Command Palette
Search for a command to run...
多模态评估俄语语言架构
多模态评估俄语语言架构
摘要
多模态大语言模型(MLLMs)目前正处于研究的前沿,其规模与能力均展现出迅猛的发展,然而其智能水平、固有局限性及潜在风险仍缺乏充分理解。为应对这些问题,特别是在俄语语境下——当前尚无针对俄语的多模态评估基准——我们提出了 Mera Multi,一个面向俄语语境的开源多模态评估框架。该基准基于指令驱动设计,涵盖文本、图像、音频和视频四种基础模态,包含18项全新构建的评估任务,适用于通用模型以及针对特定模态的架构(如图像到文本、视频到文本、音频到文本)。本研究的主要贡献包括:(i)提出了一套通用的多模态能力分类体系;(ii)从零开始构建了18个数据集,充分考虑俄语的语言与文化特性,统一设计提示(prompts)与评估指标;(iii)为闭源与开源模型提供了基准性能结果;(iv)建立了一套防止基准泄露的方法论,包括数据水印技术与私有数据集的授权协议。尽管当前研究聚焦于俄语,但所提出的评估框架为在句法类型多样语言中构建多模态基准提供了可复现的方法论,尤其适用于斯拉夫语族语言的开发与评估。
摘要
MERA 团队推出了 MERA Multi,这是一个针对俄语模型的综合多模态评估框架,具有通用分类法和跨越音频、视频及图像模态的 18 个原创数据集,旨在对多样化架构进行文化准确且防泄漏的评估。
引言
像 GPT-5 和 LLaVa 这样的生成式 AI 模型的快速演进,使得对文本、图像、音频和视频能力的严格评估成为迫切需求。虽然以英语为中心的评估已相当成熟,但该领域缺乏综合框架来评估这些模型如何处理斯拉夫语言的结构复杂性和文化细微差别。先前在多模态基准测试方面的工作主要集中在英语或中文上,而现有的俄语特定基准测试仅限于基于文本的任务。
为了填补这一空白,作者推出了 MERA Multi,这是首个专门为评估俄语多模态大型语言模型 (MLLMs) 而设计的基准测试。该框架评估了跨越四种模态的 18 项任务的性能,并作为开发其他形态丰富语言的文化感知评估的可扩展蓝图。
