Command Palette
Search for a command to run...
多智能体系统中的潜在协作
多智能体系统中的潜在协作
摘要
多智能体系统(Multi-agent Systems, MAS)将大语言模型(LLM)从独立的单模型推理拓展至系统级的协同智能。尽管现有LLM智能体依赖文本作为推理与通信的中介,我们在此基础上迈出关键一步,实现模型在连续隐空间中的直接协作。为此,我们提出LatentMAS——一种端到端、无需训练的框架,支持LLM智能体之间纯粹的隐空间协作。在LatentMAS中,每个智能体首先通过最后一层隐藏状态嵌入,自回归地生成隐空间思维表示;随后,共享的隐空间工作记忆保存并传递各智能体的内部表征,确保信息交换无损。我们提供了理论分析,证明LatentMAS在表达能力上更优,且在信息无损保留的同时,相比传统的基于文本的MAS,显著降低了计算复杂度。此外,在涵盖数学与科学推理、常识理解、代码生成等9个综合性基准上的实证评估表明,LatentMAS在各项任务中均持续超越强基线的单模型及文本型MAS方法,最高实现14.6%的准确率提升,输出Token使用量减少70.8%至83.7%,端到端推理速度提升4倍至4.3倍。结果表明,本研究提出的隐空间协作框架在不增加任何训练成本的前提下,显著提升了系统级推理质量并带来了显著的效率优势。代码与数据已全部开源,地址为:https://github.com/Gen-Verse/LatentMAS。
摘要
来自伊利诺伊大学厄巴纳-香槟分校、普林斯顿大学和斯坦福大学的研究人员推出了 LatentMAS,这是一个免训练框架,它通过利用共享的潜在工作记忆进行直接的嵌入级协作,从而绕过了传统的基于文本的中介,显著提高了数学、科学和代码基准测试中的推理速度和准确性。
引言
基于大型语言模型 (LLM) 的多智能体系统已成为解决从数学推理到具身决策等复杂任务的关键。通常,这些系统依赖自然语言文本作为协调的主要媒介,要求智能体将内部思维解码并重新编码为离散的 token 以进行交流。然而,这种基于文本的方法造成了信息瓶颈和计算效率低下,因为它无法捕捉模型内部状态的全部丰富性,并且需要昂贵的解码过程。
为了解决这些低效问题,作者推出了 LatentMAS,这是一个免训练框架,使智能体能够完全在连续潜在空间内进行协作。通过绕过自然语言解码,该系统将内部潜在思维生成与共享的潜在工作记忆相结合,允许智能体通过其内部表示直接进行交互。
