HyperAI
Command Palette
Search for a command to run...
YOLOE:实时看见一切
一、教程简介

YOLOE 是由清华大学研究团队于 2025 年提出的一种新型实时视觉模型,旨在实现「实时看见一切」的目标。它继承了 YOLO 系列模型的实时高效特性,并在此基础上深度融合了零样本学习与多模态提示能力,能够支持文本、视觉和无提示等多种场景下的目标检测与分割。相关论文成果为 YOLOE: Real-Time Seeing Anything 。
YOLO (You Only Look Once) 自 2015 年推出以来,一直是目标检测和图像分割领域的佼佼者。以下是 YOLO 系列的演进历程及相关教程:
- YOLOv2 (2016):引入批量归一化、锚框和维度集群。
- YOLOv3 (2018):使用更高效的骨干网络、多锚和空间金字塔池。
- YOLOv4 (2020):引入 Mosaic 数据增强、无锚检测头和新的损失函数。→ 教程:DeepSOCIAL 基于 YOLOv4 与 sort 多目标跟踪实现人群距离监测
- YOLOv5 (2020):增加超参数优化、实验跟踪和自动导出功能。→ 教程:YOLOv5_deepsort 实时多目标跟踪模型
- YOLOv6 (2022):美团开源,广泛应用于自主配送机器人。
- YOLOv7 (2022):支持 COCO 关键点数据集的姿势估计。→教程:如何训练和使用自定义的 YOLOv7 模型
- YOLOv8 (2023):Ultralytics 发布,支持全方位的视觉 AI 任务。→ 教程:用自定义数据训练 YOLOv8
- YOLOv9 (2024):引入可编程梯度信息 (PGI) 和广义高效层聚合网络 (GELAN) 。
