Command Palette
Search for a command to run...
基于随机路径积分的忠实度感知推荐解释
基于随机路径积分的忠实度感知推荐解释
Oren Barkan Yahlly Schein Yehonatan Elisha Veronika Bogina Mikhail Baklanov Noam Koenigstein
摘要
解释忠实度(Explanation fidelity)旨在衡量解释在多大程度上准确反映了模型的真实推理过程,然而这一课题在推荐系统领域仍缺乏充分研究。我们提出了 SPINRec(Stochastic Path Integration for Neural Recommender Explanations,意为“用于神经推荐解释的随机路径积分”),这是一种模型无关(model-agnostic)的方法,它将路径积分技术进行了适配,以应对推荐数据稀疏且隐式的特性。为了克服现有方法的局限性,SPINRec 采用了随机基准采样(stochastic baseline sampling)策略:它并未从固定或不切实际的基准点开始积分,而是从经验数据分布中采样多个合理的用户画像(user profiles),并从中筛选出最忠实的归因路径。这一设计捕捉了已观测及未观测交互行为的影响,从而生成更加稳定且个性化的解释。我们针对三个模型(MF、VAE、NCF)和三个数据集(ML1M、Yahoo! Music、Pinterest)进行了迄今为止最为全面的忠实度评估,并采用了一套包含基于 AUC 的扰动曲线(AUC-based perturbation curves)及定长诊断(fixed-length diagnostics)在内的反事实指标。SPINRec 的表现始终优于所有基线方法,为推荐系统中的忠实可解释性(faithful explainability)建立了新的基准。相关代码及评估工具已在 https://github.com/DeltaLabTLV/SPINRec 公开发布。
总结