关键创新
- 增强的推理表达能力: 该框架利用连续隐藏状态来编码和处理比离散文本 token 可能包含的更丰富的语义信息。
- 无损通信: 作者利用存储在层级 KV 缓存中的共享潜在工作记忆,实现了智能体之间上下文和思维的直接且无损的传输。
- 卓越的效率: 该方法显著降低了计算开销,与基于文本的基线相比,推理速度提高了 4.3 倍,输出 token 使用量减少了 70% 以上。
数据集
作者使用分为三个主要领域的各种基准测试套件对模型进行了评估。每个子集的组成和具体细节如下:
数学与科学推理
- GSM8K: 包含 8.5K 个小学数学应用题,旨在评估多步数值推理以及将自然语言分解为算术步骤的能力。
- AIME24: 包含来自 2024 年美国数学邀请赛的 30 个竞赛级问题,涵盖代数、几何、数论和组合数学,具有精确的数值答案。
- AIME25: 包含来自 2025 年考试的 30 个额外问题。该集合保持了 AIME24 的难度概况,但引入了更多的多阶段推导和复杂的组合构造,以测试数学鲁棒性。
- GPQA-Diamond: 代表 GPQA 基准测试中最难的分组,包含 198 个物理、生物和化学方面的研究生水平多项选择题,强调跨学科推理。
