Command Palette
Search for a command to run...
和谐:通过跨任务协同实现音频与视频生成的协同统一
和谐:通过跨任务协同实现音频与视频生成的协同统一
Teng Hu Zhentao Yu Guozhen Zhang Zihan Su Zhengguang Zhou Youliang Zhang Yuan Zhou Qinglin Lu Ran Yi
摘要
在生成式人工智能领域,同步音视频内容的合成是一项关键挑战,开源模型在实现稳健的音视频对齐方面仍面临诸多困难。我们的分析表明,这一问题根源在于联合扩散过程中的三个根本性挑战:(1)对应漂移(Correspondence Drift),即同时演化的噪声潜在表示阻碍了对齐关系的稳定学习;(2)全局注意力机制效率低下,难以捕捉细粒度的时间线索;(3)传统无分类器引导(Classifier-Free Guidance, CFG)存在的模态内偏差,虽增强了条件生成能力,却未能有效促进跨模态同步。为克服上述挑战,我们提出了一种名为 Harmony 的新框架,通过机制化手段强制实现音视频同步。首先,我们设计了一种跨任务协同训练范式(Cross-Task Synergy Training),利用音频驱动视频生成与视频驱动音频生成任务所提供的强监督信号,有效缓解对应漂移问题。其次,我们构建了一个全局-局部解耦交互模块(Global-Local Decoupled Interaction Module),实现高效且精确的时间风格对齐。最后,我们提出一种新型的同步增强型无分类器引导机制(Synchronization-Enhanced CFG, SyncCFG),在推理阶段显式分离并放大对齐信号。大量实验表明,Harmony 在生成质量与音视频同步精度方面均达到新的最先进水平,显著优于现有方法,尤其在实现细粒度音视频同步方面表现突出,为生成式多模态内容合成树立了新标杆。
总结
来自上海交通大学和腾讯混元的研究人员推出了 Harmony,这是一个用于同步视听合成的生成框架,通过采用跨任务协同训练范式、全局-局部解耦交互模块和同步增强 CFG,克服了对齐漂移和注意力效率低下的问题,实现了最先进的保真度和时间精度。
简介
音视频的统一合成是生成式 AI 的一个关键前沿领域,对于创建沉浸式数字虚拟人和虚拟世界至关重要。虽然像 Sora 2 这样的专有模型提供了高保真度的结果,但开源社区在实现精确的视听对齐方面面临着重大障碍。现有的方法往往难以有效地同步人类语音与环境声音,这主要是由于“对应漂移”现象,即模型在早期扩散阶段无法对齐两个同时演变且充满噪声的模态。此外,标准架构经常将全局风格一致性与帧级时序混淆,导致口型同步效果差和视听体验脱节。