关键创新包括:
- 统一分类法: 作者提出了一种标准化的方法和分类法,用于评估文本、图像、音频和视频模态下的 MLLM。
- 文化特异性: 该基准测试包含 18 个捕捉俄语文化背景(如民俗和媒体)的新颖数据集,以及直接翻译往往会遗漏的语言细微差别。
- 评估完整性: 该研究建立了数据泄漏分析和水印策略以保护私有评估数据集,确保开源和闭源模型的有效基线。
数据集
数据集构成与来源
作者介绍了 MERA Multi,这是一个旨在评估俄语多模态大型语言模型 (MLLMs) 的基准测试。该数据集围绕三个核心能力构建:感知、知识和推理。它包含以下要素:
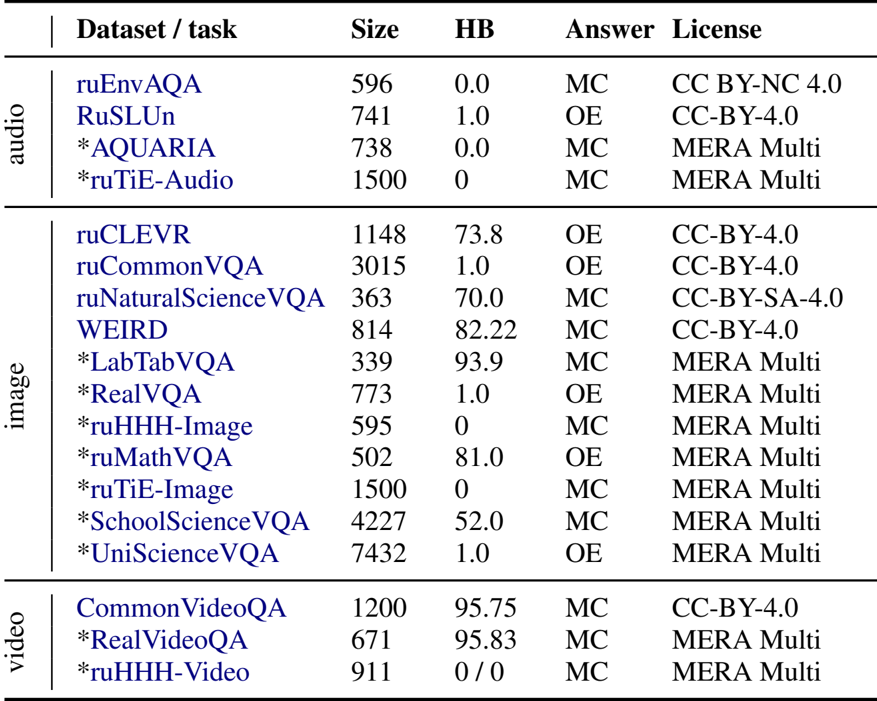
- 模态: 该基准测试涵盖四种模态,包括文本、图像(11 个数据集)、音频(4 个数据集)和视频(3 个数据集)。
- 来源组合: 为了平衡可复现性与新颖性,作者混合使用了从开源渠道整理的 7 个公开可用数据集和专门为此研究收集的 11 个私有数据集。
- 任务格式: 任务以多项选择题或需要简短自由形式回答的开放式问题的形式呈现。
关键子集与详情
该基准测试根据模态和任务类型分为特定的子集:
-
音频数据集:
- AQUARIA: 一个包含 9 种任务类型(例如情感识别、声音问答)的私有数据集,具有录音室录制的场景和生成音乐。
- ruEnvAQA: 基于英语数据集 Clotho-AQA 和 MUSIC-AVQA,该子集侧重于非语言信号和音乐,问题已翻译成俄语。
- ruSLUn: 改编自 xSID 的口语理解数据集,包含由非专业演讲者录制的音频,以捕捉自然背景噪音。
- ruTiE-Audio: 一个图灵测试模拟,包含需要保持长达 500 轮上下文的连贯对话。
-
视频数据集:
- CommonVideoQA: 源自 EPIC-KITCHENS 和 Kinetics 等公共存储库,侧重于无需音频的一般视频理解。
