HyperAI
Command Palette
Search for a command to run...
MinerU 一站式数据提取工具
模型介绍

MinerU 是一款将 PDF 转化为机器可读格式的工具(如 markdown 、 json),可轻松提取为任何格式。支持 176 种语言的准确识别,进行精准的语言类型鉴定。 它专门设计用于将包含图片、公式、表格、脚注等复杂多模态 PDF 文档转化为清晰、易于分析的 Markdown 格式。此外,MinerU 也支持从包含广告等干扰信息的网页、电子书中快速解析和抽取正式内容,从而有效提高 AI 语料的准备效率。
主要功能
- 删除页眉、页脚、脚注、页码等元素,保持语义连贯
- 对多栏输出符合人类阅读顺序的文本
- 保留原文档的结构,包括标题、段落、列表等
- 提取图像、图片标题、表格、表格标题
- 自动识别文档中的公式并将公式转换成 latex
- 自动识别文档中的表格并将表格转换成 latex
- 乱码 PDF 自动检测并启用 OCR
- 支持 CPU 和 GPU 环境
- 支持 windows/linux/mac 平台
部署推理步骤
本教程已经将模型与环境部署完毕,大家可根据教程指引直接使用大模型进行推理对话。具体教程如下:
1. 模型配置
待资源配置后启动容器,点击 API 地址处的连接进入 Demo 界面
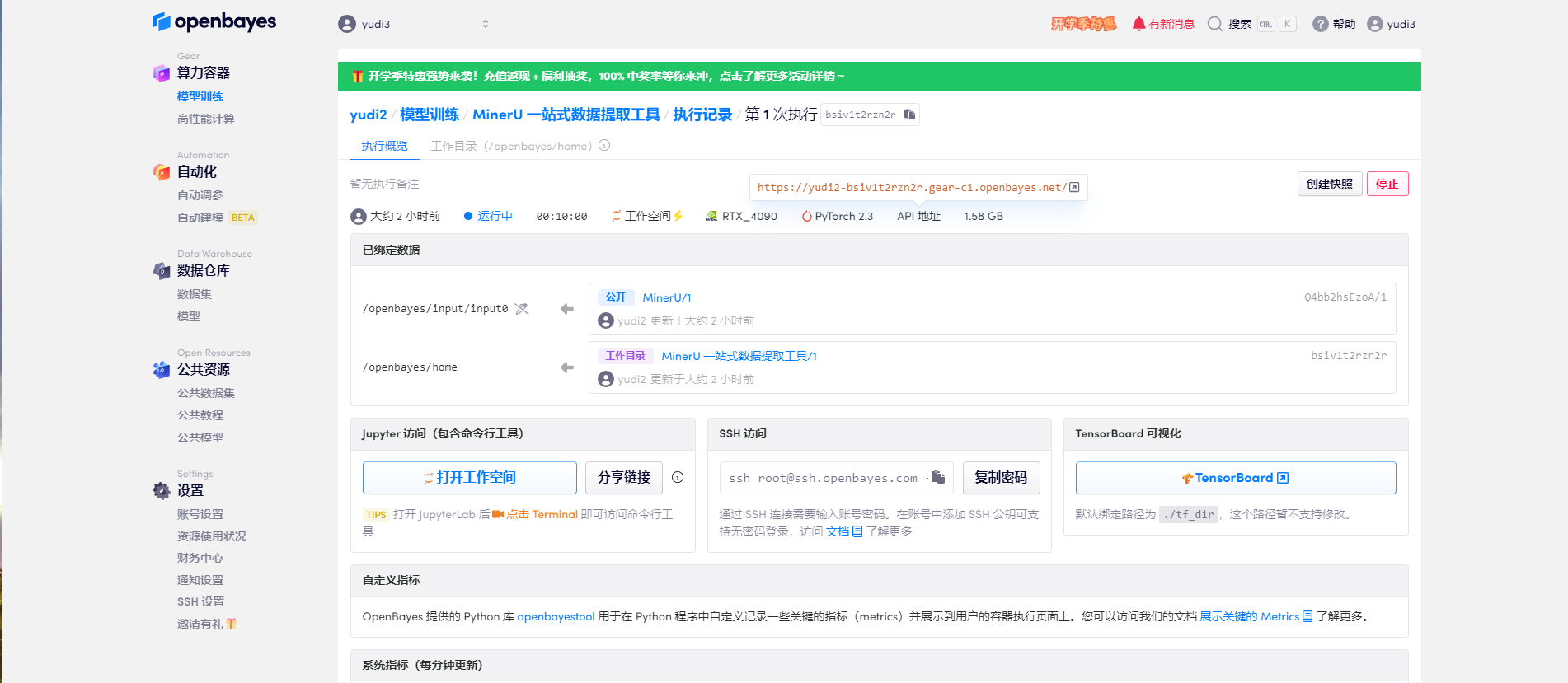
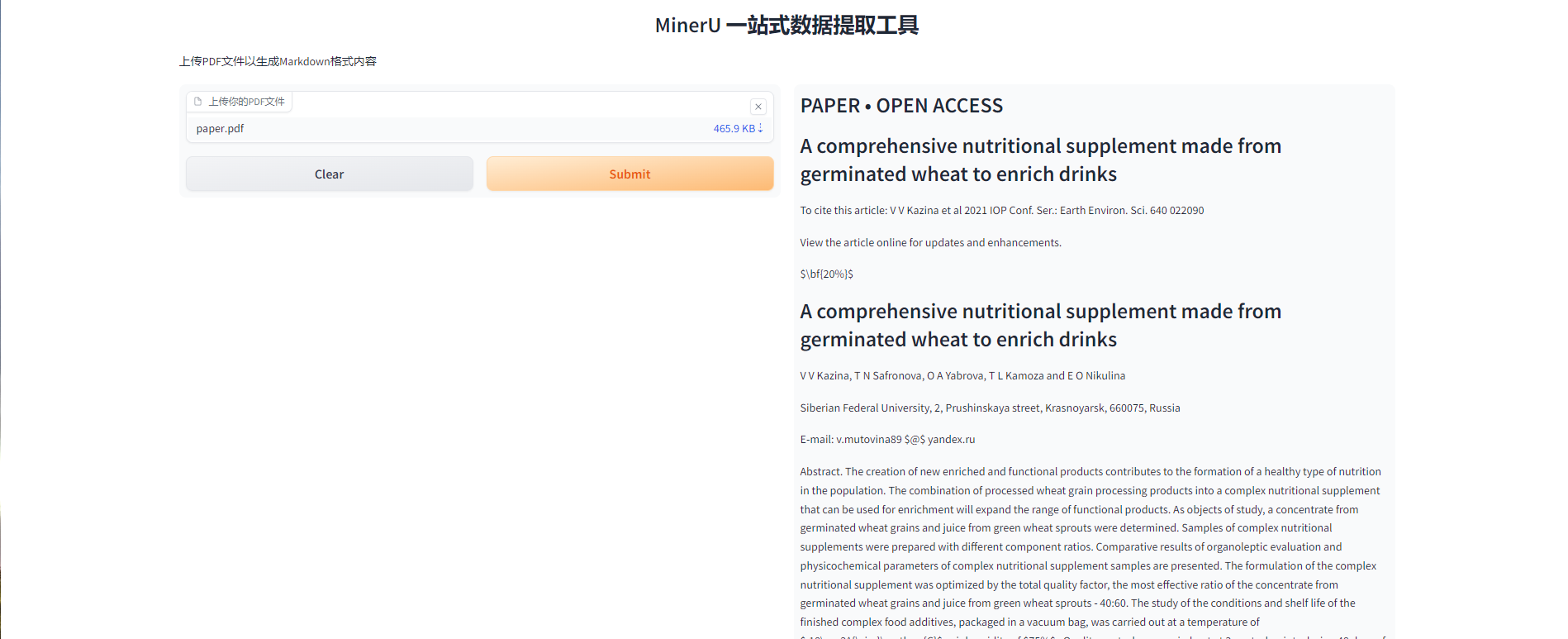
2. 打开界面
稍等片刻后可以看到模型的界面,此时我们就可以使用模型了。用户可上传需要提取的 pdf 文件(注意不要大于 5 mb),点击 submit 按钮模型便可以开始提取。在 gradio 界面中也提供了一个示例文件 paper.pdf 供用户体验模型。(该文件的提取时间大约在 110s 左右)
本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。