Command Palette
Search for a command to run...
提取推荐系统中的交互感知单语义概念
提取推荐系统中的交互感知单语义概念
Dor Arviv Yehonatan Elisha Oren Barkan Noam Koenigstein
摘要
我们提出了一种从推荐系统的用户和物品嵌入(embedding)中提取单义性神经元(monosemantic neurons)的方法;这些神经元被定义为与连贯且可解释的概念相对齐的潜在维度。我们的方法采用稀疏自编码器(SAE)来揭示预训练表示内部的语义结构。与语言模型的相关研究不同,推荐系统中的单义性必须保留独立用户嵌入与物品嵌入之间的交互关系。为此,我们引入了一种预测感知训练目标(prediction aware training objective),它通过一个参数冻结的推荐模型进行反向传播,使学习到的潜在结构与模型的用户-物品亲和度预测(affinity predictions)相对齐。由此得到的神经元能够捕捉流派、流行度和时间趋势等属性,并支持事后控制操作(post hoc control operations),即在不修改基础模型的前提下实现定向过滤和内容推广。我们的方法在不同的推荐模型和数据集中均具有良好的泛化能力,为实现可解释且可控的个性化推荐提供了一种实用的工具。代码及评估资源已在 https://github.com/DeltaLabTLV/Monosemanticity4Rec 开源。
摘要
来自以色列特拉维夫大学和开放大学的研究人员介绍了一种方法,使用具有新颖预测感知训练目标的稀疏自编码器 (Sparse Autoencoders),从推荐系统嵌入中提取可解释的单语义神经元,从而在不修改基础模型的情况下实现精确的事后控制操作,如定向过滤和内容推广。
简介
现代推荐系统依赖潜在嵌入来大规模生成个性化建议,但这些表示往往缺乏语义含义,使得模型变得不透明,难以对其公平性或可靠性进行审计。虽然稀疏自编码器 (SAE) 已成功从大型语言模型中提取出可解释特征,但现有方法无法捕捉推荐架构基础中独特的用户-物品交互逻辑。作者通过引入一种专门设计的 SAE 框架来解决这一问题,该框架旨在从推荐嵌入中提取“单语义神经元”,揭示潜在空间中诸如流派和流行度等可解释概念。
该方法的关键创新包括:
- 预测感知重建损失: 与标准的几何重建不同,该机制通过冻结的推荐器反向传播梯度,以确保提取的特征保留实际的推荐行为和亲和力模式。
- KL 散度正则化: 该框架用 KL 散度取代了 LLM 研究中常见的 Top-K 稀疏性目标,这提高了稳定性并防止了训练过程中的死神经元问题。
- 干预能力: 提取的神经元能够对模型输出进行精确的事后控制,允许开发人员在不重新训练基础模型的情况下抑制特定内容类型或提升目标物品。
方法