- RealVideoQA: 通过众包 (Telegram) 收集的封闭数据集,确保视频未公开。
- ruHHH-Video: 首个旨在评估视频语境中伦理推理的俄语特定数据集。
-
图像和 VQA 数据集:
- ruCommonVQA: 结合了来自 COCO 和 VQA v2 的图像与众包的独特照片,以测试细粒度感知。
- ruCLEVR: 一个视觉推理数据集,包含通过 Blender 生成的合成 3D 对象,改编自 CLEVR 方法论。
- RealVQA: 一个众包数据集,包含“陷阱”问题(干扰项),即答案无法从图像中得出,用于测试抗幻觉能力。
- LabTabVQA: 由来自远程医疗平台的匿名医疗表格截图和照片组成,使用 GPT-4o Mini 和专家进行标注。
- Scientific VQA: 包括 ruMathVQA(学校数学)、ruNaturalScienceVQA(改编自 ScienceQA)、SchoolScienceVQA(专家创建的推理任务)和 UniScienceVQA(大学水平的专家知识)。
- ruHHH-Image: 基于 HHH(诚实、有用、无害)框架的伦理评估数据集,扩展了同理心和礼仪类别。
- WEIRD: 侧重于常识违背,使用合成生成的图像和描述扩展了 WHOOPS! 基准测试。
数据使用与模型训练
作者利用这些数据进行基准测试和特定评估模型的训练:
- 评估分类法: 任务被映射到涵盖感知(例如 OCR、对象定位)、知识(常识和特定领域)和推理(归纳、演绎、数学)的技能分类法中。
- 裁判模型训练: 构建了一个单独的数据集来训练“裁判”模型。这包括源自俄语基准测试的(问题、标准答案、模型预测)三元组。
- 分割策略: 为了防止偏差,裁判模型的数据按源数据集进行分割,确保没有数据集同时出现在训练和测试分割中。
- 质量控制: 仅使用在语义正确性方面具有 100% 标注者间一致性的项目进行裁判模型训练。
处理与元数据
作者实施了几种处理策略以确保数据完整性和标准化评估:
