Command Palette
Search for a command to run...
Depth Anything 3:从任意视角恢复视觉空间
Depth Anything 3:从任意视角恢复视觉空间
Haotong Lin Sili Chen Junhao Liew Donny Y. Chen Zhenyu Li Guang Shi Jiashi Feng Bingyi Kang
摘要
我们提出Depth Anything 3(DA3),一种能够从任意数量的视觉输入中预测空间一致几何结构的模型,无论输入是否包含已知的相机位姿。在追求模型最小化设计的驱动下,DA3揭示了两个关键洞见:仅使用单一通用Transformer架构(例如标准的DINO编码器)作为主干网络即可满足需求,无需引入特定的结构设计;同时,采用单一的深度-射线预测目标,即可避免复杂多任务学习的必要性。通过教师-学生训练范式,DA3在细节表现与泛化能力方面达到了与Depth Anything 2(DA2)相当的水平。我们构建了一个全新的视觉几何基准,涵盖相机位姿估计、任意视角几何重建以及视觉渲染任务。在该基准上,DA3在所有任务中均取得了新的最先进性能,相较于先前的最先进方法VGGT,相机位姿估计准确率平均提升44.3%,几何重建准确率平均提升25.1%。此外,DA3在单目深度估计任务上也优于DA2。所有模型均仅在公开的学术数据集上进行训练。
一句话总结
来自字节跳动种子实验室的作者提出 Depth Anything 3(DA3),一种基于 Transformer 的极简但强大的模型,通过单一的深度-射线预测目标,从任意输入中预测一致的几何结构,无需专用架构或多任务学习;其在新的相机位姿估计、任意视角几何与渲染基准上达到最先进性能,显著优于 VGGT 和 DA2 等先前方法。
主要贡献
- Depth Anything 3 提出了一种极简的视觉几何重建建模方法,证明仅使用一个通用的 Transformer 主干网络和统一的深度-射线预测目标,即可处理任意数量的输入图像(无论是否已知相机位姿),无需针对特定任务进行架构特化。
- 该模型采用教师-学生训练范式结合伪标签,统一多样数据集,实现真实世界与合成数据上的高保真深度与位姿估计,在新的综合性视觉几何基准上达到最先进水平,平均在位姿精度上超越先前 SOTA 方法 VGGT 35.7%,在几何精度上提升 23.6%。
- 其在单目深度估计上优于 Depth Anything 2,并支持更优的前馈式 3D 高斯点云喷射(3D Gaussian splatting),表明增强的几何重建可直接提升新视角合成质量,确立其作为下游 3D 视觉任务的强大基础模型。
引言
作者致力于解决从任意输入视角(单图、多视角或视频)统一重建 3D 视觉几何的挑战,而无需依赖任务特化架构。以往多视角几何与单目深度估计工作通常采用复杂且专用的模型,难以扩展、泛化能力差,且对输入数量变化敏感;而近期统一方法常需复杂设计与从头联合训练,限制了其对大规模预训练视觉模型的利用。为克服这些局限,作者提出 Depth Anything 3(DA3),一种极简但强大的框架,基于单一通用视觉 Transformer(如 DINOv2)构建,无任何架构修改。该模型通过新颖的输入自适应跨视角自注意力机制与双 DPT 头,联合预测任意数量输入图像的深度与射线图,实现高效的跨视角推理与一致的几何重建。训练采用教师-学生范式,由高质量单目教师模型为多样化真实数据生成伪深度标签,确保即使在噪声或稀疏真值下仍保持几何保真度。该方法在新综合性视觉几何基准的 20 个设置中,有 18 个达到最先进水平,并实现更优的前馈式 3D 高斯点云喷射,证明一个简单、可扩展的基础模型可在下游 3D 视觉任务中超越专用系统。
数据集
-
训练所用数据集来自多个来源:DL3DV、TartanAir、IRS、UnrealStereo4K、GTA-SfM、Kenburns、PointOdyssey、TRELLIS 和 OmniObject3D。这些数据集被整合用于训练教师模型与前馈式 3DGS 模型,训练与测试集之间实施严格的场景级分离,防止数据泄露。
-