为了解决这些差距,作者推出了 Harmony,这是一个联合音视频生成框架,旨在生成从环境噪音到人类语音的高度同步内容。
作者利用三项核心创新来实现这种稳定性:
- 跨任务协同 (Cross-Task Synergy): 一种训练范式,将联合生成与辅助的音频驱动及视频驱动任务共同训练,利用强监督信号来防止对应漂移并注入鲁棒的对齐先验。
- 全局-局部解耦交互 (Global-Local Decoupled Interaction): 一个将全局风格注意力与局部帧级注意力分离的模块,确保模型既能捕捉整体情感基调,又能实现精确的时间同步,而无需顾此失彼。
- 同步增强 CFG (SyncCFG): 一种新颖的推理技术,重新定义了负向调节——使用静音音频或静态视频——以显式放大负责视听对齐的引导向量。
数据集
训练数据构成与处理
- 源素材: 作者汇编了一个包含超过 400 万个视听片段的多样化语料库,涵盖了人类语音和环境声音。
- 数据来源: 该数据集聚合了包括 OpenHumanVid、AudioCaps 和 WavCaps 在内的公共来源,并辅以精选的高质量内部集合。
- 标注: 为了确保这些不同来源之间的一致性,所有数据均使用 Gemini 进行了统一标注。
训练策略
- 课程学习: 模型使用三阶段课程进行训练:
- 利用整个音频数据集进行基础音频预训练。
- 专门针对多话语语音数据进行音色解耦微调。
- 最终的跨任务联合视听训练,视频分支从 Wan2.2 初始化。
- 超参数: 最终联合阶段使用 128 的批量大小和 1e-5 的学习率训练 10,000 次迭代。
Harmony-Bench 评估数据集 为了严格评估该模型,作者推出了 Harmony-Bench,这是一个包含 150 个测试用例的基准测试,分为三个不同的子集,每个子集 50 项:
- 环境音-视频: 该子集使用合成构建的场景评估非语音声学事件。它以详细的音频和视频说明为条件,测试模型的时间对齐和语义一致性。
- 语音-视频: 旨在评估口型同步和语音保真度,该子集包含 25 个真实世界样本和 25 个 AI 合成样本的平衡组合。它利用英语和中文转录文本以及最少的视频说明,迫使模型直接从文本中推导视觉动态。
- 复杂场景(环境音 + 语音): 该子集代表了具有共现视听事件的最具挑战性的场景。它要求模型同时处理转录文本、环境声音描述和视觉场景描述,以评估声源分离和多模态同步。
方法