- MedQA: 包含真实的行医执照考试问题,要求将文本上下文与特定领域的生物医学知识和临床推理相结合。
常识推理
- ARC-Easy: AI2 推理挑战赛的一个子集,侧重于小学科学问题,以此建立基础事实知识和基本推理的基线。
- ARC-Challenge: 包含 AI2 推理挑战赛中最难的项目。这些对抗性问题需要多跳推理、因果推断以及系统地排除干扰项。
代码生成
- MBPP-Plus: 扩展了原始 MBPP 基准测试,具有更广泛的输入覆盖范围和额外的隐藏测试用例。它通过严格的基于执行的测试来评估独立 Python 函数的生成。
- HumanEval-Plus: 通过更密集且更具挑战性的测试套件增强了 HumanEval,以严格衡量功能正确性以及超越提示示例的泛化能力。
方法
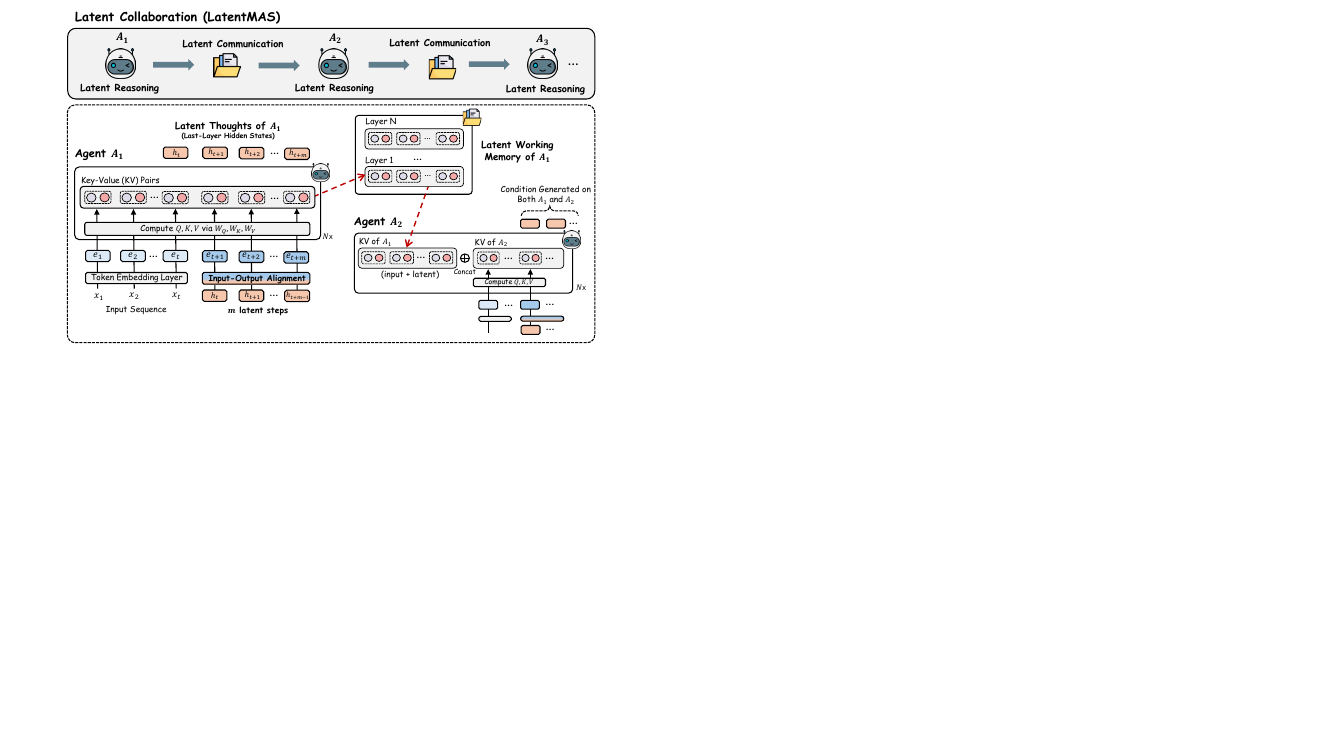
作者介绍了 LatentMAS,这是一个用于大型语言模型 (LLM) 智能体之间潜在协作的端到端框架,旨在无需显式文本通信的情况下,在多智能体系统 (MAS) 中实现高效且富有表现力的推理。