- 水印: 为了检测数据泄漏,作者嵌入了不可见的水印。他们对音频使用 AudioSeal,对图像和视频帧使用视觉覆盖。
- 提示工程: 评估使用了一个包含 13 个固定块(例如注意力钩子、推理格式)的结构化提示系统。可变块用于特定任务的描述。
- 人类基线: 使用众包标注员(通过 ABC Elementary 平台)和针对专门任务的领域专家建立了人类表现基线。
- 防泄漏: 私有数据集受自定义许可保护,允许研究使用,但严格禁止包含在模型训练集中。
方法
MERA Multi 基准测试采用了一个综合评估框架,旨在评估多模态大型语言模型 (MLLMs) 在俄语语境下的推理、感知和知识能力。整体架构集成了四个关键组件:块提示结构、复合评分系统、具有双层指标的评估流程以及数据泄漏检测方法。请参阅框架图 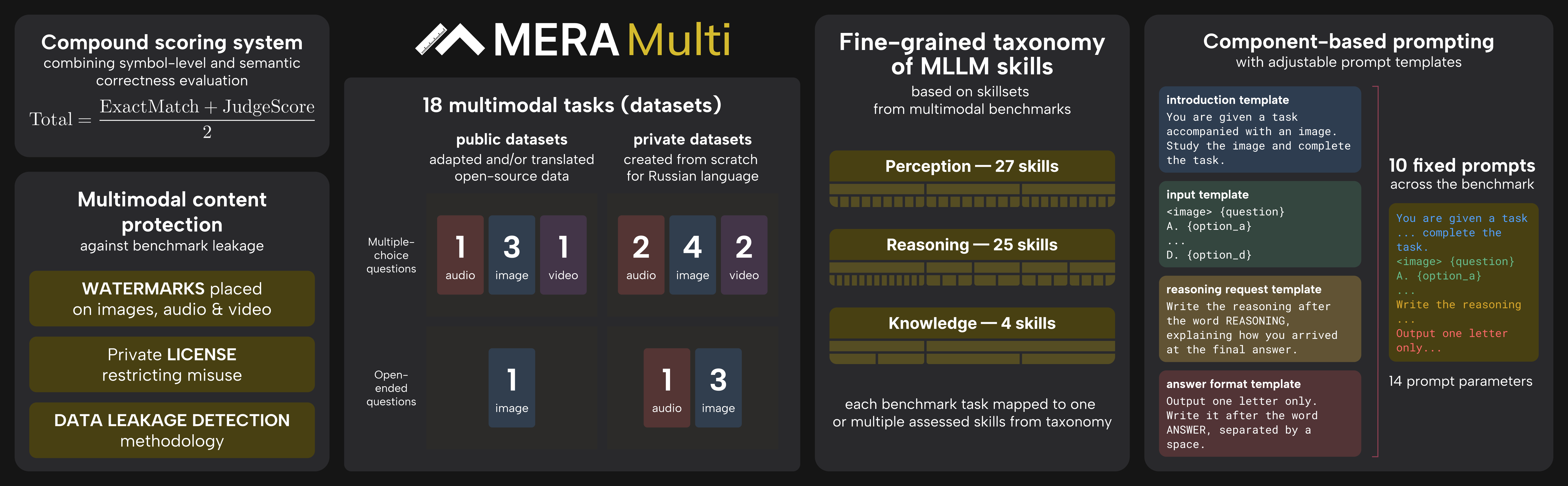 以直观了解该系统。
以直观了解该系统。
评估始于标准化的提示设计,以确保跨任务的一致性和多样性。作者利用块提示方案,其中每个任务使用从固定块布局派生的 10 个预定义提示集进行实例化。这些块包括结构化模板,如引言、输入、推理请求和回答格式,从而实现统一而灵活的任务制定。这种方法避免了硬编码特定任务的提示,并允许受控的变化(例如包含或排除推理请求),以减轻基准饱和。提示模板设计为模态无关的,支持图像、音频和视频输入,并统一应用于数据集样本,以平均化提示变体的性能并减少偏差。
评估的核心是一个结合了符号和语义正确性的复合评分系统。每个任务的总分计算为精确匹配指标和裁判评分的平均值,其中裁判评分源自一个学习型的“LLM 作为裁判”模型。该模型在一个多样化的、人工标注的模型输出数据集上进行训练,并基于 RuModernBERT 编码器。它将评估构建为一个二元分类任务——在给定输入问题的条件下,确定模型预测相对于标准答案的语义等价性。裁判模型具有很高的可靠性,在保留测试集上的 F1 分数为 0.96,并且在相同答案上与精确匹配的一致性为 99.6%。