作者利用双流潜在扩散框架进行联合音视频合成,其中视频和音频分别被编码为潜在表示 zv 和 za。该模型的核心名为 Harmony,采用多模态扩散 Transformer (MM-DiT) 执行去噪,主要任务是同步音视频的联合生成。模型架构具有用于视频和音频生成的并行分支,其中视频分支采用了预训练的 Wan2.2-5B 模型。音频分支采用对称设计,以语音转录文本 Ts、描述性说明 Ta 和参考音频 Ar 为条件合成音频。这些输入通过多编码器设置进行处理:音频 VAE 将目标和参考音频编码为潜在变量 za 和 zr,而单独的文本编码器——具体为用于 Ts 的语音编码器和用于 Ta 的 T5 编码器——保留了语音精度。在去噪过程中,参考潜在变量 zr 被预置到噪声目标音频潜在变量 za,t 之前,形成复合输入 za,t′,该输入与文本嵌入一起被送入 MM-DiT 以预测噪声。
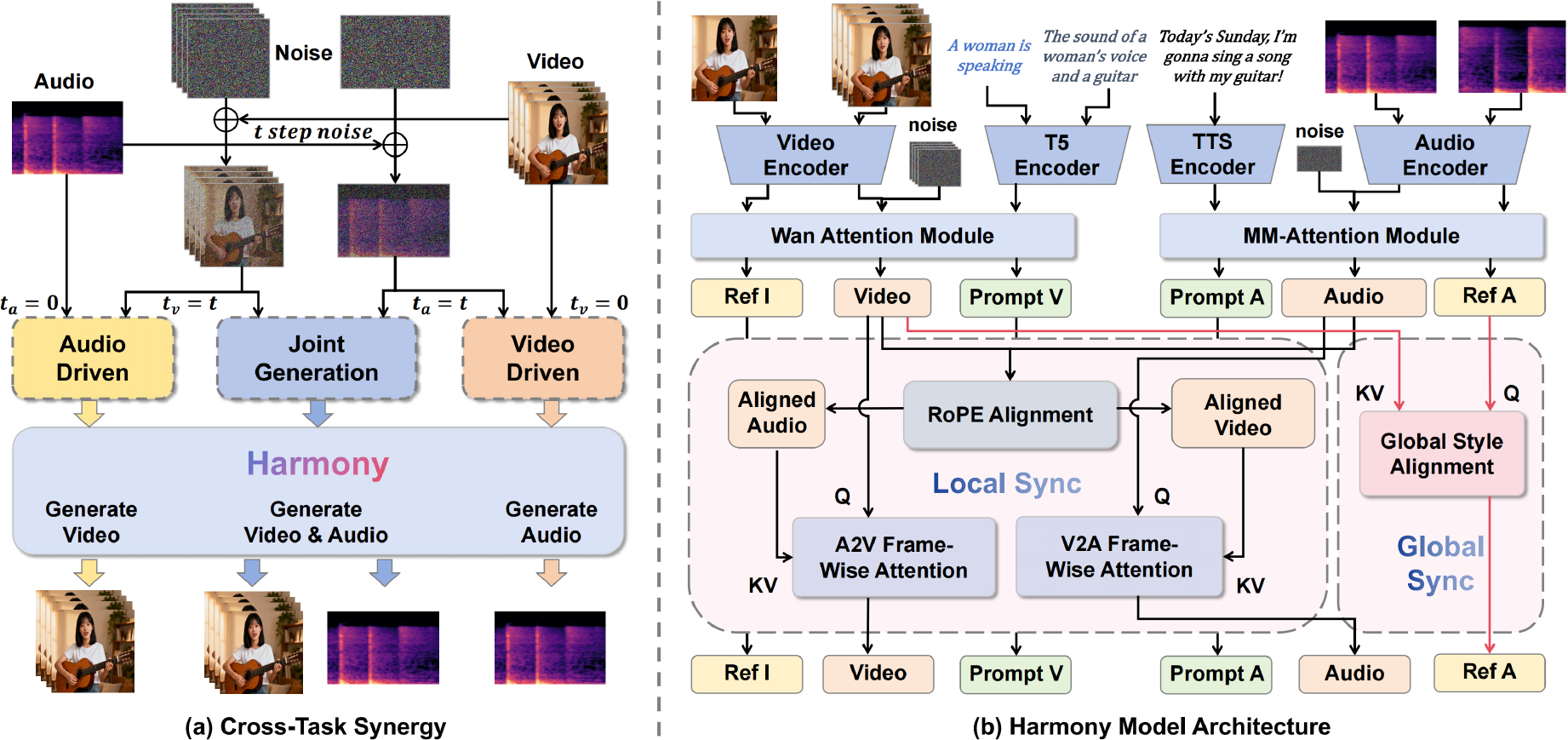
模型的训练由一种称为跨任务协同的混合策略控制,该策略将标准联合生成任务与两个辅助的确定性任务相结合:音频驱动的视频生成和视频驱动的音频生成。这种方法利用来自辅助任务的强单向监督信号来稳定并加速音视频对齐的学习。总训练目标是三个相应损失的加权和,如下面的公式所定义,其中辅助任务以驱动模态的干净、无噪声潜在变量为条件(例如,对于音频驱动的视频生成,ta=0)。这种双向协同使模型能够预先学习鲁棒的对齐知识,进而作为主要联合生成任务的催化剂。
L=Ljoint+λvLdrivenaudio+λaLdrivenvideo为了确保有效的跨模态交互,作者引入了全局-局部解耦交互模块,解决了细粒度时间对齐与整体风格一致性之间固有的张力。该模块由两个专门的组件组成。第一个是 RoPE 对齐帧级注意力机制,它解决了视频和音频潜在变量之间采样率不匹配的挑战。通过动态缩放源模态的旋转位置嵌入 (RoPE) 以匹配目标的时间轴,该模块为正确的时间对应关系建立了强大的归纳偏置。随后是对称的双向交叉注意力操作,其中每一帧都关注另一模态中一个小的、相关的时间窗口,从而强制执行精确的局部同步。
第二个组件是全局风格对齐模块,负责传播整体风格属性,如情感基调和环境特征。该模块通过残差交叉注意力块,利用来自整个视频潜在变量 zv 的全局上下文来调节参考音频潜在变量 zr。由此产生的视觉感知参考潜在变量 zrupdated 随后被预置到噪声音频潜在变量 za,t 之前,允许音频生成以全局一致的风格为条件,而不干扰细粒度的时间对齐过程。

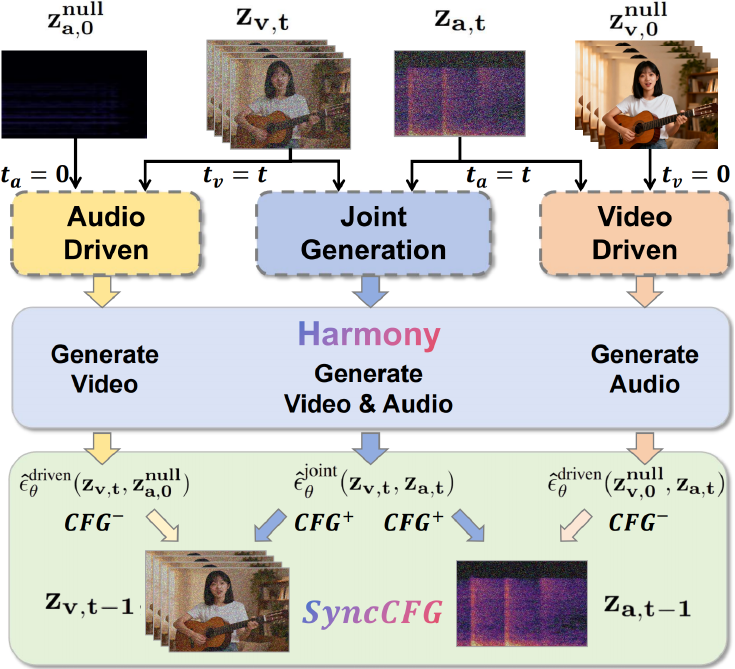
