Command Palette
Search for a command to run...
视觉思考,文本推理:ARC中的视觉-语言协同作用
视觉思考,文本推理:ARC中的视觉-语言协同作用
Beichen Zhang Yuhang Zang Xiaoyi Dong Yuhang Cao Haodong Duan Dahua Lin Jiaqi Wang
摘要
从极少量示例中进行抽象推理,仍是当前前沿基础模型(如GPT-5和Grok 4)面临的核心未解难题。这些模型仍难以从寥寥数个示例中推断出结构化的变换规则,而这一能力正是人类智能的关键标志。为评估该能力,人工智能通用性抽象与推理基准数据集(Abstraction and Reasoning Corpus for Artificial General Intelligence, ARC-AGI)提供了一个严格的测试平台,要求模型具备概念规则的归纳能力,并能将所学规则迁移至全新任务。然而,现有大多数方法将ARC-AGI视为纯粹的文本推理任务,忽视了人类在解决此类谜题时高度依赖视觉抽象这一事实。我们的初步实验揭示了一个悖论:若简单地将ARC-AGI的网格结构转化为图像输入,反而会导致性能下降,原因在于视觉表示难以精确执行规则。由此我们提出核心假设:视觉与语言在不同推理阶段各具互补优势——视觉擅长全局模式的抽象与验证,而语言则在符号化规则的构建与精确执行方面更具优势。基于这一洞察,我们提出两种协同策略:(1)视觉-语言协同推理(Vision-Language Synergy Reasoning, VLSR),将ARC-AGI任务分解为模态对齐的子任务,实现跨模态协作;(2)模态切换自我修正(Modality-Switch Self-Correction, MSSC),利用视觉模态对基于文本的推理过程进行验证,实现内在错误纠正。大量实验表明,所提方法在多种主流模型及多个ARC-AGI任务上,相较纯文本基线模型最高提升达4.33%。研究结果表明,将视觉抽象能力与语言推理深度融合,是未来基础模型迈向可泛化、类人智能的关键一步。相关源代码即将开源。
总结
