HyperAI
Command Palette
Search for a command to run...
一键部署 YOLOv12
一、教程简介📖

YOLOv12 是由布法罗大学和中国科学院大学的研究人员于 2025 年推出,相关论文成果为 YOLOv12: Attention-Centric Real-Time Object Detectors 。
YOLOv12 的突破性表现
- YOLOv12-N 在 T4 GPU 上以 1.64 毫秒 的推理延迟实现了 40.6% 的 mAP,比 YOLOv10-N / YOLOv11-N 高出 2.1%/1.2% 的 mAP 。
- YOLOv12-S 击败了 RT-DETR-R18 / RT-DETRv2-R18,运行速度提高了 42%,计算量仅用了 36%,参数减少了 45% 。
📜 YOLO 发展历程及相关教程
YOLO (You Only Look Once) 自 2015 年推出以来,一直是目标检测和图像分割领域的佼佼者。以下是 YOLO 系列的演进历程及相关教程:
- YOLOv2 (2016):引入批量归一化、锚框和维度集群。
- YOLOv3 (2018):使用更高效的骨干网络、多锚和空间金字塔池。
- YOLOv4 (2020):引入 Mosaic 数据增强、无锚检测头和新的损失函数。→ 教程:DeepSOCIAL 基于 YOLOv4 与 sort 多目标跟踪实现人群距离监测
- YOLOv5 (2020):增加超参数优化、实验跟踪和自动导出功能。→ 教程:YOLOv5_deepsort 实时多目标跟踪模型
- YOLOv6 (2022):美团开源,广泛应用于自主配送机器人。
- YOLOv7 (2022):支持 COCO 关键点数据集的姿势估计。→教程:如何训练和使用自定义的 YOLOv7 模型
- YOLOv8 (2023):Ultralytics 发布,支持全方位的视觉 AI 任务。→ 教程:用自定义数据训练 YOLOv8
- YOLOv9 (2024):引入可编程梯度信息 (PGI) 和广义高效层聚合网络 (GELAN) 。
- YOLOv10 (2024):清华大学推出,引入端到端头,消除非最大抑制 (NMS) 要求。→ 教程:YOLOv10 实时端到端目标检测
- YOLOv11(2024):Ultralytics 最新模型,支持检测、分割、姿态估计、跟踪和分类。→ 教程:一键部署 YOLOv11
- YOLOv12 🚀 NEW(2025):速度与精度双巅峰,结合注意力机制的性能优势!
本教程采用算力资源为 RTX 4090 。
二、运行步骤🛠️
1. 启动容器后点击 API 地址进入 Web 界面

物体检测器的输出是一组包围图像中物体的边框,以及每个边框的类标签和置信度分数。如果您需要识别场景中感兴趣的物体,但又不需要知道物体的具体位置或确切形状,那么物体检测就是一个不错的选择。
分为以下两个功能:
- 图片检测
- 视频检测
2. 图片检测
输入为一张图像,输出带有标签的图像。
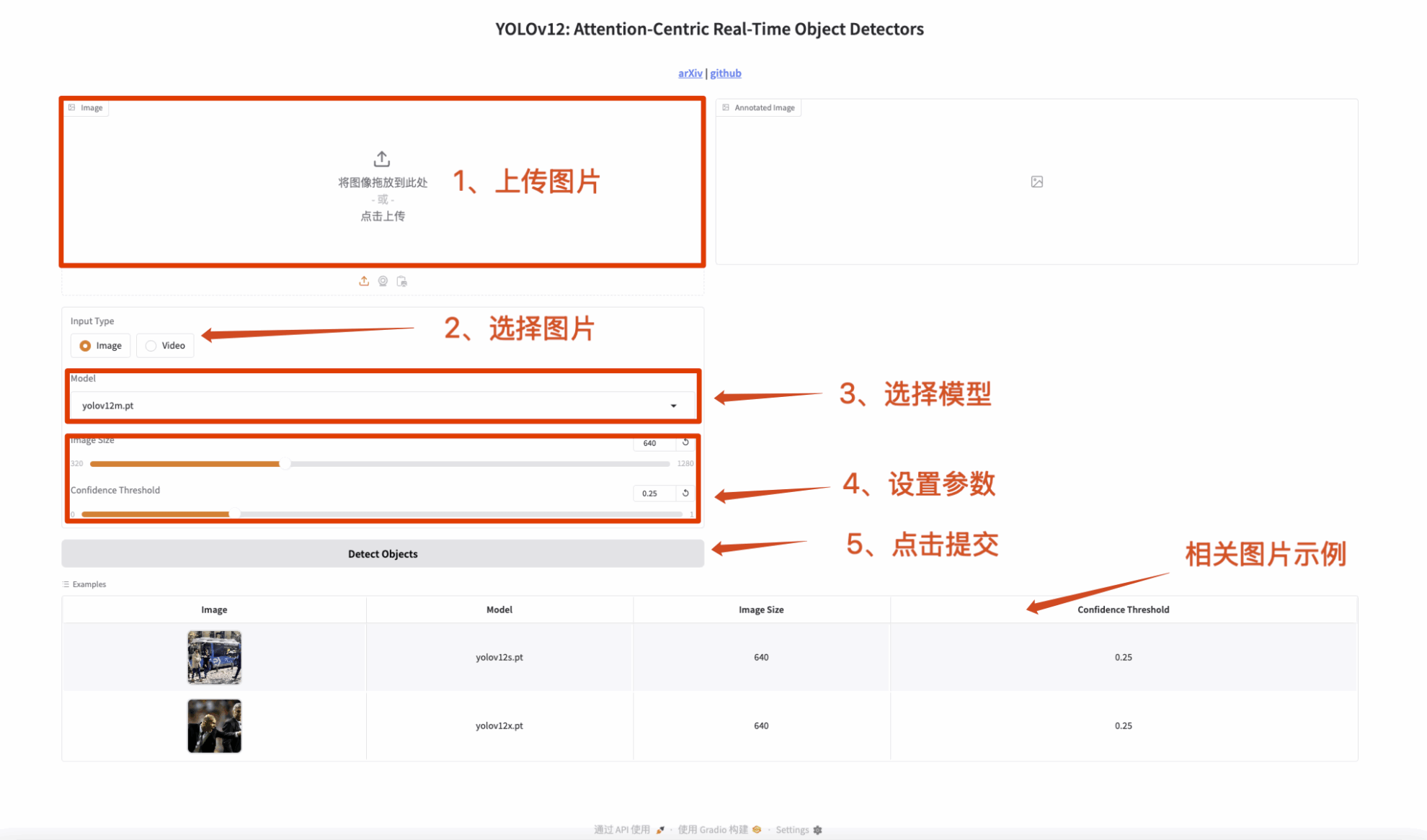