为了在推理过程中进一步增强同步性,作者提出了一种新颖的同步增强 CFG (SyncCFG) 机制。该方案重新利用了标准的无分类器引导 (CFG) 来显式放大音视频对应信号。对于视频引导,SyncCFG 使用“静音音频”负向锚点,即模型以静音音频输入 za,0null 为条件对视频潜在变量的预测。视频噪声的引导预测是通过从联合生成预测中减去该基线来制定的,从而隔离并放大与音频直接相关的视觉动态。对于音频引导,采用对称公式,使用“静态视频”负向锚点 zv,0null 来隔离运动驱动的声音。这种针对性的方法将 CFG 从通用的条件放大器转变为专门强制执行细粒度视听对应关系的机制。
实验
- 与最先进方法的定量比较: 在环境音、语音和复杂场景数据集上针对 MM-Diffusion、JavisDiT、UniVerse-1 和 Ovi 的评估验证了该模型在联合音视频生成方面的卓越性能。
- 核心性能指标: 提出的 Harmony 模型在视听同步方面取得了最先进的结果,获得了 5.61 的 Sync-C 分数和 7.53 的 Sync-D 分数,显著优于基线,同时保持了具有竞争力的视频质量和音频保真度。
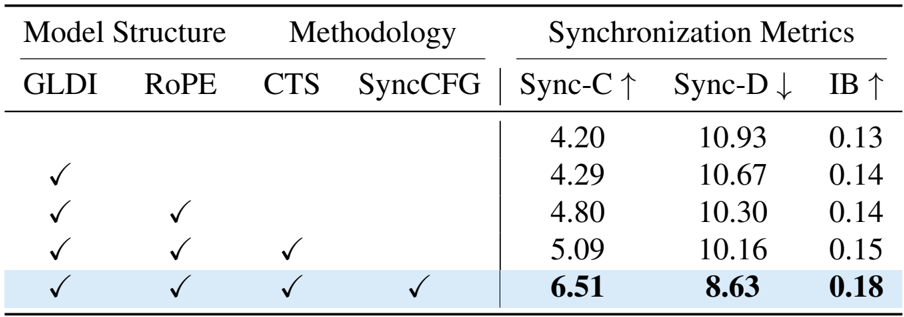
- 消融研究: 实验证实了核心组件的有效性,特别是同步增强无分类器引导 (SyncCFG),它将人类语音数据集上的 Sync-C 分数从 5.09 提高到了 6.51。
- 定性和视觉分析: 注意力图可视化和定性比较展示了精确的时空对齐,表明模型有效地定位了声源(如说话者的嘴唇或动物),并在包括跨语言生成和艺术风格渲染在内的各种任务中表现出色。
作者将他们的模型 Harmony 与几种最先进的方法在不同的音视频生成任务上进行了比较。结果表明,Harmony 在人类语音和环境声音生成以及语音-视频和声音-视频对齐方面均取得了最高性能,在这些类别中优于所有其他模型。
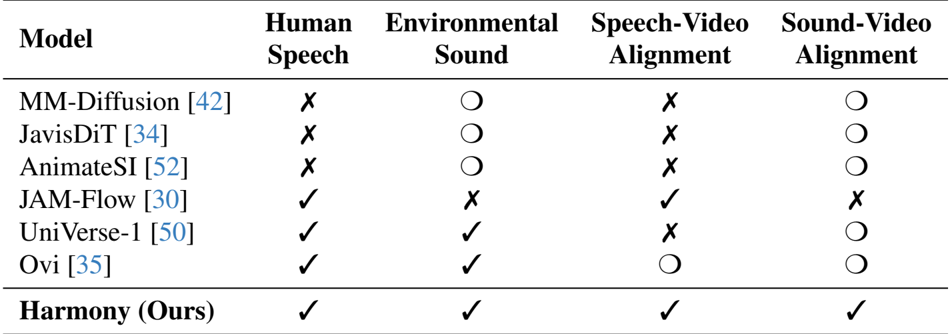
作者使用一个综合评估框架,在视频质量、音频保真度和视听同步方面将 Harmony 与最先进的音视频生成模型进行了比较。结果表明,Harmony 在包括 Sync-C 和 IB 在内的关键同步指标上取得了最高分,同时在视频质量和音频保真度方面也表现出色,证明了其卓越的跨模态对齐和整体性能。

作者使用消融研究来评估其提出的组件对视听同步的影响。结果表明,添加全局-局部解耦交互 (GLDI) 模块改善了同步性,进一步集成 RoPE 对齐、跨任务协同 (CTS) 和同步增强 CFG (SyncCFG) 带来了持续的收益。包含所有组件的完整模型实现了最高的 Sync-C 分数 6.51 和最低的 Sync-D 分数 8.63,证明了每项贡献的有效性。