香港中文大学和上海人工智能实验室的研究人员介绍了视觉-语言协同推理 (VLSR) 和模态切换自校正 (MSSC) 来解决 ARC-AGI 基准,有效地结合了视觉全局抽象与语言符号执行,在抽象推理任务中超越了纯文本基线。
简介
抽象与推理语料库 (ARC-AGI) 是通用人工智能的一个关键基准,评估模型通过从极少量示例中识别抽象规则而非依赖死记硬背的领域知识来“学会如何学习”的能力。虽然人类自然地依靠视觉直觉来解决这些二维网格谜题,但现有的最先进方法纯粹将这些任务作为基于文本的嵌套列表来处理。这种以文本为中心的范式忽视了诸如对称和旋转等至关重要的空间关系,然而简单的基于图像的方法也因缺乏像素级的精度而失败。因此,模型难以在理解规则所需的全局感知与执行规则所需的离散精度之间取得平衡。
作者提出了一种新颖的方法,根据视觉和文本模态各自的优势将其结合起来。他们将抽象推理分解为两个不同的阶段,利用视觉输入来总结转换规则,并利用文本表示以元素级的精确性来应用这些规则。
关键创新和优势包括:
- 视觉-语言协同推理 (VLSR): 一个动态切换模态的框架,利用视觉网格提取全局模式,利用文本坐标执行精确操作。
- 模态切换自校正 (MSSC): 一种验证机制,将文本生成的解决方案转换回图像,使模型能够从视觉上检测出在文本格式中不可见的不一致性。
- 多样的性能提升: 该方法既作为推理策略又作为训练范式发挥作用,在无需外部真实标签(ground truth)的情况下,在 GPT-4o 和 Gemini 等旗舰模型上实现了显著的准确率提升。
数据集
根据提供的文本,作者采用特定的处理策略将数据可视化如下:
- 矩阵到图像转换: 作者将输入-输出矩阵转换为颜色编码的二维网格,以保留二维空间信息并提供数据的全局视图。
- 颜色映射: 每个数值被映射到特定的颜色以创建独特的视觉元素:
- 0: 黑色
- 1: 蓝色
- 2: 红色
- 3: 绿色
- 4: 黄色
- 5: 灰色
- 6: 粉色
- 7: 橙色
- 8: 浅蓝色
- 9: 棕色
- 结构化格式: 在彩色元素(小方块)之间插入白色分隔线,以清晰地指示特定数字并定义每个块内的结构。
方法