该框架的核心围绕两个关键创新:单个智能体内的潜在思维生成和用于智能体间通信的无损潜在工作记忆传输机制。整体架构如框架图所示,展示了一系列智能体,每个智能体执行潜在推理,随后进行潜在通信,从而完全在潜在空间内实现系统范围的协作过程。
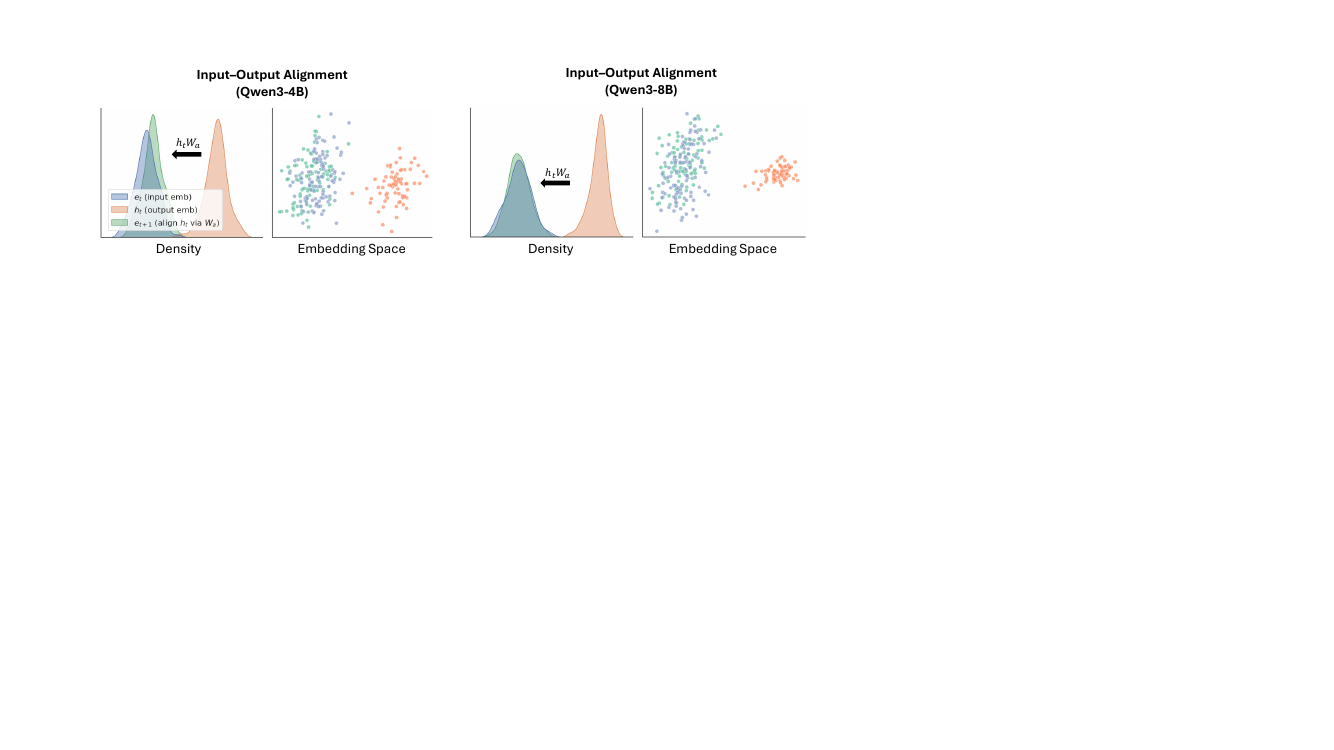
系统中的每个 LLM 智能体通过生成一系列潜在思维来进行推理,这些思维是源自模型最后一层隐藏状态的连续高维表示。这一过程(详见第 4 节)是一个直接作用于模型内部表示的自回归过程。给定一个输入序列,智能体首先通过其 Transformer 层对其进行处理,以获得最后一层隐藏状态 ht。模型不是将此状态解码为文本 token,而是自回归地将 ht 作为下一个输入嵌入追加,重复此过程 m 步以生成潜在思维序列 H=[ht+1,ht+2,…,ht+m]。这种方法允许超强的推理表达能力,因为潜在思维可以捕捉比离散文本 token 更丰富的语义结构。为了确保这些生成的潜在状态与模型的输入层兼容并避免分布外激活,作者采用了免训练线性对齐算子。该算子由投影矩阵 Wa 定义,将最后一层隐藏状态映射回有效的输入嵌入空间。