HyperAI
Command Palette
Search for a command to run...
Allegro 视频生成 Demo

教程简介
该教程至少需要 NVIDIA RTX A6000 48GB 启动。
Allegro 是由 Rhymes AI 于 2024 年研发的尖端文本至视频生成模型,具备将基础文本输入转化为高清晰度视频内容的能力,具体表现为 720p 分辨率、每秒 15 帧的流畅度以及最长 6 秒的视频长度。相关论文成果为 Allegro: Open the Black Box of Commercial-Level Video Generation Model 。 该模型在视频合成领域内展现出卓越的性能,其在质量和时间连贯性方面均表现优异。它能够迅速根据描述性文本生成动态视觉内容,为内容创作者提供了一种既灵活又可控的视频创作途径。 在用户研究中,Allegro 模型展现出的性能超越了现有的开源模型以及大多数商业模型。此外,Allegro 还提供了包括模型扩展、提示精炼适应性以及视频分词器设计在内的增强基础能力的深入见解和指导。这些增强功能共同提升了模型的能力,使其能够根据输入文本的叙事细节生成复杂的视频内容。
该教程为模型推理教程,由于模型生成视频耗时较长,本教程仅可生成 5 秒视频(耗时约 40 分钟)。
运行步骤
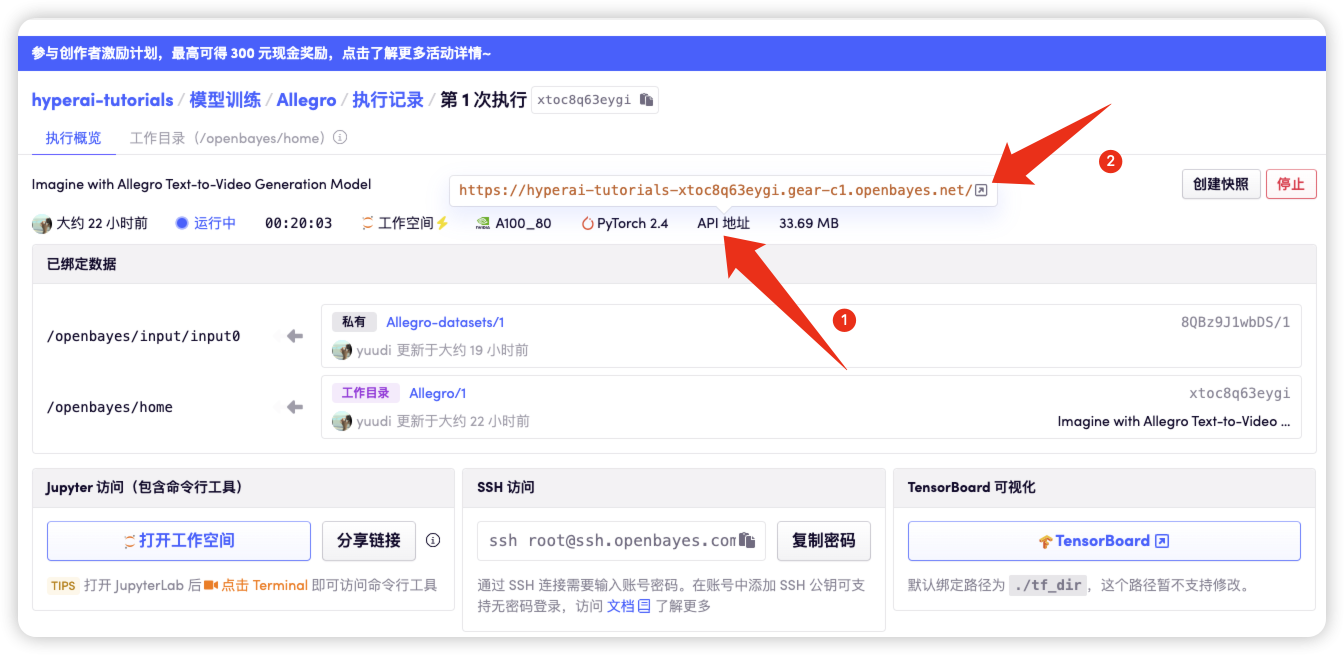
克隆启动容器后点击 API 地址即可进入 Web 界面
1. 文字生成视频
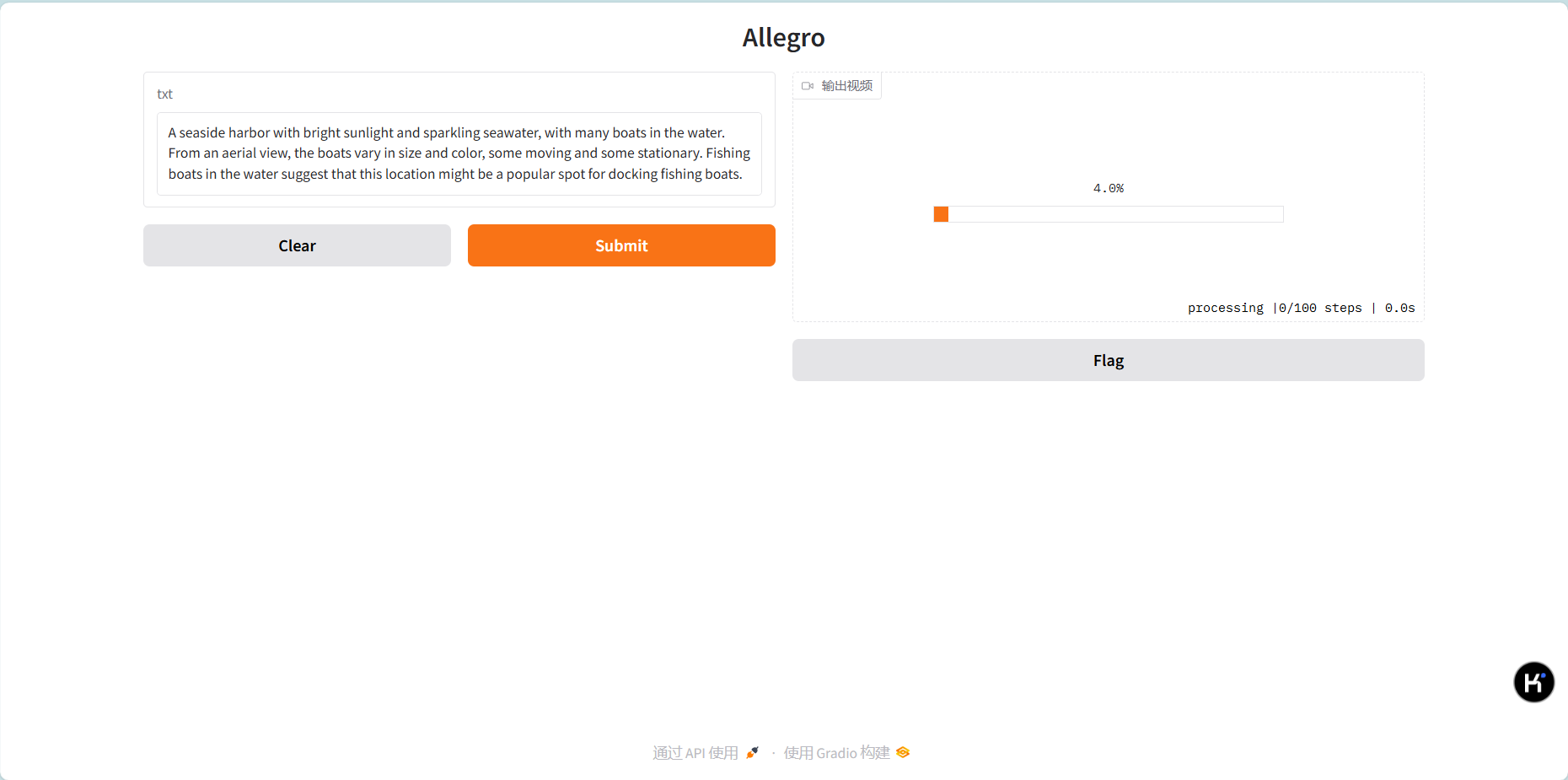
- 输入文本提示词,点击 Submit(启动时会有大概 30s 