作者利用一个两阶段框架,策略性地结合视觉和文本模态,以解决 ARC-AGI 基准中结构化网格任务的推理挑战。这种被称为视觉-语言协同推理 (VLSR) 的方法将任务分解为两个不同的子任务:规则总结和规则应用,每个子任务都针对特定模态的优势进行了优化。整体框架旨在克服纯文本方法的局限性,后者往往无法捕捉输入矩阵固有的二维结构信息。
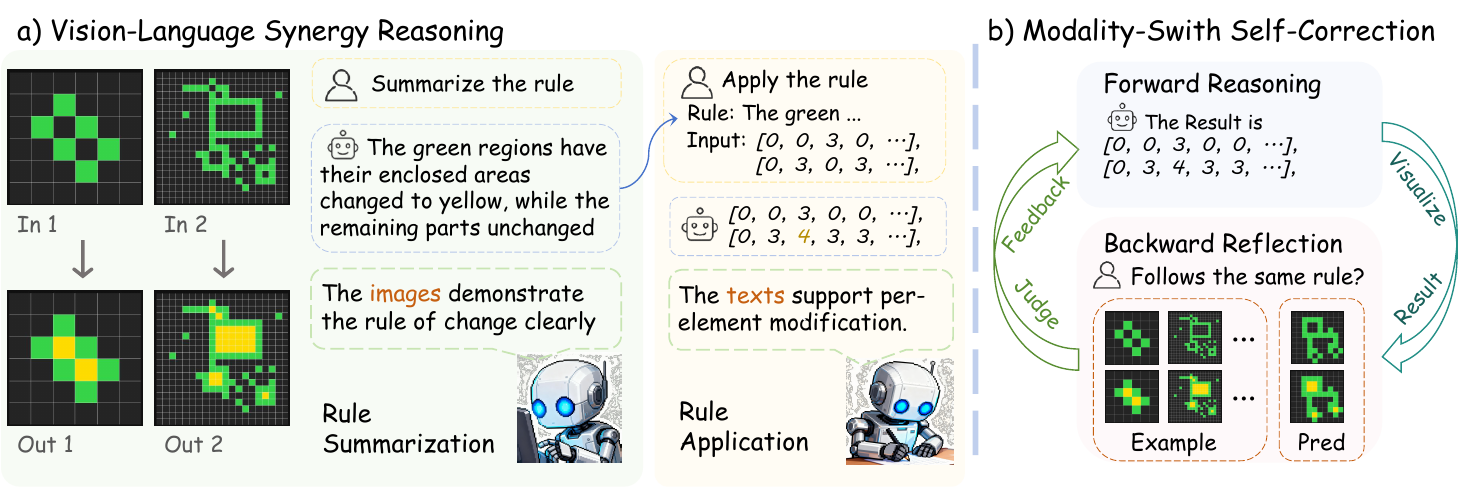 如下图所示,第一阶段,即视觉-语言协同推理,首先将所有提供的输入-输出示例对转换为其视觉表示。每个矩阵 m 被转换为图像 i=V(m),其中每个单元格的值映射到不同的颜色,创建一个保留元素间空间关系的网格布局。然后将此视觉表示输入到大型视觉-语言模型 (LVLM) 以执行规则总结。模型分析示例中的视觉模式,推导出用自然语言表达的显式转换规则 rpred。这一阶段利用了模型执行全局模式识别和理解二维结构关系的能力,这对于识别复杂的空间变换至关重要。
如下图所示,第一阶段,即视觉-语言协同推理,首先将所有提供的输入-输出示例对转换为其视觉表示。每个矩阵 m 被转换为图像 i=V(m),其中每个单元格的值映射到不同的颜色,创建一个保留元素间空间关系的网格布局。然后将此视觉表示输入到大型视觉-语言模型 (LVLM) 以执行规则总结。模型分析示例中的视觉模式,推导出用自然语言表达的显式转换规则 rpred。这一阶段利用了模型执行全局模式识别和理解二维结构关系的能力,这对于识别复杂的空间变换至关重要。
 第二阶段,即规则应用,转向文本模态。推导出的规则 rpred 用于指导测试输入的转换。所有矩阵,包括测试输入和示例,都被转换为其文本表示 t=T(m),即整数的嵌套列表。同一个 LVLM 现在以文本模式运行,并带有规则应用提示,执行逐元素的推理以生成预测的输出矩阵 tpred。这一阶段利用文本表示的精确性,根据总结的规则操作单个元素。作者强调,两个阶段使用相同的基础模型,唯一的区别在于输入模态和特定的提示策略,从而确保了一致的推理过程。