矩阵 Wa 使用岭回归计算一次,即 Wa≈Wout−1Win,其中 Win 和 Wout 是模型的输入和输出嵌入矩阵。这种对齐确保了潜在思维的分布与模型学习到的输入嵌入一致,从而保持了模型内部表示的完整性。
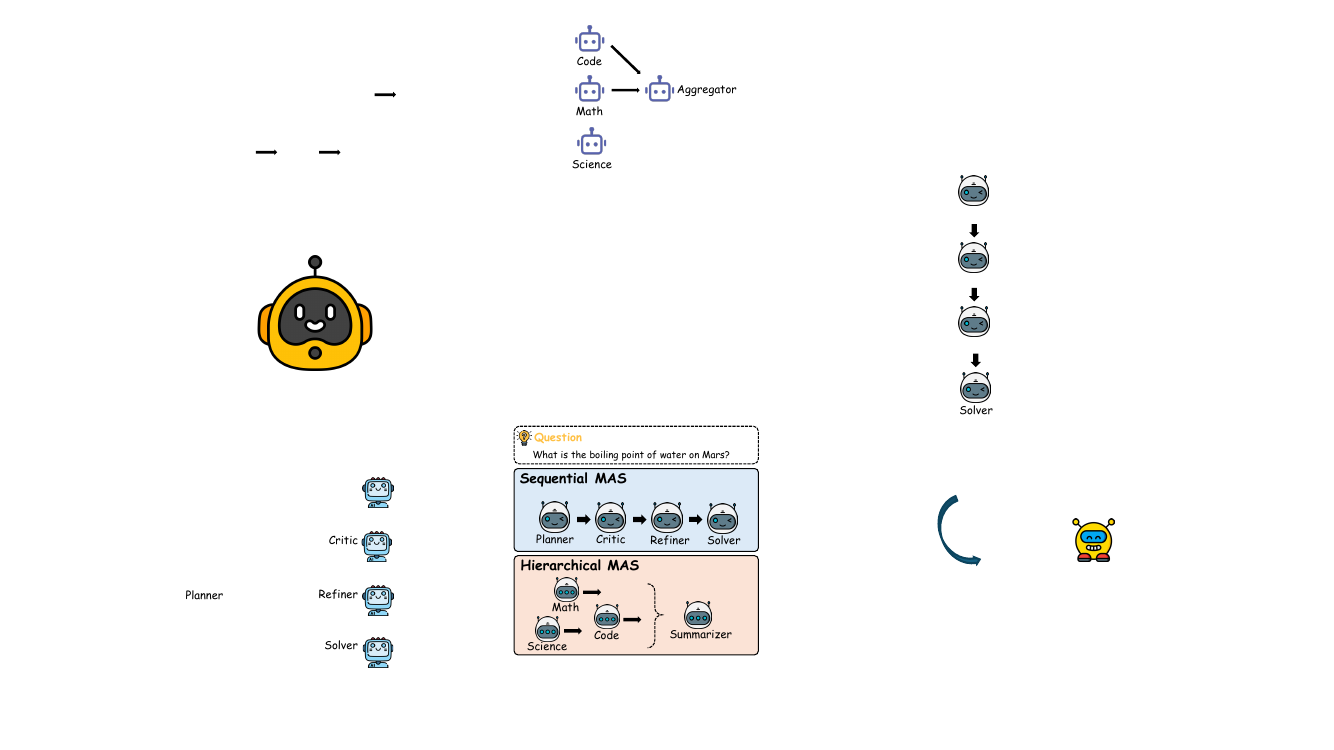
智能体之间的协作由一种新颖的潜在工作记忆传输机制促进,这对框架的效率和表达能力至关重要。如框架图所示,在智能体 A1 生成其潜在思维后,它不会产生文本输出。相反,它从所有 L 个 Transformer 层中提取其完整的键值 (KV) 缓存。该缓存封装了模型来自初始输入和生成的潜在思维的内部状态,被定义为智能体的潜在工作记忆。然后将此记忆传输给下一个智能体 A2。在 A2 开始其自己的潜在推理之前,它通过执行层级拼接来整合接收到的记忆,将来自 A1 的 K 和 V 矩阵前置到其现有的 KV 缓存中。这使得 A2 能够在没有任何信息丢失的情况下,基于 A1 输出的完整上下文进行推理。定理 2 正式确立了该机制保证了与直接基于文本的输入交换等效的信息保真度,确保了协作过程是无损的。该框架与特定的 MAS 设计无关,既可应用于顺序架构也可应用于分层架构,如展示这两种设置的图所示。