- YOLOv10 (2024):清华大学推出,引入端到端头,消除非最大抑制 (NMS) 要求。→ 教程:YOLOv10 实时端到端目标检测
- YOLOv11(2024):Ultralytics 最新模型,支持检测、分割、姿态估计、跟踪和分类。→ 教程:一键部署 YOLOv11
- YOLOv12 🚀 NEW(2025):速度与精度双巅峰,结合注意力机制的性能优势!
核心功能
- 任意文本类型

2. 多模态提示:
- 视觉提示(框/点/手绘形状/参考图)

- 全自动无提示检测 – 自动识别场景对象

演示环境:YOLOv8e/YOLOv11e 系列 + RTX4090
二、运行步骤
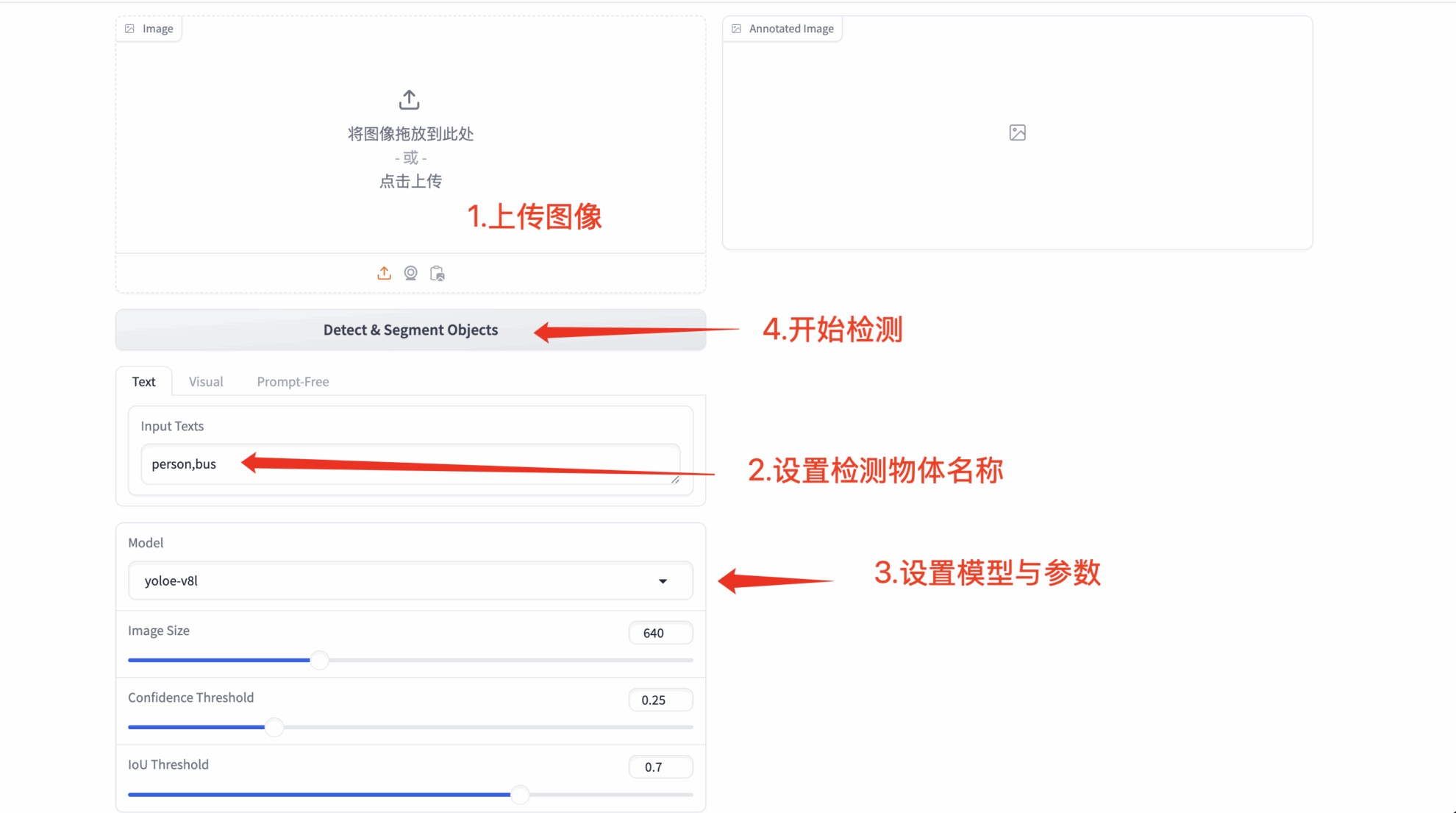
1. 启动容器后点击 API 地址即可进入 Web 界面
若显示「Bad Gateway」,这表示模型正在初始化,请等待约 1-2 分钟后刷新页面。

