Command Palette
Search for a command to run...
Inferix:一种基于块扩散的下一代推理引擎,用于世界模拟
Inferix:一种基于块扩散的下一代推理引擎,用于世界模拟
摘要
世界模型(World Models)作为代理型人工智能(Agentic AI)、具身智能(Embodied AI)以及游戏等领域中的核心模拟器,能够生成长时长、物理上逼真且具备交互性的高质量视频。进一步扩展这些模型的规模,有望在视觉感知、理解与推理方面涌现出新的能力,从而推动一种超越当前以大语言模型(LLM)为中心的视觉基础模型的新范式发展。其中一项关键突破在于半自回归(块扩散,block-diffusion)解码范式——该范式通过在每个视频块内采用块级扩散机制生成视频令牌,同时依赖先前块的上下文进行条件化建模,融合了扩散模型与自回归方法的优势,显著提升了生成视频在时序连贯性与稳定性方面的表现。尤为重要的是,该范式通过重新引入类似大语言模型(LLM)的键值缓存(KV Cache)管理机制,克服了传统视频扩散模型在效率、可变长度生成及质量方面的局限,实现了高效、灵活且高质量的视频生成。因此,Inferix 被专门设计为下一代推理引擎,旨在通过优化的半自回归解码流程,实现沉浸式世界合成。其专注于世界模拟这一核心目标,使其在架构设计上明显区别于面向高并发场景的系统(如 vLLM 或 SGLang),也不同于传统的视频扩散模型(如 xDiTs)。此外,Inferix 还集成了交互式视频流传输与性能分析功能,支持实时交互与逼真的动态世界建模,从而更准确地刻画复杂环境中的演化规律。同时,它通过无缝集成 LV-Bench——一个专为分钟级视频生成任务设计的细粒度评估基准——实现了高效的基准测试能力。我们诚挚希望社区能够携手推进 Inferix 的发展,共同探索世界模型的前沿边界,推动智能体与虚拟世界模拟技术的持续演进。
摘要
Inferix 团队推出了 Inferix,这是用于沉浸式世界合成的下一代推理引擎,它采用优化的半自回归块扩散解码和 LLM 风格的 KV 缓存管理,以实现高效、交互式和长视频生成,这与标准的高并发或经典扩散系统截然不同。
简介
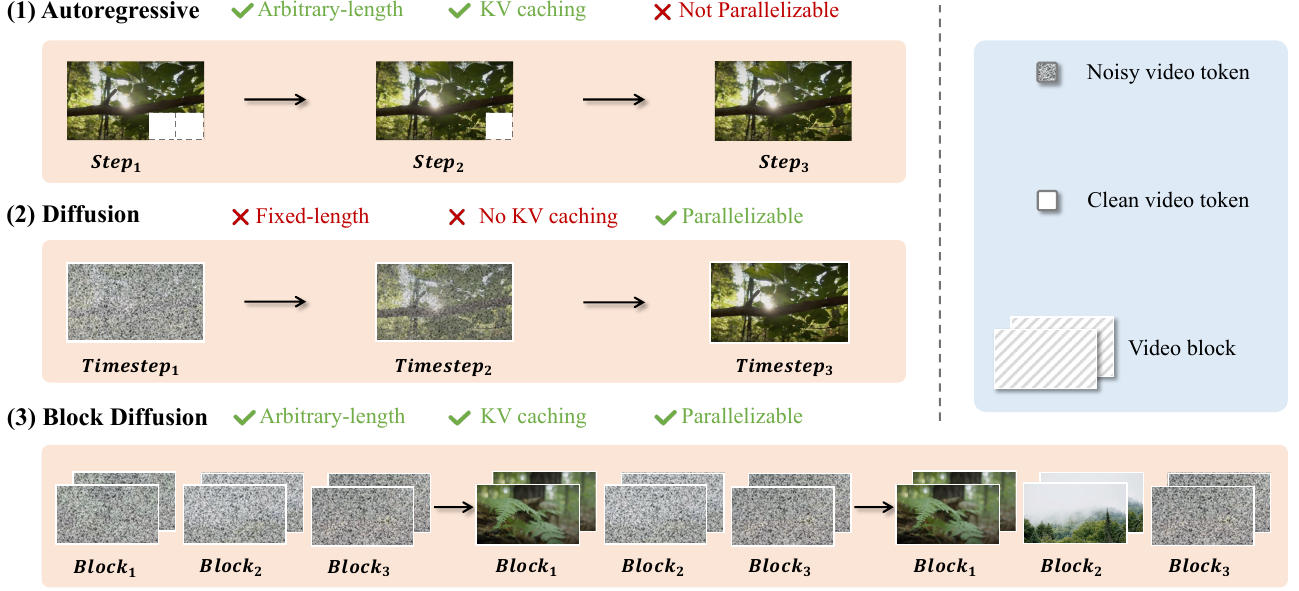