实验
- 对九个基准测试(包括 GSM8K、MedQA 和 HumanEval-Plus)的综合评估验证了 LatentMAS 相对于使用 Qwen3 主干的单智能体和基于文本的多智能体系统 (MAS) 的性能。
- 在准确性方面,LatentMAS 比单模型基线平均提高了 13.3% 至 14.6%,并超过基于文本的 MAS 2.8% 至 4.6%。
- 效率实验表明,与基于文本的 MAS 相比,推理速度提高了 4 倍至 4.3 倍,token 使用量减少了 70% 以上,相对于 vLLM 优化的基线实现了高达 7 倍的加速。
- 对潜在表示的分析证实,它们编码了与正确文本响应相似的语义,但具有更强的表达能力,而输入-输出重新对齐机制贡献了 2.3% 至 5.3% 的准确性增益。
- 对潜在步骤深度的消融研究表明,性能始终在 40 到 80 步之间达到峰值,确立了平衡准确性和效率的最佳范围。
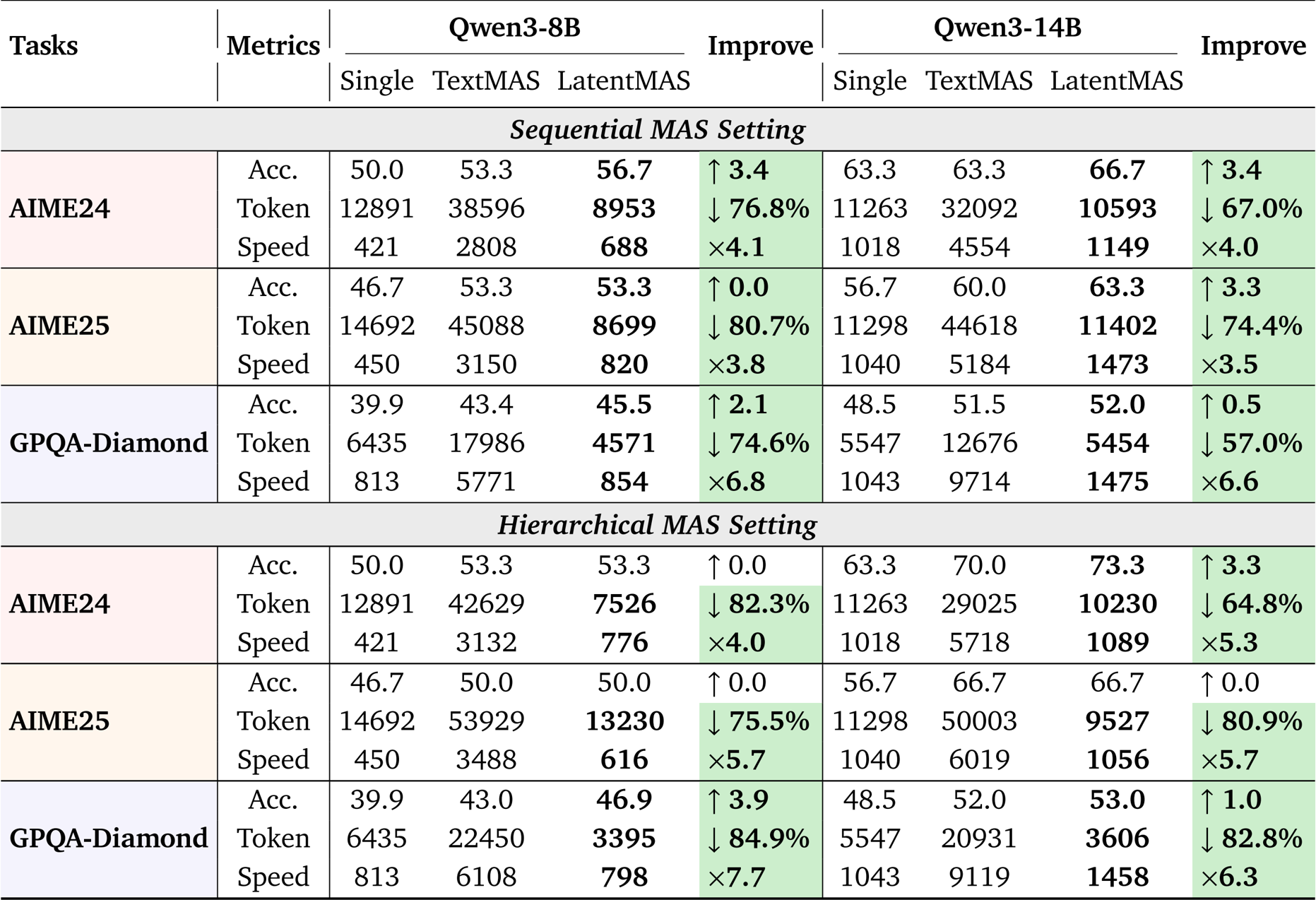