评估流程计算三个主要指标:尝试得分、覆盖率和总分。尝试得分衡量模型实际尝试的任务的性能质量,并按每种模态尝试的任务数量进行归一化。覆盖率将评估的广度量化为跨所有模态尝试的基准测试的比例。总分是尝试得分和覆盖率的乘积,从而实现一个公平的单一排行榜,将质量与广度分开,并在任务增长下保持稳定。这种设计确保模型不会因缺少任务而受到惩罚,并允许进行联合排名和特定模态的排名。
最后,该框架包含数据泄漏检测方法以保护基准测试的完整性。这涉及使用掩码、删除、复制和交换等技术为每个数据点生成扰动文本邻居,同时保持模态数据不变。使用固定编码器提取文本嵌入,并计算目标模型和参考模型的多模态损失。训练一个二元分类器(MSMIA 检测器),根据损失和嵌入空间中的特征差异,区分已见过数据的模型和未见过数据的模型。该组件确保了对抗过拟合的鲁棒性并维护了评估的有效性。
实验
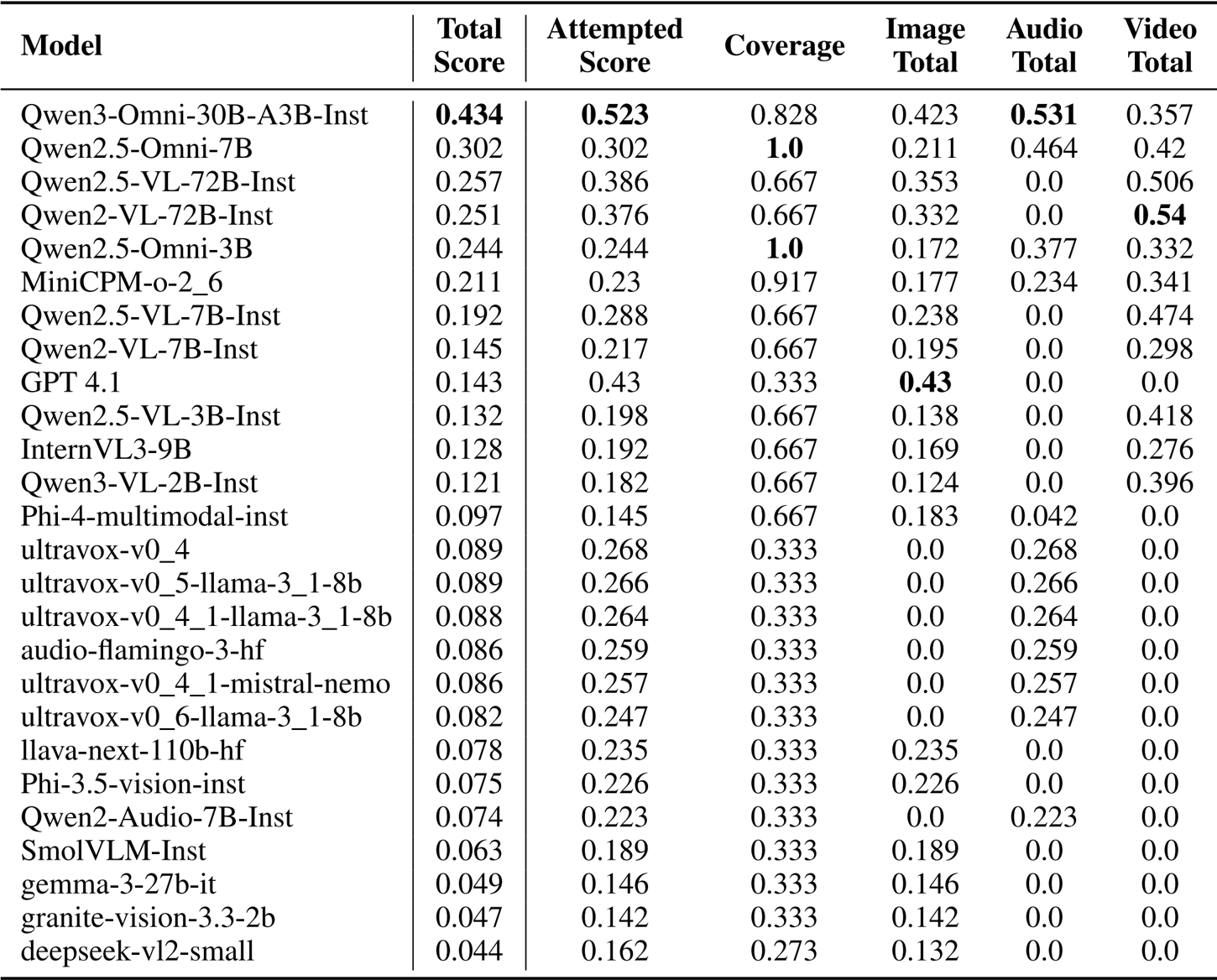
- 在 MERA Multi 基准测试上对 50 多个多模态模型(1B 到 110B 参数)进行的评估,使用精确匹配 (EM) 和裁判评分 (JS) 验证了跨图像、音频和视频模态的性能。
- Qwen3-Omni-30B-A3B-Instruct 凭借广泛的模态覆盖率和跨所有输入的强大能力,获得了 0.434 的最高总分。
- 在特定模态中,GPT 4.1 以 0.43 的分数领跑图像评估,而 Qwen2-VL-72B-Instruct 获得了最佳视频总分 (0.54),Qwen2.5-Omni-7B 在音频部分领先 (0.464)。
- 使用多模态语义成员推理攻击 (MSMIA) 进行的数据泄漏检测实验产生了高 AUC-ROC 分数,有效地识别了在测试数据上训练的模型,且假阳性率低。
- 裁判模型选择实验比较了微调编码器与零样本解码器,基于编码器的 RuModernBERT-base 实现了 0.964 的 F1 分数,证明在二元分类方面更胜一筹。