世界模型正迅速朝着生成长篇、交互式视频序列的方向发展,这就迫切需要能够处理沉浸式世界合成带来的巨大计算和存储需求的专用基础设施。当前的方法面临着明显的权衡:扩散 Transformer (DiT) 提供高质量、并行化的生成,但受限于低效的解码和固定长度约束;而自回归 (AR) 模型支持可变长度,但在视觉质量上往往滞后,且缺乏并行化能力。
为了弥合这一差距,作者推出了 Inferix,这是一个专用的推理引擎,旨在实现高效、任意长度的视频生成。通过采用“块扩散”框架,该系统在 AR 和扩散范式之间进行插值,利用半自回归解码策略,重新引入 LLM 风格的内存管理,以在扩展序列中保持高生成质量。
关键创新包括:
- 半自回归块扩散: 该引擎采用“生成并缓存”循环,其中注意力机制利用全局 KV 缓存来维护跨生成块的上下文,在不牺牲扩散质量的情况下确保长程连贯性。
- 先进的内存管理: 为了解决长上下文模拟的存储瓶颈,系统集成了类似于 PageAttention 的智能 KV 缓存优化技术,以最大限度地减少 GPU 显存使用。
- 可扩展的生产特性: 该框架支持大规模环境的分布式合成、用于动态叙事控制的连续提示,以及内置的实时视频流协议。
数据集
作者推出了 LV-Bench,这是一个旨在解决生成分钟级长视频挑战的基准测试。数据集的构建和使用涉及以下组件:
- 组成和来源: 该基准测试包含从不同的开源集合(具体为 DanceTrack、GOT-10k、HD-VILA-100M 和 ShareGPT4V)中收集的 1,000 个长视频。
- 筛选标准: 团队优先考虑高分辨率内容,严格筛选时长超过 50 秒的视频。
- 元数据构建: 为了确保语言多样性和时间细节,作者利用 GPT-4o 作为数据引擎,每 2 到 3 秒生成细粒度的字幕。
- 质量保证: 在三个阶段应用了严格的人机回环 (human-in-the-loop) 验证框架:来源筛选(过滤不合适的片段)、分块分割(确保连贯性并去除伪影)和字幕验证(完善 AI 生成的文本)。每个阶段至少由两名独立审核员进行验证,以保持可靠性。
- 模型使用: 最终整理的数据集按 80/20 的比例划分为训练集和评估集。
方法
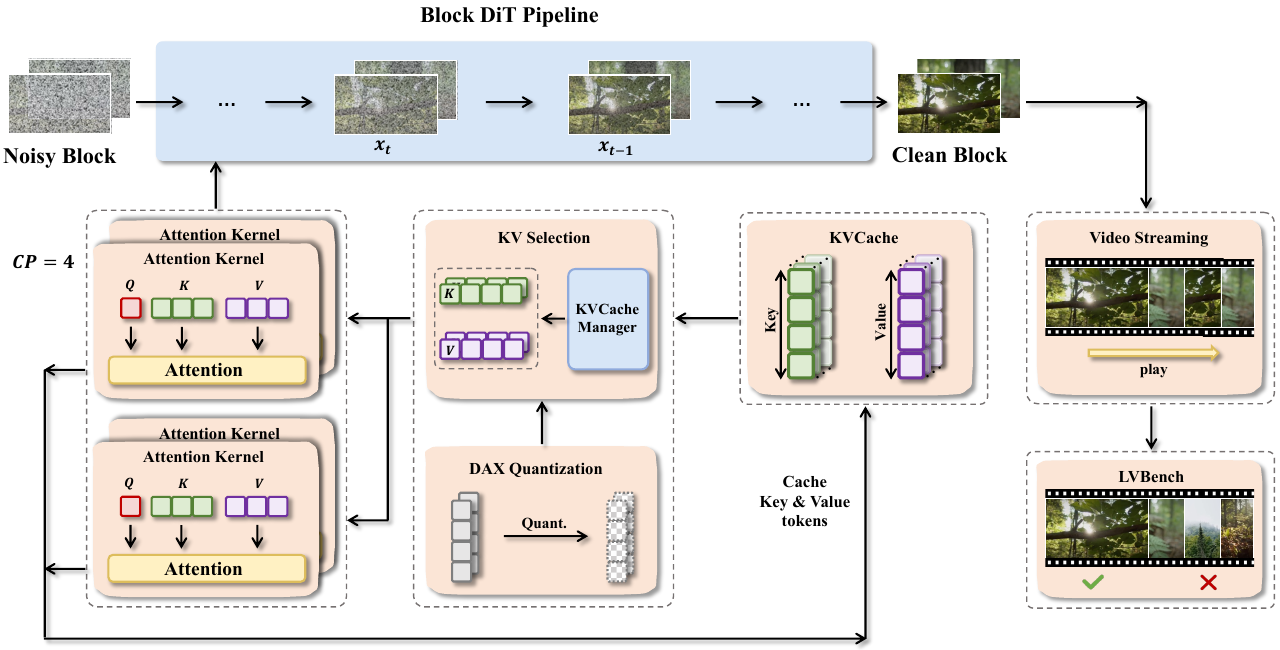
作者利用一个模块化且可扩展的框架,旨在解决块扩散模型在长视频生成中的独特挑战。正如框架图所示,该系统的核心是围绕一个通用推理流水线构建的,该流水线抽象了 MAGI-1、CausVid 和 Self Forcing 等不同模型中的常见计算模式。该流水线编排了一系列相互连接的组件,以实现高效且可扩展的推理。
