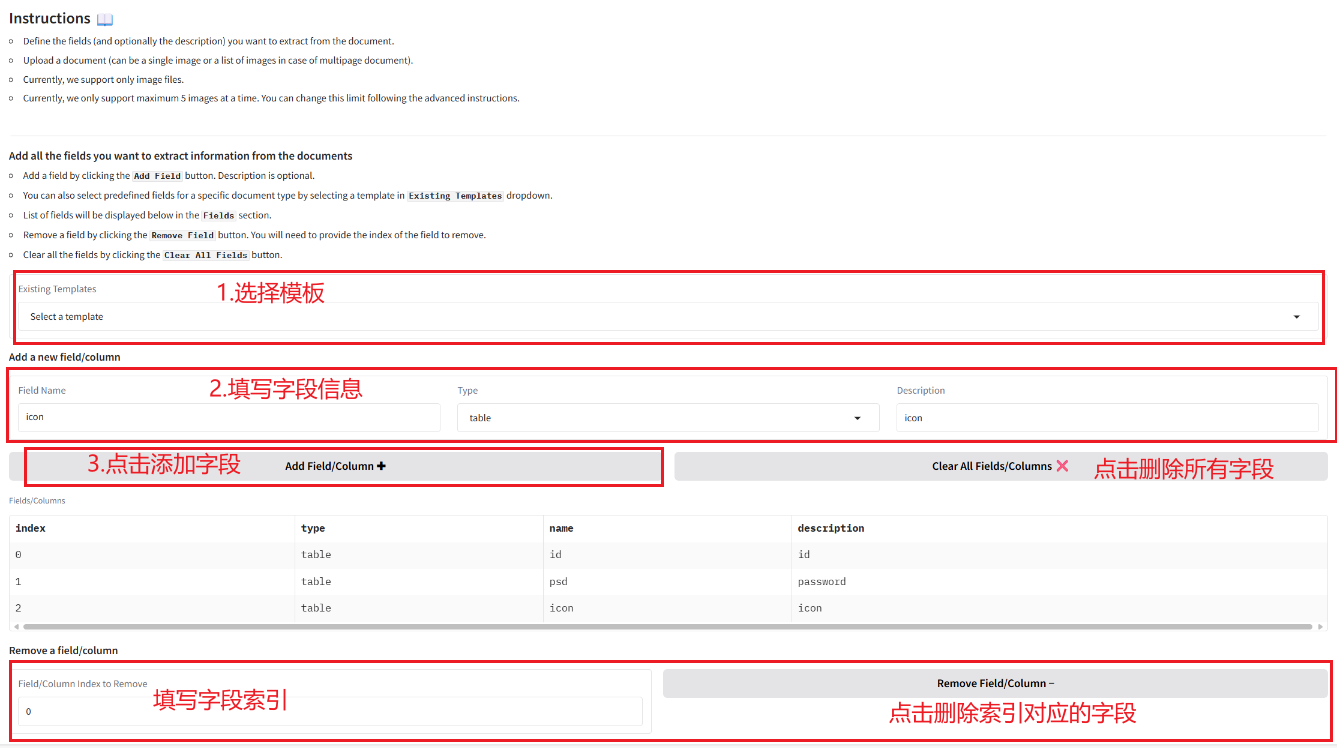
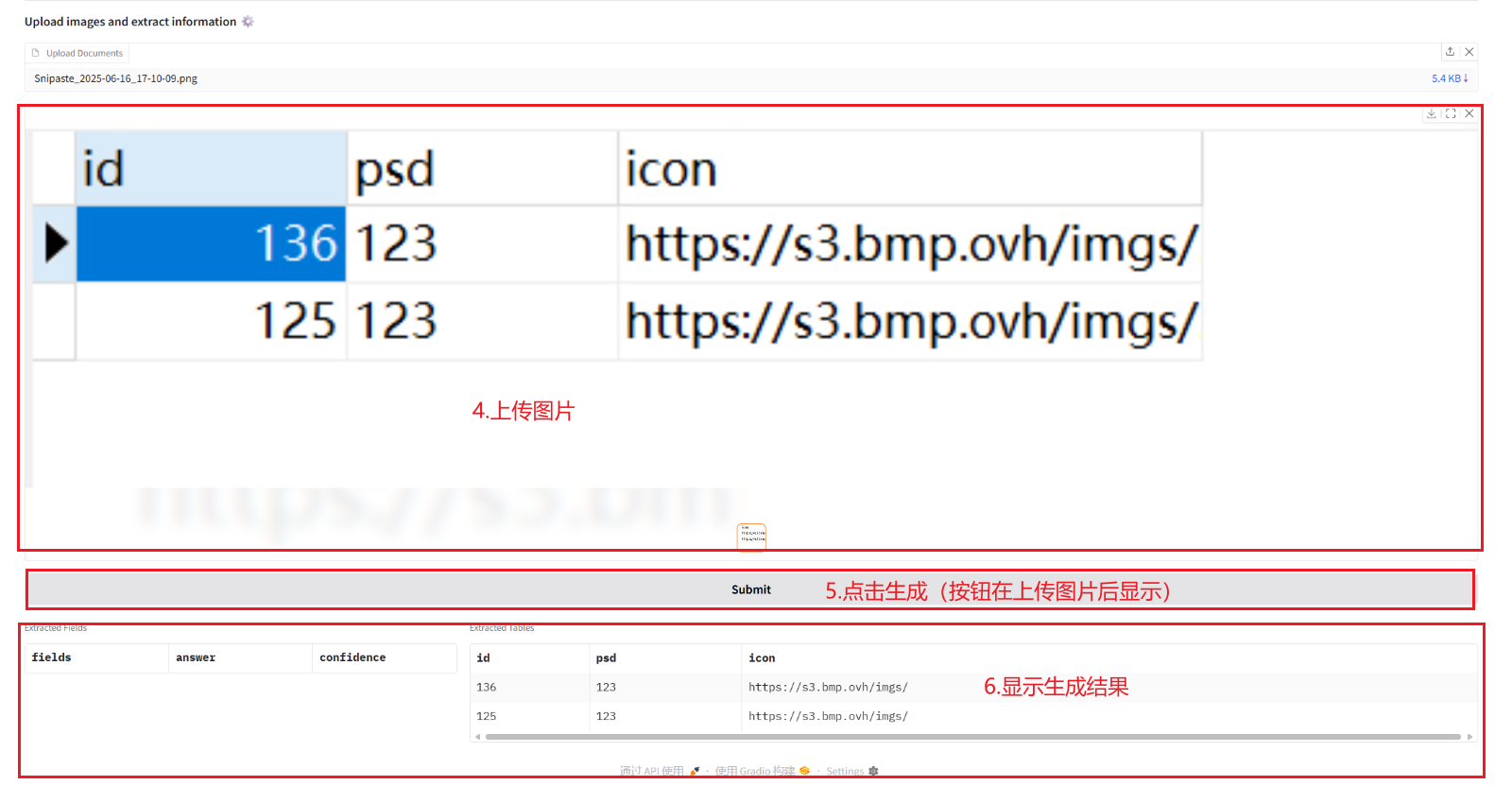