2.YOLOE 功能演示
1. 文本提示检测
- 任意文本类型
- 自定义提示词:允许用户输入任意文本(识别效果可能因语义复杂度而异)

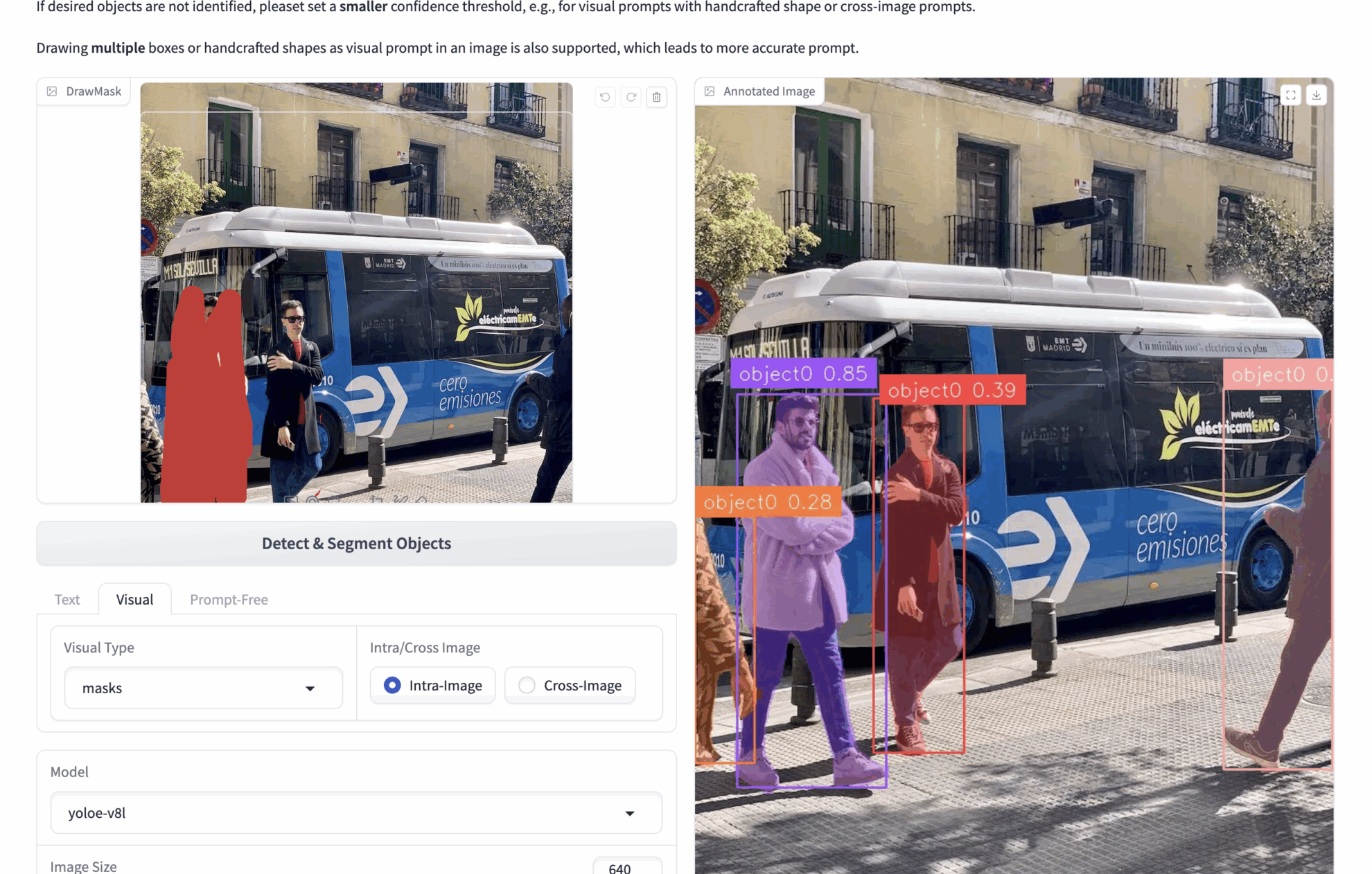
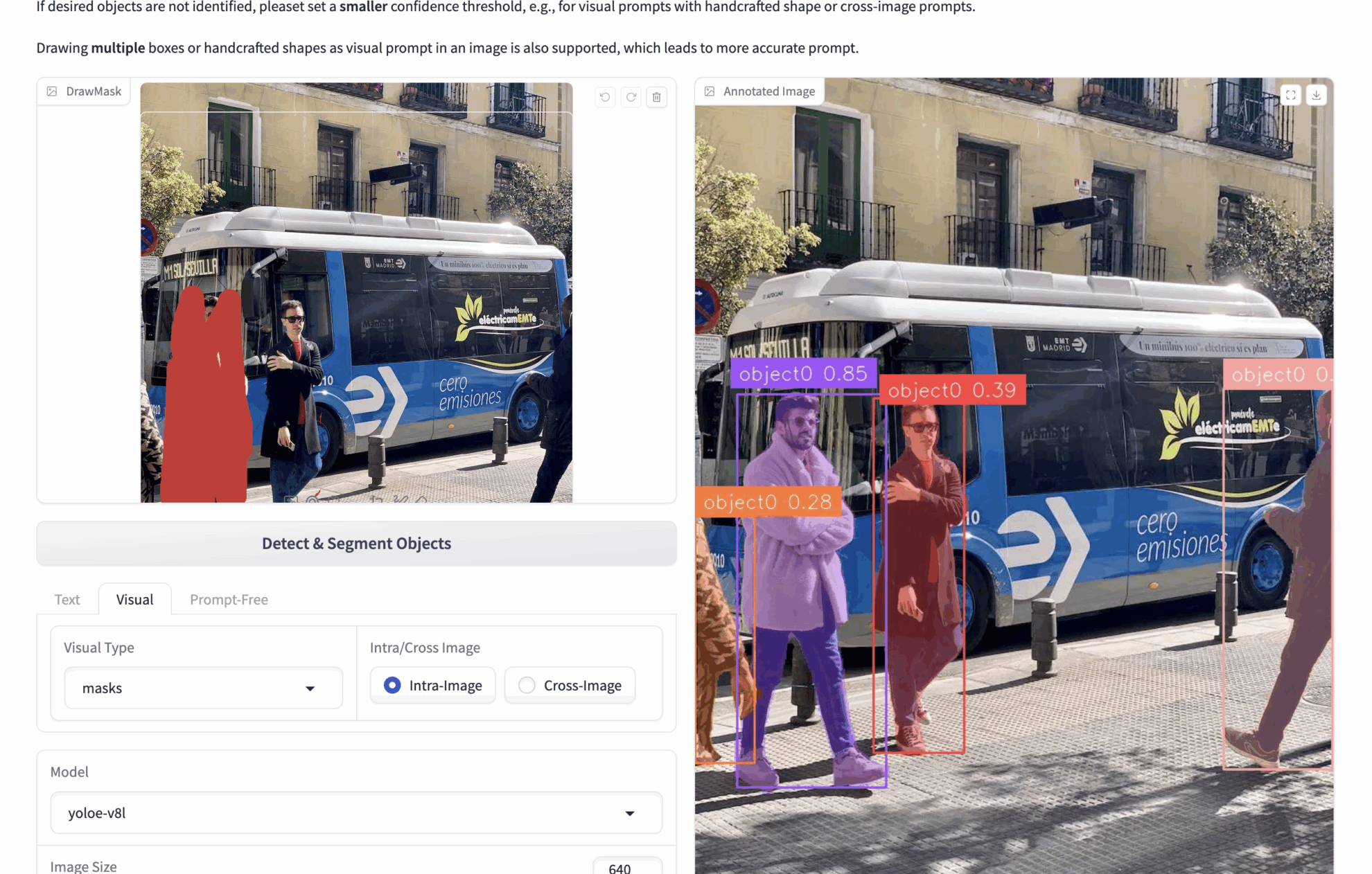
2. 多模态视觉提示
- 🟦 框选检测 (bboxes)
bboxes:例如上传一个包含很多人的图像,想检测人的图像,使用 bboxes 将一个人框起上,推理时模型就会根据 bboxes 的内容识别图像中所有的人。
可以画多个 bboxes,以便得到更准确的视觉提示。 - ✏️ 点选/手绘区域 (masks)
masks:例如上传一个包含很多人的图像,想检测人的图像,使用 masks 将一个人涂抹,推理时模型就会根据 masks 的内容识别图像中所有的人。