图 1 图片检测
3. 视频检测
输入为一个视频,输出带有标签的视频。
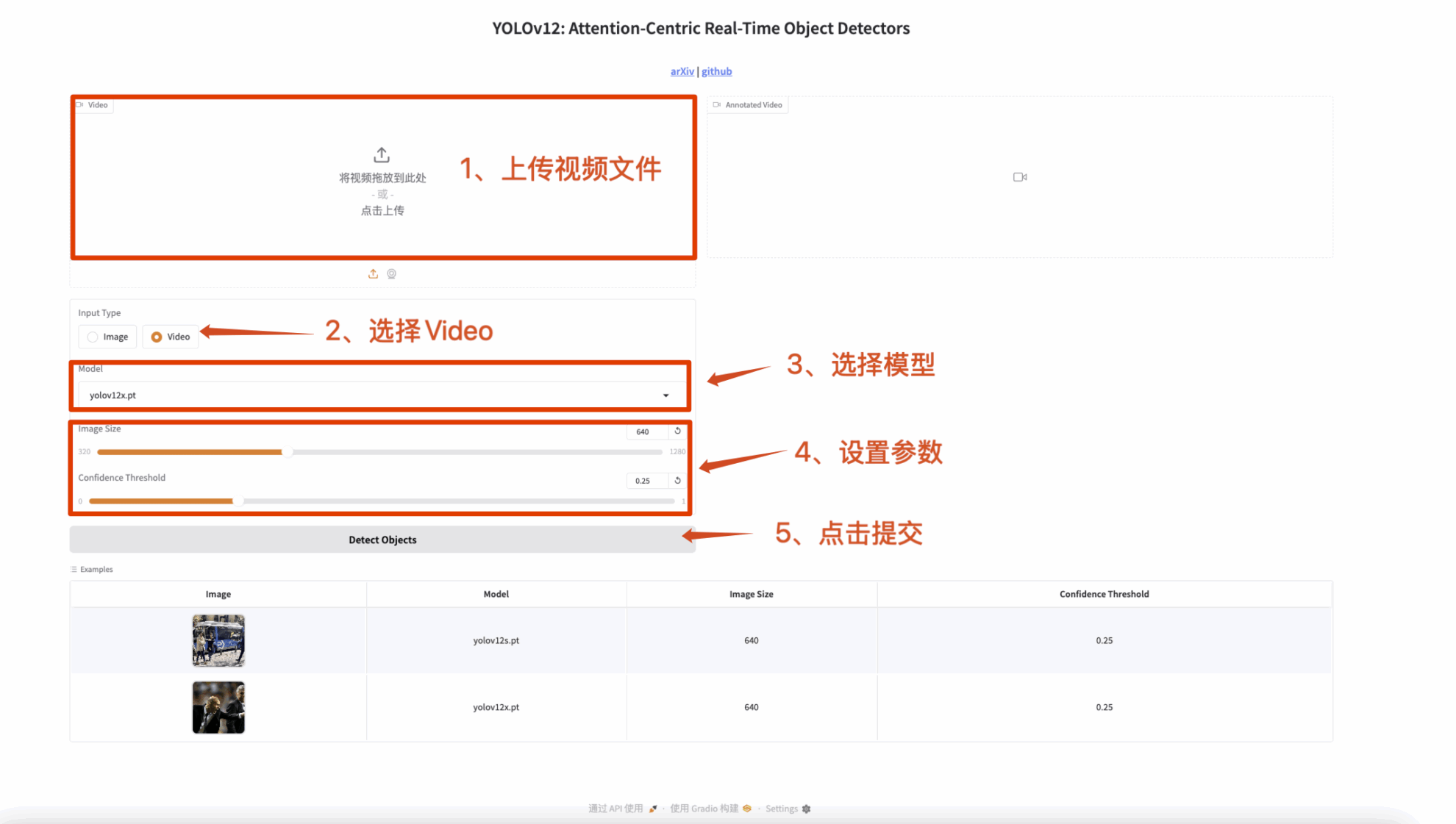
图 2 视频检测
🤝 交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

YOLOv12 不仅是技术的飞跃,更是计算机视觉领域的一次革命!快来体验吧! 🚀
本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。