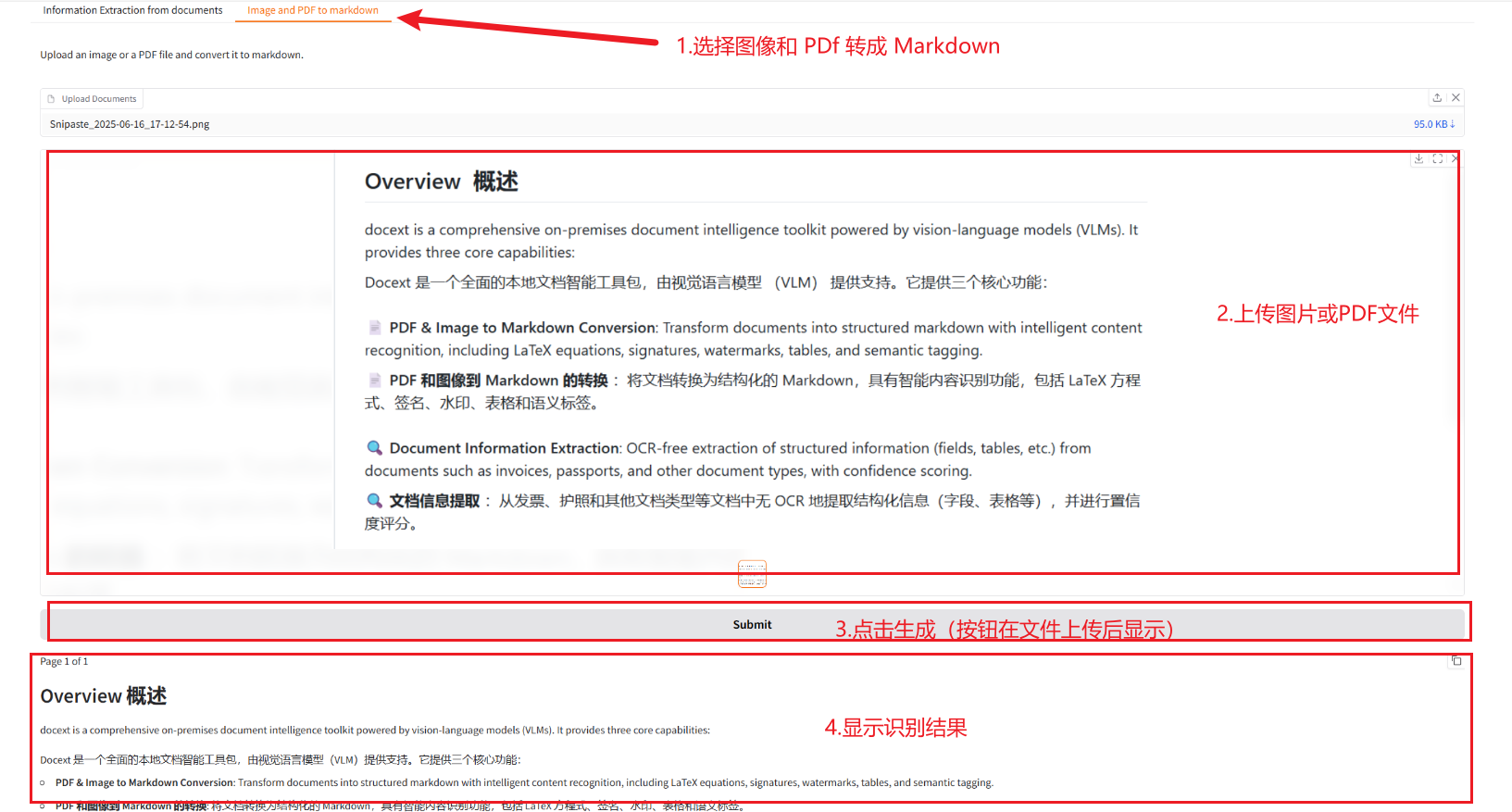
2.2 图像和 PDF 转成 Markdown
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。