- 对提示表述的统计分析表明,没有单一提示在所有数据集中占主导地位,指标敏感度因任务而异(变化幅度为 0.1 到 0.2)。
作者使用一个结合了精确匹配和裁判评分指标的多模态评估框架来评估模型在图像、音频和视频任务中的表现。结果显示,全能模型 (omni-models) 由于覆盖范围更广而获得更高的总分,其中 Qwen3-Omni-30B-A3B-Instruct 以 0.434 的总分领跑排行榜,这得益于其在图像、音频和视频模态中的强劲表现。
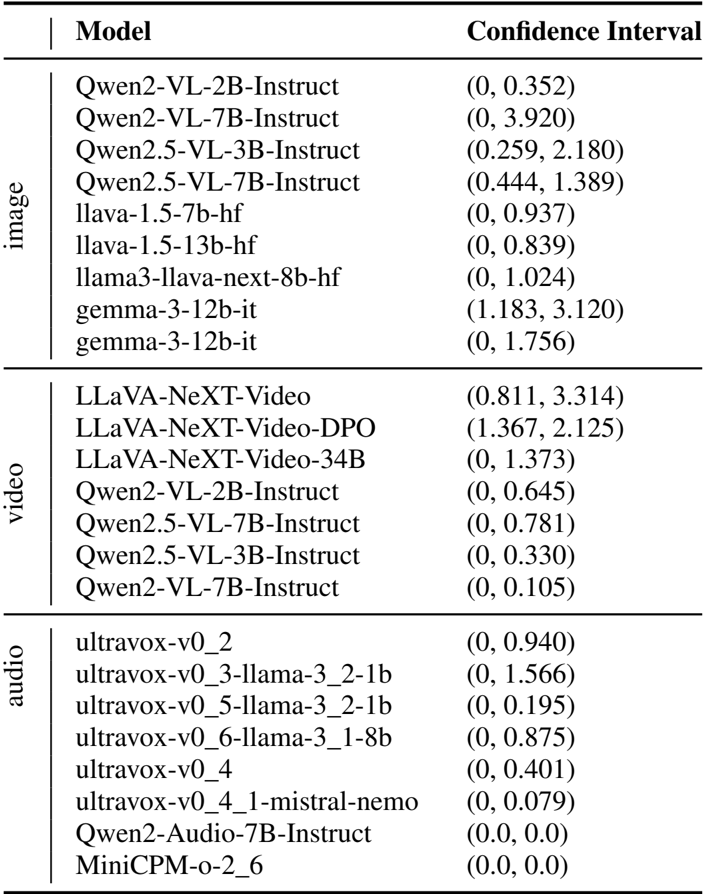
作者使用置信区间分析来评估跨模态模型性能差异的统计显著性。对于图像模态,像 Qwen2-VL-7B-Instruct 和 llava-1.5-13b-hf 这样的模型显示出较宽的置信区间,表明性能具有高变异性。在视频模态中,LLaVA-NeXT-Video-DPO 具有显著高的下界,表明性能强劲,而 Qwen2-VL-7B-Instruct 显示出非常窄的区间,表明结果一致。对于音频,ultravox-v0_2 和 ultravox-v0_4 具有宽区间,反映了不确定性,而 Qwen2-Audio-7B-Instruct 和 MiniCPM-o-2_6 的区间为零,表明未观察到其性能变化。
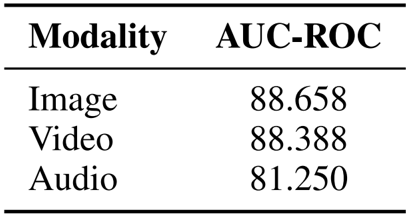
作者使用多模态语义成员推理攻击 (MSMIA) 来检测多模态模型中的数据泄漏,评估其在图像、视频和音频模态中的表现。结果表明,该方法实现了高 AUC-ROC 分数,表明在区分模型是否在特定多模态数据样本上进行过训练方面具有很强的能力,其中在图像和视频模态中观察到的性能最高。
作者使用多模态评估框架来评估跨图像、音频和视频模态的 50 多个模型,分数源自精确匹配和裁判评分指标。结果显示,Qwen3-Omni-30B-A3B-Instruct 以 0.434 的总分领先,这得益于高尝试得分和广泛的覆盖率,而具有更高覆盖率且在多种模态中表现强劲的模型通常获得更高的总分。