作者使用 LatentMAS 评估其在顺序和分层 MAS 设置下跨多个基准测试的性能,并将其与单个 LLM 智能体和基于文本的 MAS 基线进行比较。结果表明,LatentMAS 始终能实现更高的准确性,同时显著减少 token 使用量并提高推理速度,与单个和基于文本的 MAS 相比,平均增益分别为 14.6% 和 13.3%,并且推理速度比基于文本的方法快高达 4.3 倍。
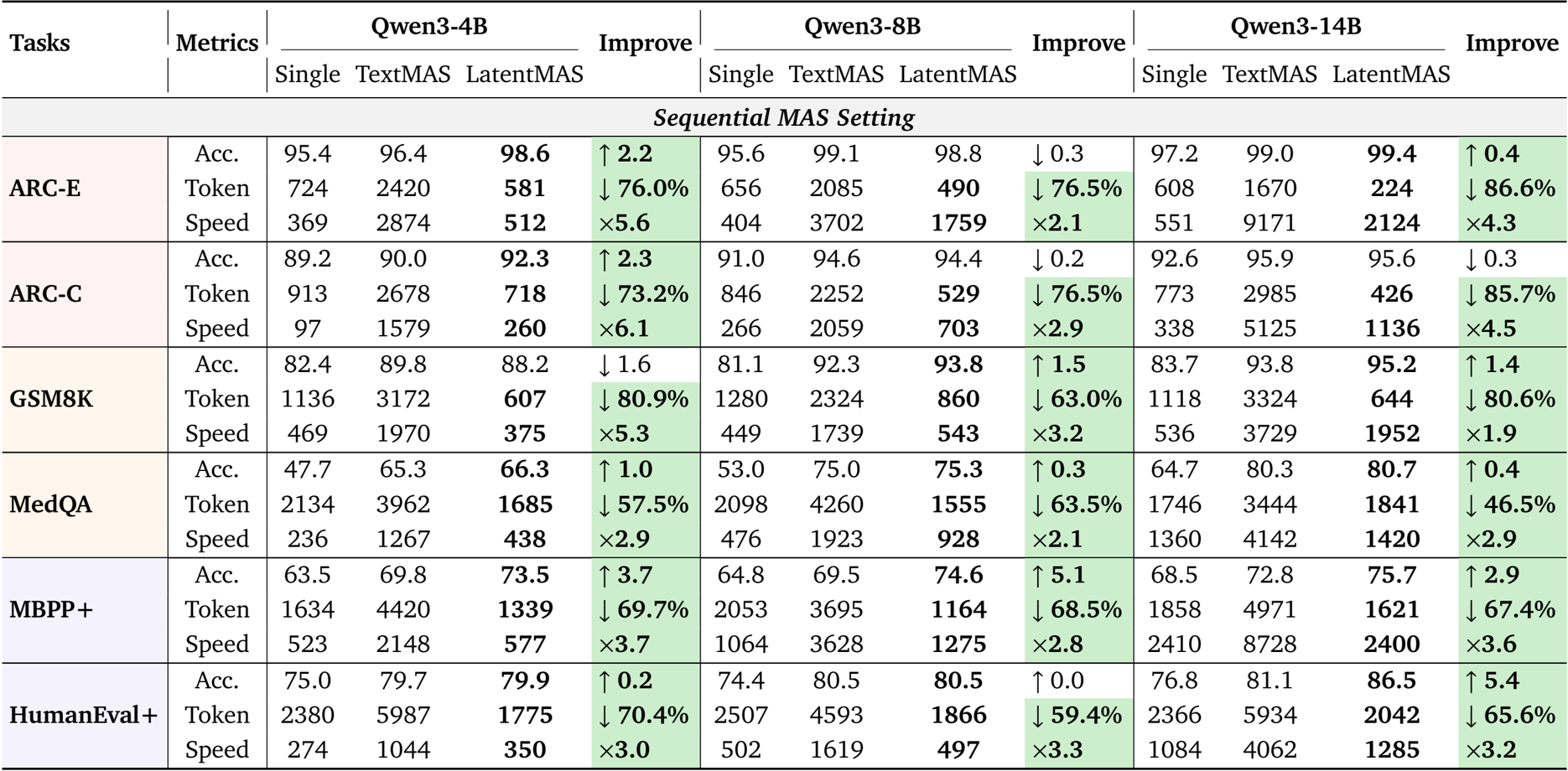
作者使用 LatentMAS 评估在分层和顺序 MAS 设置下跨多个基准测试的性能,并将其与单个 LLM 智能体和基于文本的 MAS 基线进行比较。结果表明,LatentMAS 始终能提高任务准确性,同时显著减少 token 使用量并增加推理速度,与单个和基于文本的 MAS 相比,平均增益分别为 14.6% 和 13.3%,并且推理速度比基于文本的方法快高达 4.3 倍。
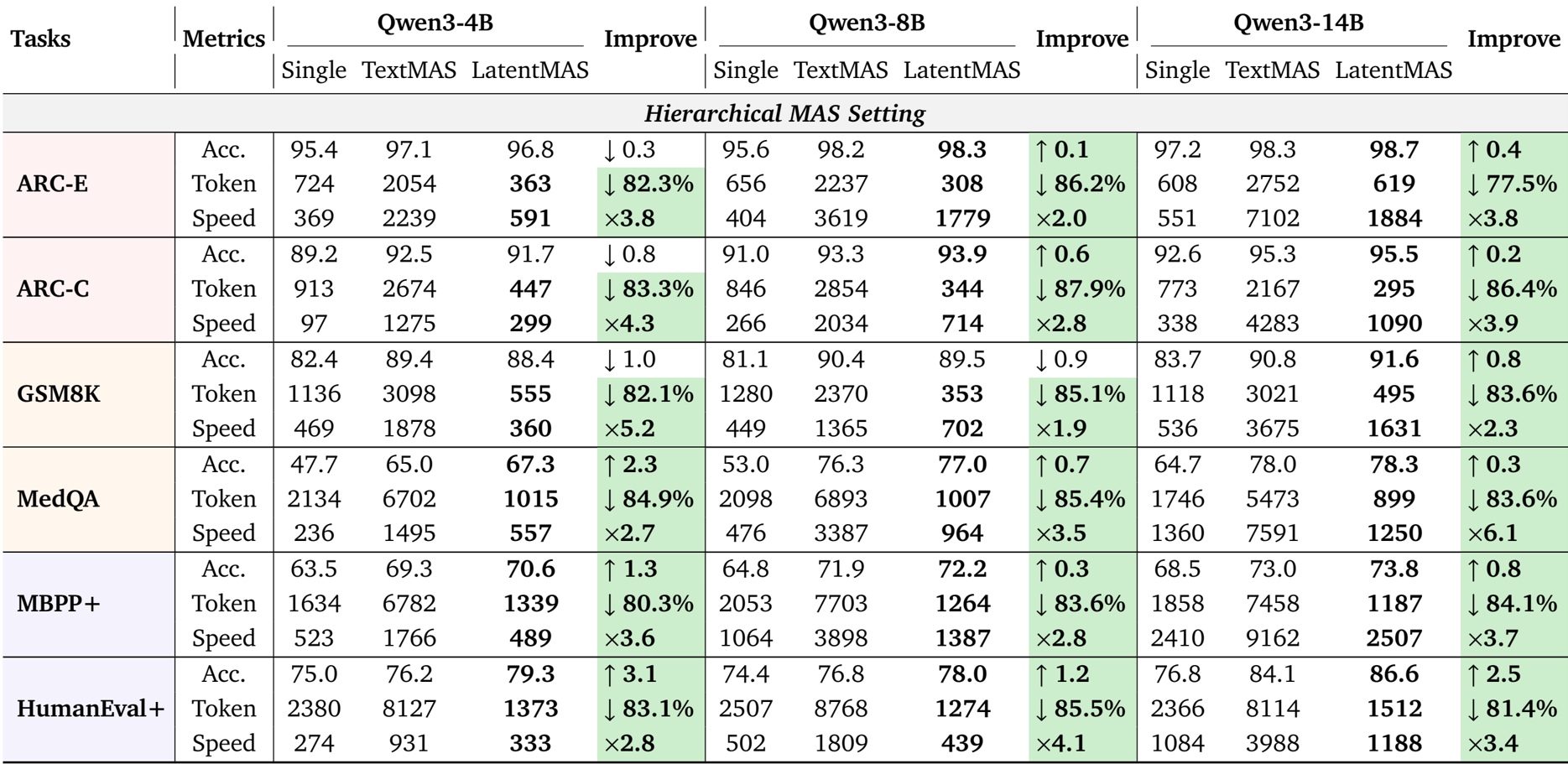
作者使用 LatentMAS 评估其相对于单模型和基于文本的多智能体系统在多个推理任务中的性能。结果表明,与基于文本的方法相比,LatentMAS 实现了更高的准确性,并显著减少了 token 使用量,同时提高了推理速度,在不同的模型大小和 MAS 设置中均有一致的增益。