可以画多个 masks,以便得到更准确的视觉提示。 - 🖼️ 参考图比对 (Intra/Cross)
Intra:在当前图像上操作 bboxes 或者 masks,并在当前图像上推理。
Cross:在当前图像上操作 bboxes 或者 masks,并在其他图像上推理。
核心概念
| 模式 | 功能说明 | 应用场景 |
|---|---|---|
| Intra-image | 单图内对象关系建模 | 局部目标精确定位 |
| Cross-image | 跨图像特征匹配 | 相似物体检索 |

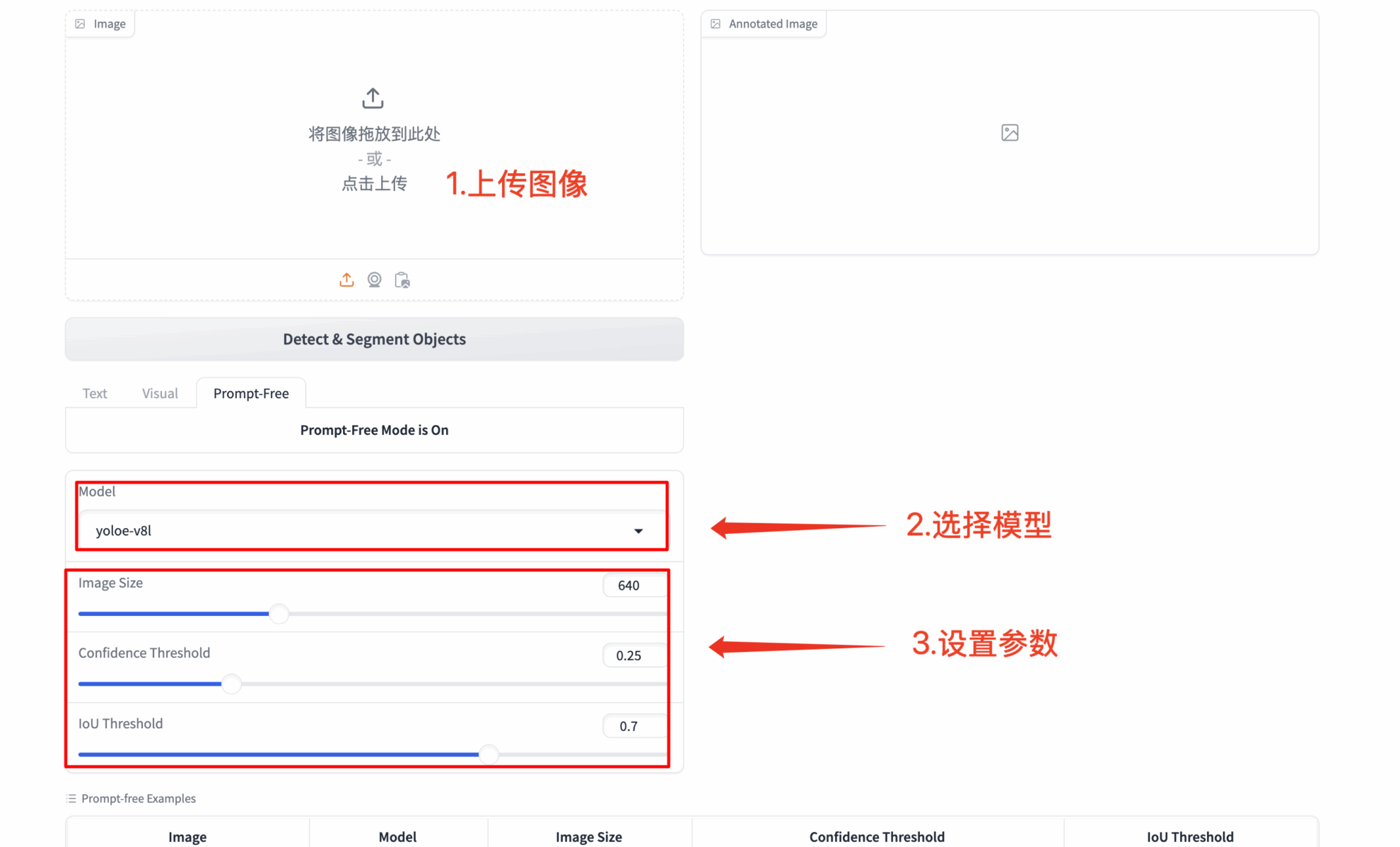
3. 全自动无提示检测
- 🔍 智能场景解析:自动识别图像中全部显著物体
- 🚀 零配置启动:无需任何提示输入即可工作

交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。