推理过程的核心是块 DiT 流水线 (Block DiT Pipeline),它以离散块的形式处理视频。每个块都经过基于扩散的去噪过程,其中噪声块被迭代地细化为干净块。此过程依赖于注意力机制,需要访问先前步骤中的键值 (KV) 对。为了高效管理这些 KV 对,该框架采用了块级 KV 内存管理系统。该系统支持灵活的访问模式,包括基于范围的分块访问和基于索引的选择性获取,从而确保了未来可能需要滑动窗口或选择性全局上下文的模型变体的可扩展性和延展性。
为了加速计算并减轻内存压力,该框架集成了一套并行技术。Ulysses 风格的序列并行将独立的注意力头划分到多个 GPU 上,而环形注意力 (Ring Attention) 则以环形拓扑分布注意力操作,从而实现长序列的可扩展计算。这些策略之间的选择是自适应的,基于模型架构和通信开销,以确保最佳的资源利用率。该框架还结合了 DAX 量化,降低 KV 缓存 token 的精度,以在不显著损失质量的情况下最大限度地减少内存占用。
该系统进一步支持实时视频流,允许通过用户提供的信号(如提示词或运动输入)动态控制叙事生成。当为后续视频块引入新提示词时,框架会清除交叉注意力缓存,以防止先前上下文的干扰,确保生成内容连贯且与提示词对齐。这一功能得到了内置性能分析器的补充,该分析器提供近乎零开销、可定制且易于使用的检测工具,用于监控推理期间的资源利用率。
实验
- 引入了视频漂移误差 (Video Drift Error, VDE),这是一种受 MAPE 启发的统一指标,旨在量化长视频生成中的相对质量变化和时间退化。
- 建立了五个特定的 VDE 变体(清晰度、运动、美学、背景和主体),以评估不同视觉和动态方面的漂移,其中分数越低表示时间一致性越强。
- 将这些漂移指标与 VBench 的五个互补质量维度(主体一致性、背景一致性、运动平滑度、美学质量和图像质量)相结合,形成一个综合评估协议。
作者使用包含 1000 个视频的 LV-Bench 数据集(由 671 个人类实例、171 个动物实例和 158 个环境实例组成)来评估长视频生成。结果表明,该数据集涵盖了不同的对象类别和视频数量,为评估长时程视频生成中的时间一致性和视觉质量提供了全面的基准。