来自以色列开放大学和特拉维夫大学的研究人员推出了 SPINRec,这是一个模型无关的框架,通过采用随机基线采样来整合来自合理用户画像的归因路径,而不是依赖固定或不切实际的基线,从而增强了推荐系统中解释的保真度。
简介
随着推荐系统日益影响用户在电子商务和媒体领域的决策,对透明度的需求已从简单的说服力转向保真度,即确保解释能够准确反映模型的实际决策过程。然而,将既有的归因技术如路径积分 (PI) 应用于该领域具有挑战性,因为推荐数据本质上是稀疏和二值的。标准的 PI 方法依赖于“全零”基线,无法捕捉这种环境下用户交互的细微差别,往往导致归因信号微弱或具有误导性。
为了填补这一空白,作者推出了 SPINRec(用于神经推荐解释的随机路径积分),这是一个专门为神经推荐器调整路径积分的新颖框架。通过摒弃静态基线,作者提供了一种尊重推荐引擎独特数据结构的方法。
主要创新和优势包括:
- 随机基线采样: 模型不再依赖不切实际的全零基线,而是从经验数据分布中采样多个合理的用户历史记录,以生成更稳定且信息量更大的梯度信号。
- 特定领域的适配: 该框架首次成功将计算机视觉和 NLP 中的路径积分应用于推荐系统,专门解决了高维、稀疏和二值数据的挑战。
- 卓越的保真度: 跨多种架构(包括矩阵分解和 VAE)及数据集的广泛评估确立了 SPINRec 作为反事实解释保真度的新 SOTA(最先进)基准。
数据集
作者使用三个不同的数据集进行了实验:ML1M (MovieLens)、Yahoo! Music 和 Pinterest。数据准备和评估策略包括以下步骤:
- 数据处理: 所有数据集均经过二值化处理,将交互转换为隐式反馈。
- 划分策略: 研究人员采用 80/20 的基于用户的划分方法将数据分为训练集和测试集。
- 验证: 从训练数据中额外保留 10% 的用户作为验证集,用于超参数微调。
- 评估范围: 结果基于测试集报告,解释专门针对每个用户的首位推荐结果。
方法
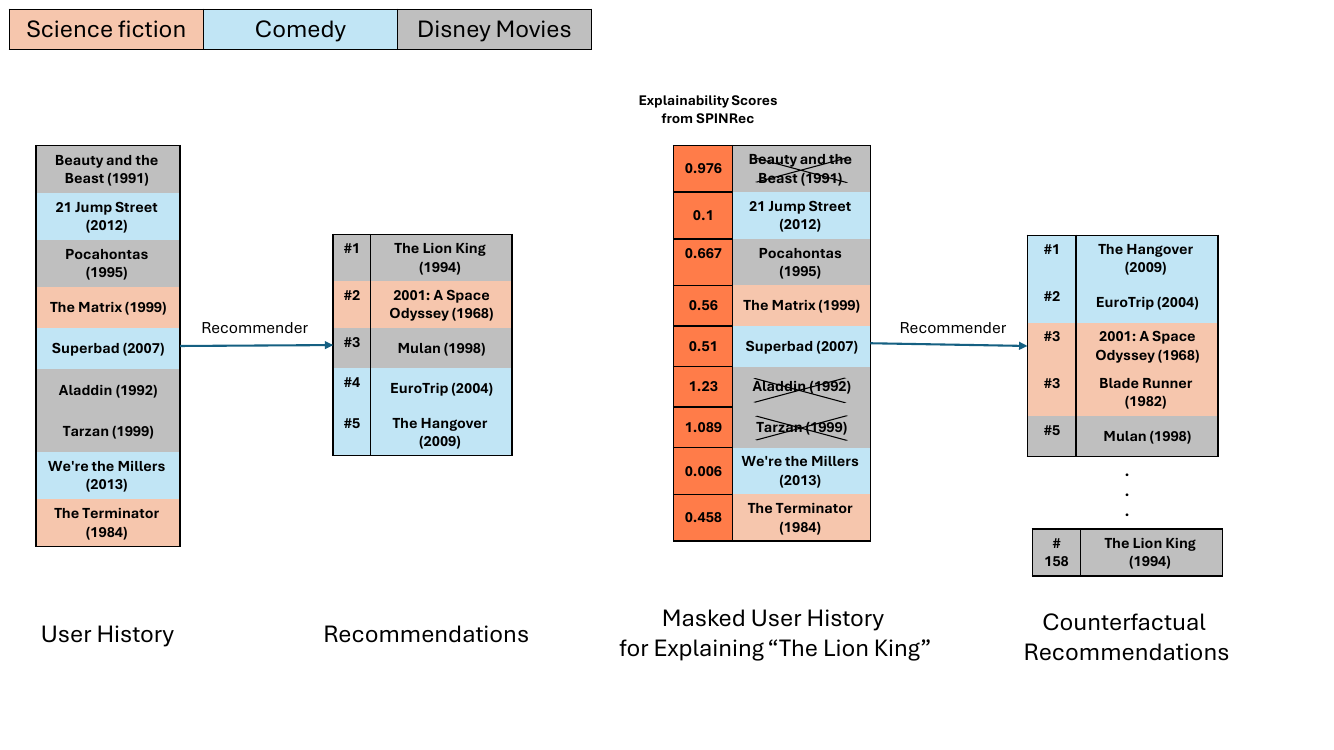