第二阶段,即规则应用,转向文本模态。推导出的规则 rpred 用于指导测试输入的转换。所有矩阵,包括测试输入和示例,都被转换为其文本表示 t=T(m),即整数的嵌套列表。同一个 LVLM 现在以文本模式运行,并带有规则应用提示,执行逐元素的推理以生成预测的输出矩阵 tpred。这一阶段利用文本表示的精确性,根据总结的规则操作单个元素。作者强调,两个阶段使用相同的基础模型,唯一的区别在于输入模态和特定的提示策略,从而确保了一致的推理过程。
为了进一步提高输出的可靠性,作者引入了模态切换自校正 (MSSC) 机制。该策略通过使用不同的模态进行推理和验证来解决内在自校正的挑战。在初始文本规则应用产生候选输出 tpred 后,模型首先将此文本输出转换回视觉表示 ipred。然后将此可视化输出呈现给 LVLM,LVLM 充当批评者,评估预测的转换与提供的示例的一致性。模型评估测试输入-输出对 (itestinput,ipred) 是否遵循与训练示例相同的模式。如果模型确定输出不一致,它会接收反馈并执行迭代细化步骤,利用前一次尝试的信息生成新的候选输出。此过程重复进行,直到输出被认为一致或达到最大迭代次数。这种模态切换提供了一个全新的视角,打破了模型的确认偏差,使其能够识别出在使用相同模态进行推理和验证时难以察觉的错误。
实验
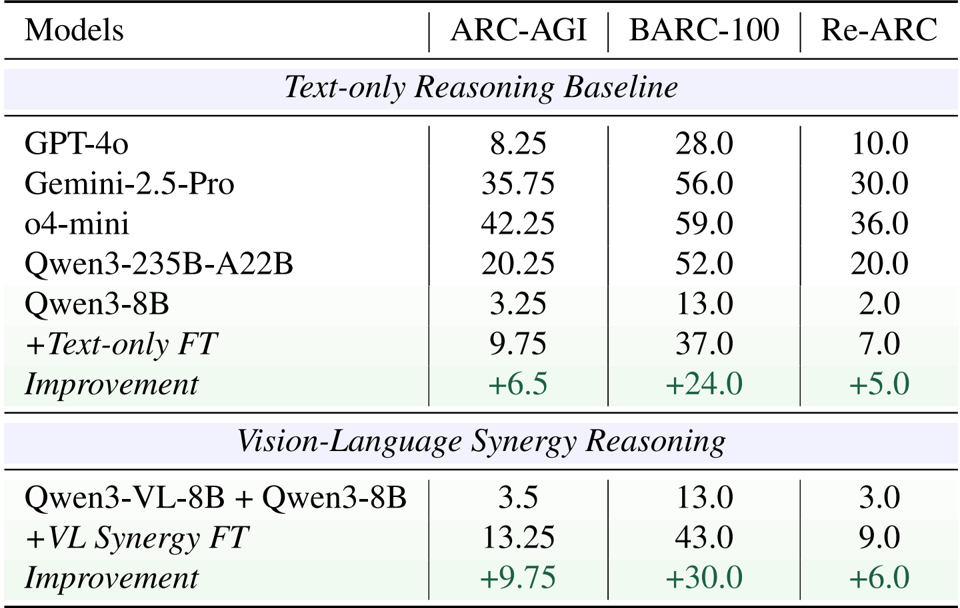
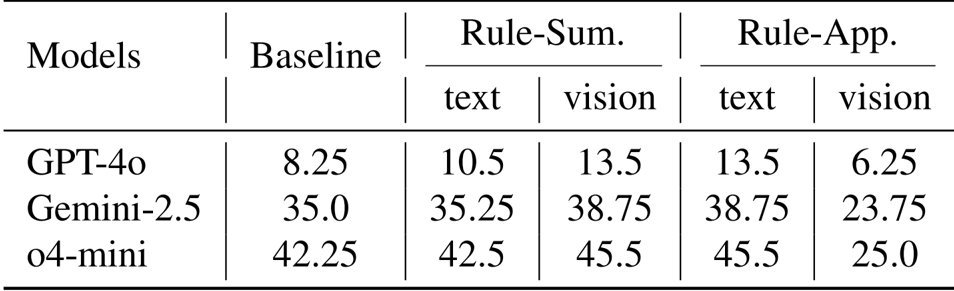
- 模态隔离实验验证了视觉表示在规则总结方面表现出色(平均提升 3.2%),而文本表示在规则应用方面更胜一筹,在规则应用中使用视觉方法会导致 15.0% 的性能下降。
- 提出的 VLSR 和 MSSC 策略在 ARC-AGI、Re-ARC 和 BARC 基准测试中持续提升了性能,在 ARC-AGI 上将 GPT-4o 的基线结果提升了高达 6.25%,将 Gemini-2.5-Pro 的结果提升了 7.25%。
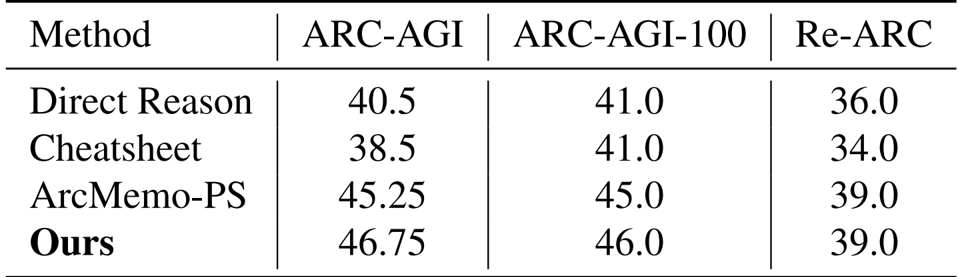
- 在使用 o4-mini 的对比评估中,该方法在所有测试集中均达到了最高准确率,在 ARC-AGI 上比最强的免训练基线 (ArcMemo-PS) 高出 1.5%。