左右的模型加载时间,之后显示进度条,开始生成视频,生成一段五秒的视频大概需要 40 分钟左右,请大家耐心等待)
如下图所示
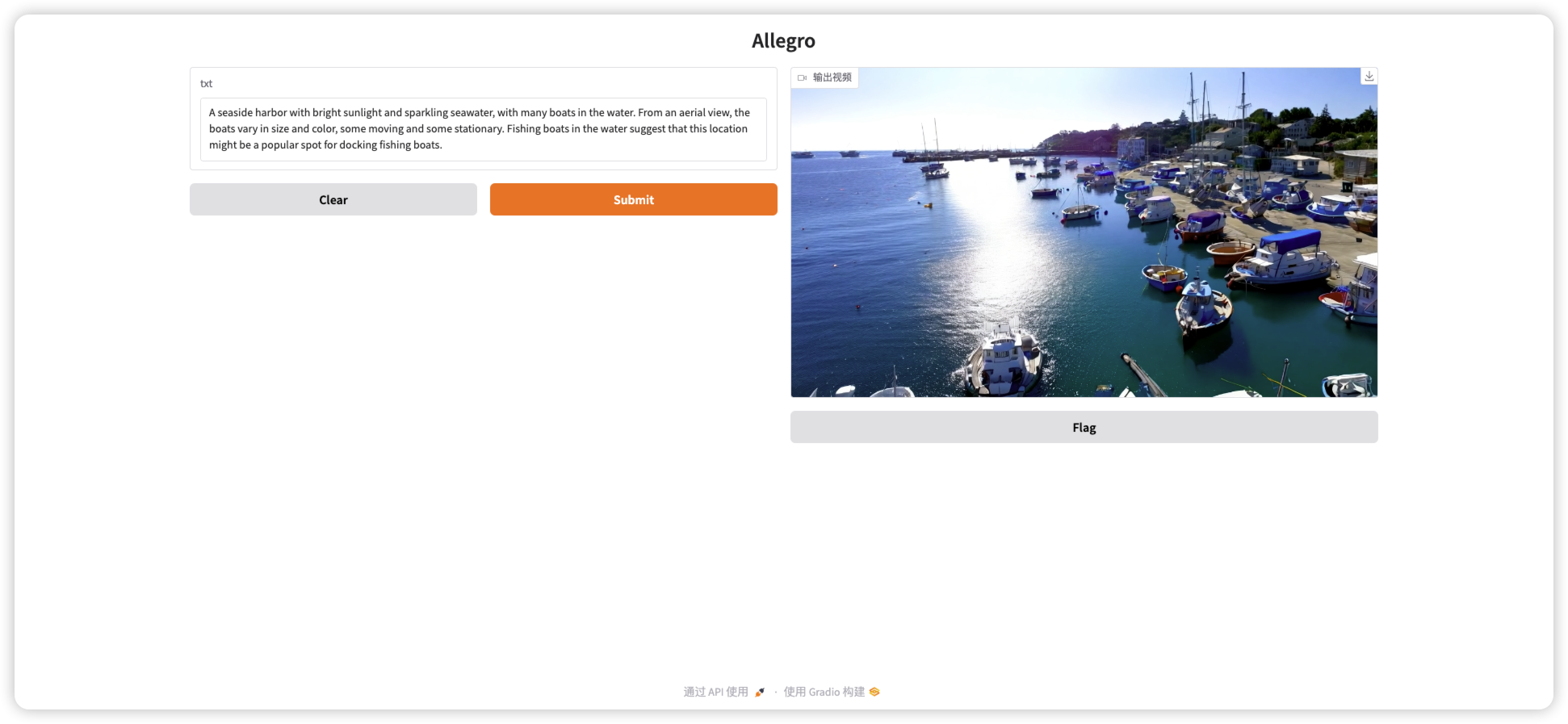
- 当视频生成完成,进度条会自动变为视频进行播放
如下图所示
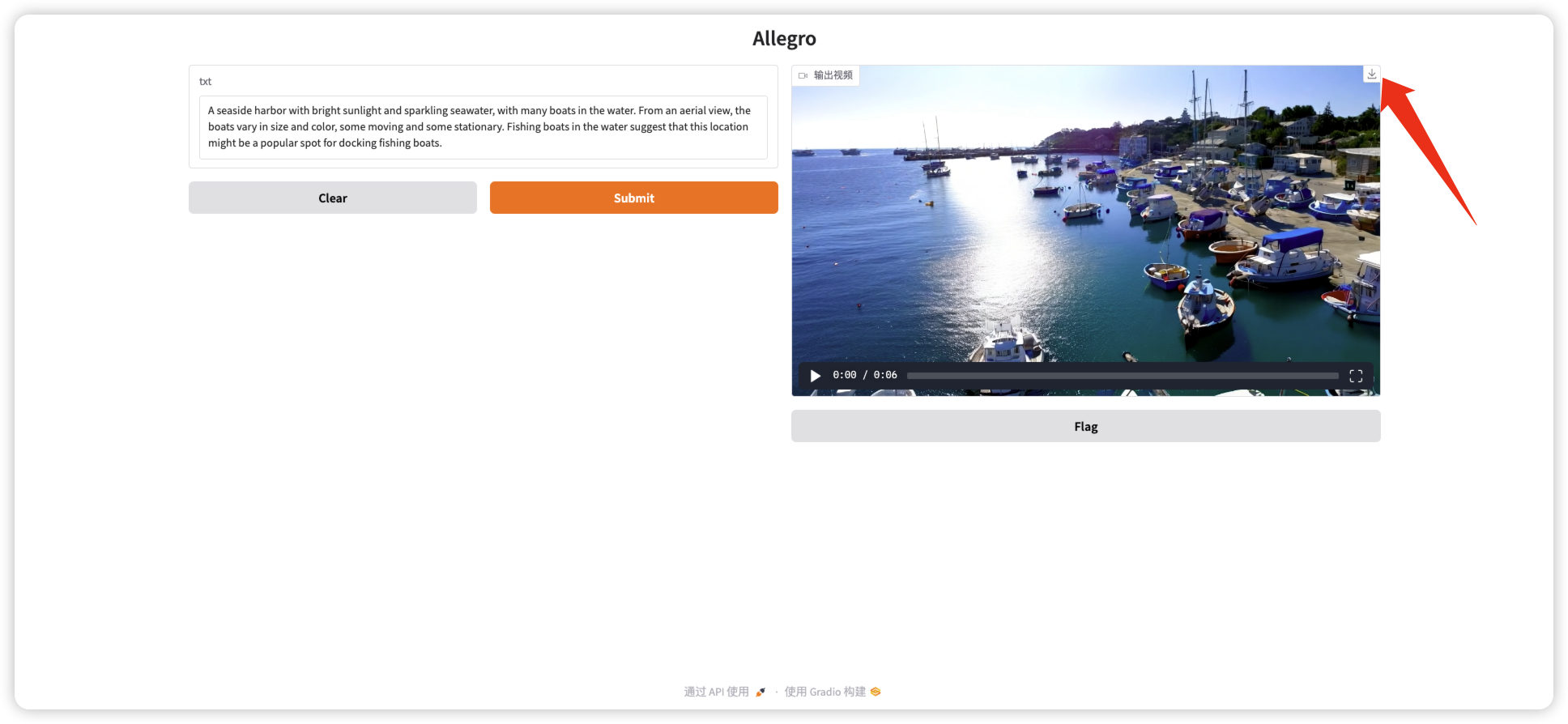
2. 视频下载
- 点击视频右的侧下载按键,即可下载视频。
如下图所示
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。