作者利用路径积分方法开发了 SPINRec,这是一个用于在推荐系统中生成解释的框架。核心方法通过沿基线用户表示到实际用户数据的路径对梯度进行积分来计算特征归因。给定用户的二值特征向量 x 和目标物品 y,预测的亲和度 fθy(x) 使用直线路径 r(t)=t⋅x+(1−t)⋅z 分解为单个特征的贡献,其中 z 是基线向量且 t∈[0,1]。每个特征的归因源自模型输出相对于插值输入的梯度的积分,并由路径导数加权。这产生了一个解释图 m,用于量化每个特征与推荐的相关性,如公式 \ref{eq:expl_map} 所定义。
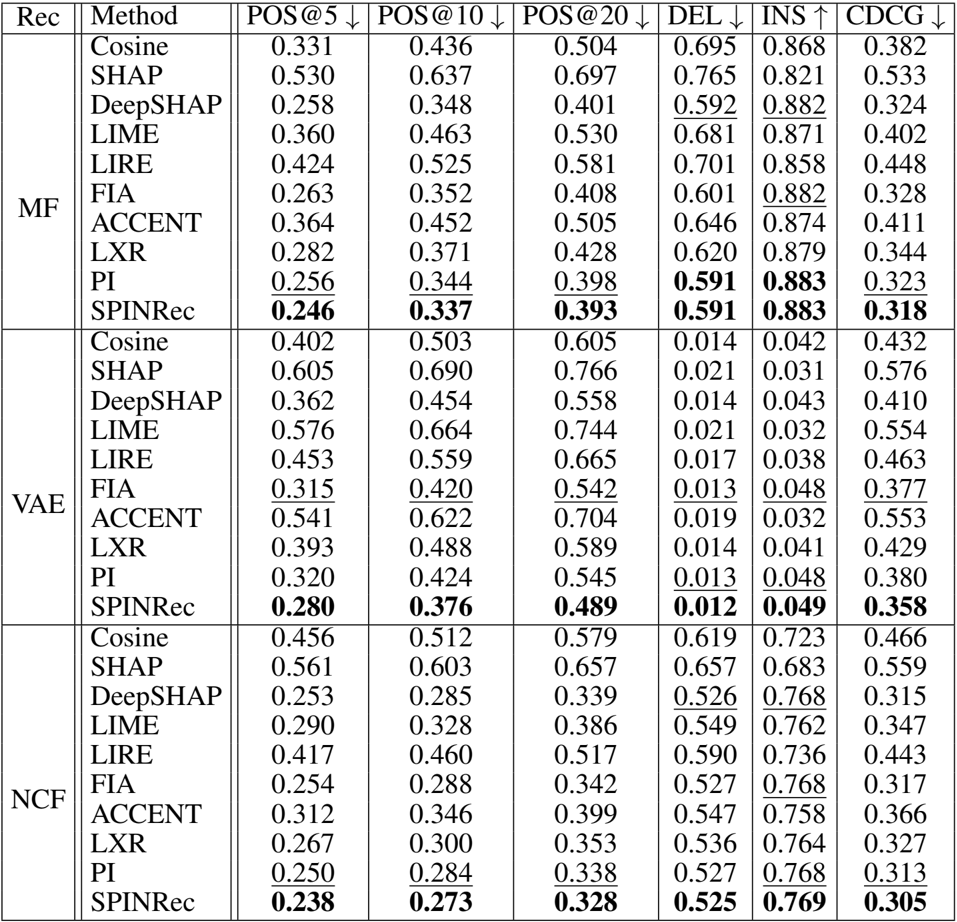
实验
- 该研究评估了 SPINRec 在三个数据集(ML1M、Yahoo! Music、Pinterest)和三种推荐架构(矩阵分解、VAE、NCF)上的反事实保真度,并将其与包括 LXR、FIA 和 SHAP 在内的最先进基线进行了比较。
- 在基于 AUC 的保真度指标上,SPINRec 在所有模型和数据集上均取得了最佳结果,在统计学上优于 LXR 和 FIA 等强基线 (p≤0.01)。
- 在定长指标评估(POS、DEL、INS、CDCG)中,该方法在不同的解释长度 (Ke) 和排名截断值 (Kr) 下均始终优于所有基线,证明了其在识别高影响力特征方面的鲁棒性。
- 消融研究验证了随机基线采样的贡献,表明 SPINRec 通过利用未观察到的交互,显著优于普通路径积分 (PI),这种性能提升在 VAE 和 NCF 等复杂模型中最为明显。
作者使用反事实保真度指标评估了多种推荐模型和数据集的解释方法,结果显示 SPINRec 在基于 AUC 和定长指标上均始终优于所有基线。在所有配置中,SPINRec 均取得了最佳性能,特别是在 POS@K 和 CDCG 等指标上,展示了在解释推荐结果方面卓越的保真度。
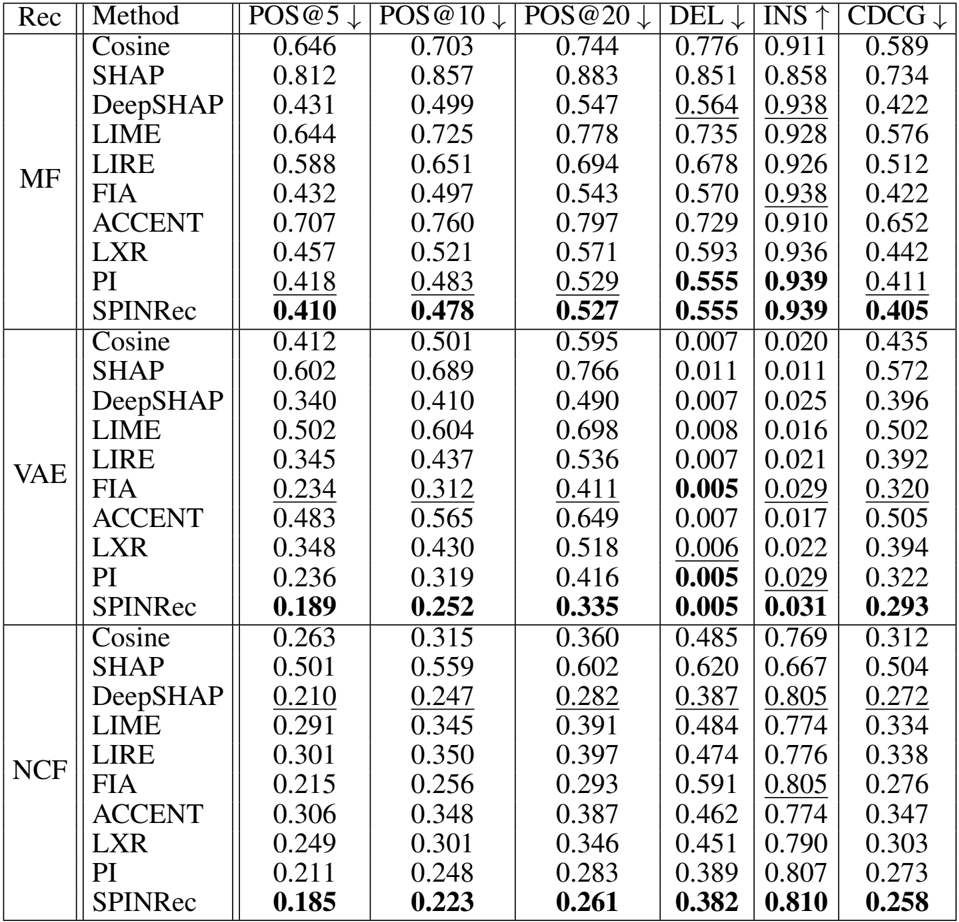
作者使用反事实保真度指标评估了多种推荐模型和数据集的解释方法,结果显示 SPINRec 在基于 AUC 和定长指标上均始终优于所有基线。在所有配置中,SPINRec 均取得了最佳性能,特别是在 POS@K 和 CDCG 等指标上表现出色,同时也展示了在不同推荐架构和数据集上的鲁棒性。