- 对自校正机制的分析表明,模态切换自校正 (MSSC) 实现了持续的单调增益(例如,将 GPT-4o 的得分从 8.25 提高到 12.0),而纯文本自校正提供的价值微乎其微甚至是负面的。
- 在 ARC-Heavy-200k 上的微调实验表明,视觉-语言协同在 ARC-AGI 上达到了 13.25% 的准确率,显著优于以文本为中心的微调 (9.75%) 和闭源 GPT-4o 基线 (8.25%)。
结果表明,使用视觉模态进行规则总结提高了所有模型的性能,GPT-4o 从 8.25 增加到 13.5,Gemini-2.5 从 35.0 增加到 38.75,o4-mini 从 42.25 增加到 45.5。然而,在规则应用阶段使用视觉表示应用规则会导致显著的性能下降,GPT-4o 从 13.5 降至 6.25,Gemini-2.5 从 38.75 降至 23.75,o4-mini 从 45.5 降至 25.0。
作者使用模态切换方法来改进抽象推理,其中视觉表示用于规则总结,文本表示用于规则应用。结果表明,结合这两种方法持续提高了所有模型和基准的性能,当同时应用 VLSR 和 MSSC 时取得了最佳结果。
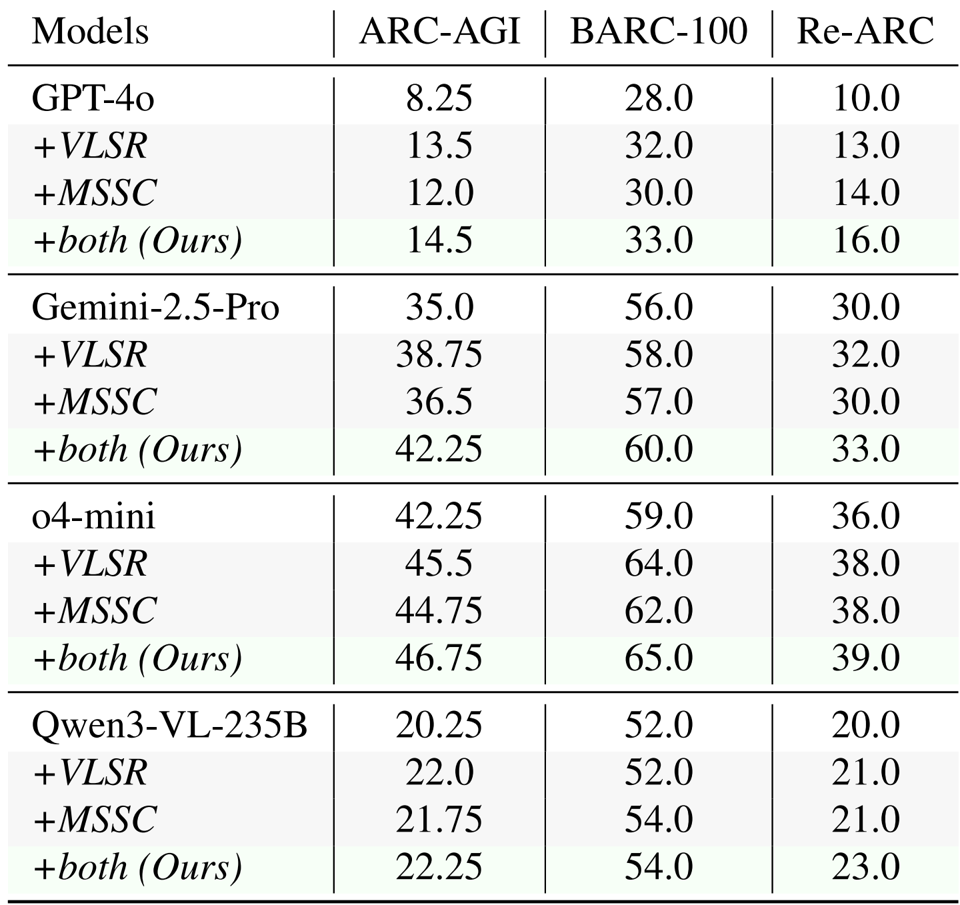
结果表明,所提出的方法在所有基准测试中都比基线方法实现了更高的准确率,在 ARC-AGI 上比最强的基线 ArcMemo-PS 提高了 1.5%。这证明了视觉信息提供了仅靠基于文本的记忆检索无法捕捉的互补优势。
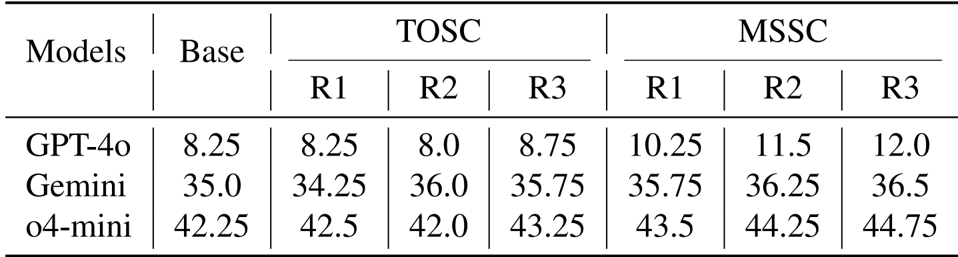
结果表明,模态切换自校正 (MSSC) 在所有模型和迭代中都比纯文本自校正 (TOSC) 持续提高了性能,GPT-4o 从第 1 轮到第 3 轮实现了 3.75 分的增长,而 TOSC 显示出的增益微乎其微,甚至在某些轮次中有所下降。这种改进归因于视觉验证提供了一个全新的视角,有助于检测纯文本推理中遗漏的空间不一致性。
作者使用视觉-语言协同方法来改进抽象推理,其中视觉表示用于规则总结,文本用于规则应用。结果表明,结合这些模态显著提升了性能,与纯文本微调相比,视觉-语言协同方法在 ARC-AGI 上实现了 9.75% 的平均提升。