作者利用稀疏自编码器 (SAE) 框架,旨在从双塔推荐架构中的用户和物品嵌入中提取单语义概念。整个系统的运作方式是:首先通过独立的编码器将用户和物品输入编码为嵌入,然后通过评分函数预测用户-物品亲和力。SAE 事后应用于这些嵌入,将其编码为稀疏潜在表示并重建原始嵌入。该框架结合了套娃 (Matryoshka) SAE 结构,该结构训练多个字典大小递增的嵌套自编码器,从而实现分层表示,其中早期的潜在维度捕捉一般特征,而后期的维度则专注于更细粒度的概念。
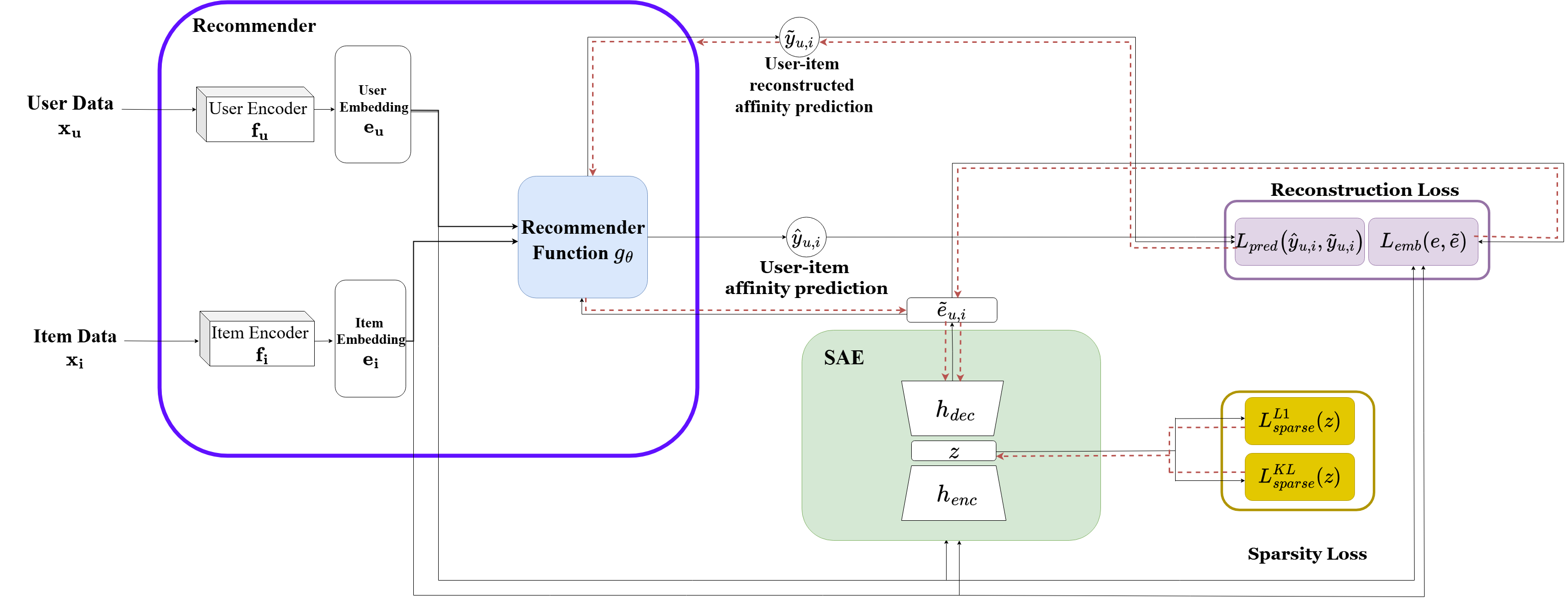
SAE 的训练采用由重建目标和稀疏性目标组成的总损失。重建损失包括两个部分:确保原始嵌入和重建嵌入之间几何保真度的嵌入级损失,以及专为推荐系统定制的新颖预测级损失。预测级损失测量原始亲和力预测与使用重建嵌入计算的预测之间的均方差,其中评分函数在训练期间保持冻结。该项鼓励 SAE 保留交互语义和排名一致性,这对推荐质量至关重要。最终的重建损失是嵌入级损失和预测级损失的加权和。稀疏性损失结合了 ℓ1 正则化和对潜在神经元激活率的 KL 散度惩罚,促进了紧凑和解纠缠的表示。训练过程包括采样用户-物品对,计算总损失,并通过冻结的推荐器反向传播梯度,以使潜在表示与推荐器的行为输出对齐。
实验
- 实验在 MovieLens 1M 和 Last.FM 数据集上评估了矩阵分解和神经协同过滤模型,以评估稀疏自编码器的可解释性。
- 定性分析证实,单语义神经元在无监督的情况下自然涌现,有效地编码了特定流派、风格时代和物品流行度等概念。
- 使用语义纯度指标进行的定量评估显示出高精度;值得注意的是,用于喜剧和恐怖片的矩阵分解神经元在所有 Top K 阈值下均达到了 100% 的纯度,并且与乡村音乐和金属乐等音乐流派几乎完美对齐。
- 消融研究表明,增加预测级损失权重可以提高推荐保真度(通过 Rank Biased Overlap 和 Kendall Tau 衡量),尽管最佳的单语义性需要平衡该权重与瓶颈稀疏性。
- 干预实验验证了事后修改模型行为的能力,例如通过调整潜在神经元激活,成功地向具有不相关偏好的用户推广特定艺术家。
- 使用套娃 SAE 进行的分层分析表明,早期神经元捕捉广泛的主流偏好,而后期神经元则专注于小众微流派,这种模式在 Last.FM 数据集中尤为明显。
结果表明,从推荐模型中提取的单语义神经元在流派概念上实现了高语义纯度,对于 MovieLens 上的 MF 和 NCF 模型,许多神经元在 K=10 时达到了 100% 的纯度。该表还显示,“流行度神经元”始终针对高排名物品激活,表明存在一个捕捉两个数据集中主流吸引力的潜在维度。

结果表明,从推荐模型中提取的单语义神经元在电子乐、金属乐和民谣等音乐流派上实现了高语义纯度,其纯度值在 K=10 时通常达到 1.00。该表还显示,流行度神经元始终针对两个数据集中的高排名物品激活,表明对广泛消费的内容存在强烈偏见。
