HyperAI
Command Palette
Search for a command to run...
MonkeyOCR:基于结构-识别-关系三元组范式的文档解析
一、教程简介

MonkeyOCR 是由华中科技大学联合金山办公(Kingsoft Office)于 2025 年 6 月 5 日开源的文档解析模型,模型支持高效地将非结构化文档内容转换为结构化信息。基于精确的布局分析、内容识别和逻辑排序,显著提升文档解析的准确性和效率。与传统方法相比,MonkeyOCR 在处理复杂文档(如包含公式和表格的文档)时表现出色,平均性能提升 5.1%,在公式和表格解析上分别提升 15.0% 和 8.6% 。模型在多页文档处理速度上表现出色,达到每秒 0.84 页,远超其他同类工具。 MonkeyOCR 支持多种文档类型,包括学术论文、教科书和报纸等,适用多种语言,为文档数字化和自动化处理提供强大的支持。相关论文成果为 MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm 。
主要功能:
- 文档解析与结构化:将各种格式的文档(如 PDF 、图像等)中的非结构化内容(包括文本、表格、公式、图像等)转换为结构化的机器可读信息。
- 多语言支持:支持多种语言,包括中文和英文。
- 高效处理复杂文档:在处理复杂文档(如包含公式、表格、多栏布局等)时表现出色。
- 快速多页文档处理:高效处理多页文档,处理速度达到每秒 0.84 页,显著优于其他工具(如 MinerU 每秒 0.65 页 Qwen2.5-VL-7B 每秒 0.12 页)。
- 灵活的部署与扩展:支持在单个 NVIDIA 3090 GPU 上高效部署,满足不同规模的需求。
技术原理:
- 结构-识别-关系(SRR)三元组范式:基于 YOLO 的文档布局检测器,识别文档中的关键元素(如文本块、表格、公式、图像等)的位置和类别。对每个检测到的区域进行内容识别,用大型多态模型(LMM)进行端到端的识别,确保高精度。基于块级阅读顺序预测机制,确定检测到的元素之间的逻辑关系,重建文档的语义结构。
- MonkeyDoc 数据集:MonkeyDoc 是迄今为止最全面的文档解析数据集,包含 390 万个实例,涵盖中文和英文的十多种文档类型。数据集基于多阶段管道构建,整合精心的手动标注、程序化合成和模型驱动的自动标注。用在训练和评估 MonkeyOCR 模型,确保在多样化和复杂的文档场景中具有强大的泛化能力。
- 模型优化与部署:用 AdamW 优化器和余弦学习率调度,结合大规模数据集进行训练,确保模型在精度和效率之间的平衡。基于 LMDeplov 工具,MonkeyOCR 能在单个 NVIDIA 3090 GPU 上高效运行,文持快速推理和大规模部署。
该教程算力资源采用单卡 RTX 5090 。
二、效果展示
公式文档示例

表格文档示例

报纸示例

财务报告示例


三、运行步骤
1. 启动容器
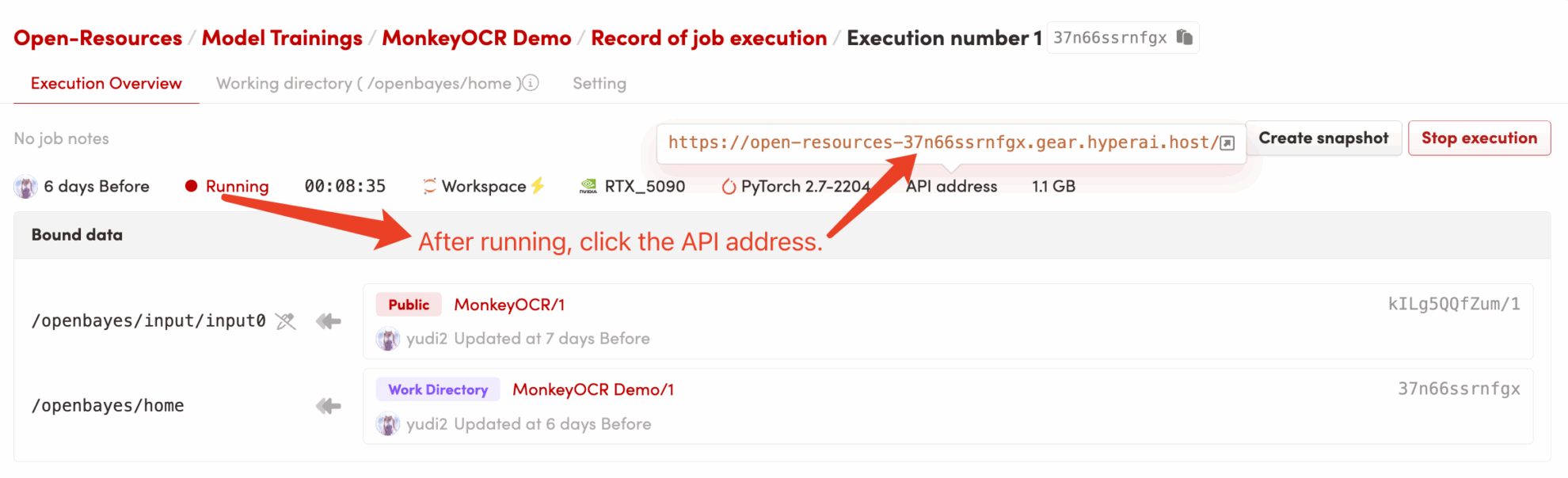
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。

引用信息
本项目引用信息如下:
@misc{li2025monkeyocrdocumentparsingstructurerecognitionrelation,
title={MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm},
author={Zhang Li and Yuliang Liu and Qiang Liu and Zhiyin Ma and Ziyang Zhang and Shuo Zhang and Zidun Guo and Jiarui Zhang and Xinyu Wang and Xiang Bai},
year={2025},
eprint={2506.05218},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05218},
}
本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。