用于训练 NVS 模型的为 DL3DV 中的 10,015 个场景,其中 140 个基准场景完全独立于训练集。基准测试涵盖五个数据集:HiRoom(30 个合成室内场景)、ETH3D(11 个高分辨率室内外场景)、DTU(124 个物体的 22 个评估扫描)、7Scenes(低分辨率、运动模糊的室内场景)和 ScanNet++(20 个室内场景,含 iPhone LiDAR 与激光扫描生成的深度)。
-
各数据集均进行特定预处理:HiRoom、7Scenes 和 ScanNet++ 使用 0.05m 深度阈值计算 F1 指标;ETH3D 使用 0.25m。TSDF 融合参数因数据集而异——体素大小在 0.007m 至 0.039m 之间变化。评估时,7Scenes 和 ScanNet++ 的帧分别按 11 倍与 5 倍下采样,以降低计算负载。
-
训练过程采用动态批大小以保持每步一致的 token 数量。图像分辨率从八个选项中随机采样,包括 504×504 及其宽高比变体。504×504 基础分辨率可被 2、3、4、6、9、14 整除,支持常见照片宽高比。对于 504×504,每场景视图数在 2 至 18 之间均匀采样。
-
训练在 128 块 H100 GPU 上运行 200k 步,包含 8k 步预热,峰值学习率为 2×10⁻⁴。第 120k 步后,监督信号从真值深度切换为教师模型标签。训练中以 20% 概率随机应用位姿条件。
-
数据预处理包括过滤无效或错位样本:TartanAir 移除游乐场场景,并在特定场景中裁剪深度;IRS 使用 Canny 边缘进行对齐检查,过滤错位图像-深度对;UnrealStereo4K 移除问题场景及缺失深度的帧;GTA-SfM 与 OmniObject3D 裁剪最大深度值;PointOdyssey 移除两个地面深度错误的场景;TRELLIS 排除无纹理文件;Kenburns 将深度裁剪至 50,000。
-
为评估视觉渲染质量,构建新 NVS 基准,包含 DL3DV(140 场景)、Tanks and Temples(6 场景)与 MegaDepth(19 场景),每场景约 300 帧采样。使用 COLMAP 提供的真值位姿进行公平比较,评估指标包括 PSNR、SSIM 与 LPIPS。
方法
作者采用统一的 Transformer 架构构建 Depth Anything 3(DA3),旨在从任意数量视觉输入中预测空间一致的几何结构,无论相机位姿是否已知。模型核心为单一 Transformer 主干,具体为通用 DINO 编码器,作为无架构特化的通用特征提取器。该主干通过输入自适应自注意力机制实现跨视角推理。Transformer 被划分为两组不同层:前 Ls 层在每张图像内部执行自注意力,后续 Lg 层通过联合处理所有图像 token 的张量重排方案,交替执行跨视角与组内注意力。该设计使模型天然支持单目与多视角输入,且无额外计算开销,如框架图所示。

为适应有位姿与无位姿输入,模型引入相机条件注入机制。当相机参数可用时,轻量级 MLP 将相机视场角、旋转四元数与平移向量投影为可学习的相机 token,并前置至图像 patch token 之前;若无相机参数,则使用共享的可学习相机 token。这些相机 token 被整合进 Transformer 的注意力机制中,提供显式几何上下文或一致的可学习占位符,使模型能适应不同输入条件。
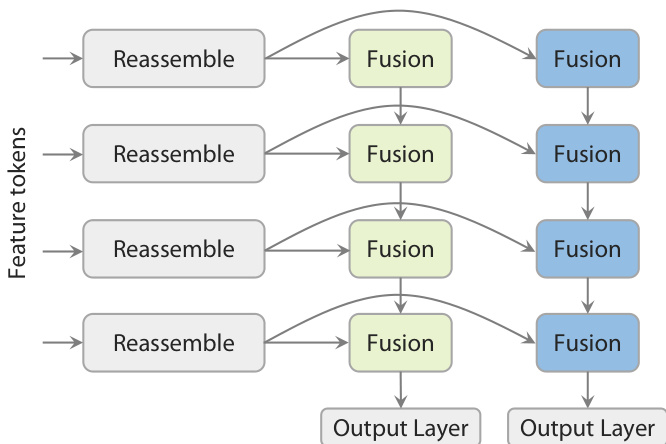
最终预测阶段采用新颖的 Dual-DPT 头,联合生成密集深度图与射线图。如图所示,该头首先通过共享的重组装模块处理主干特征。处理后的特征通过两组不同的融合层(分别用于深度分支与射线分支)进行融合,再送入独立输出层。该架构确保两项预测任务基于同一组处理后的特征,促进强交互性,同时避免冗余中间表示。
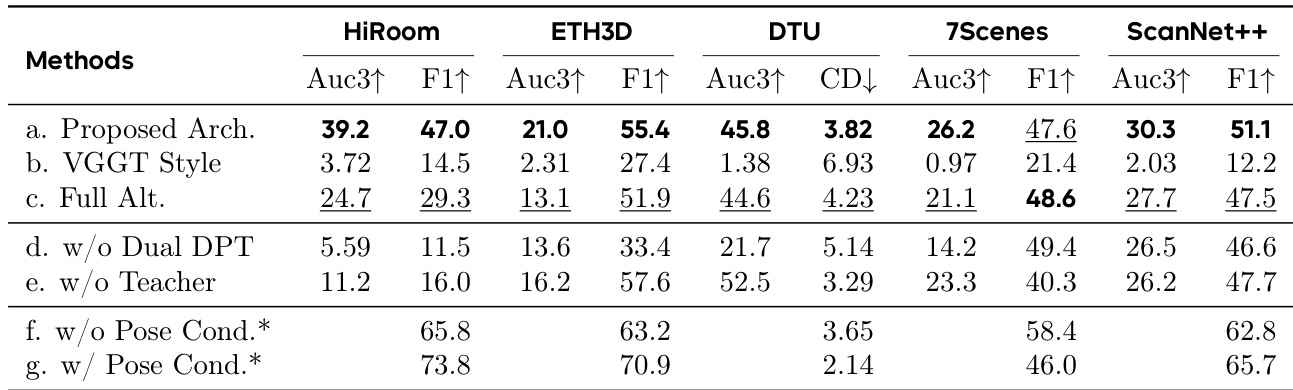
模型训练基于教师-学生范式,以克服真实世界深度数据噪声大、不完整的问题。一个单目相对深度估计教师模型仅在大规模合成语料上训练,生成高质量伪标签。这些伪深度图通过鲁棒的 RANSAC 最小二乘法与可用的噪声真值对齐,确保尺度与偏移一致性。学生模型 DA3 在真实世界数据上使用对齐后的伪标签进行训练。整体训练目标为多个项的加权和,包括深度损失、射线图损失、点云一致性损失、相机位姿损失与梯度损失。深度与射线图预测通过一个共同尺度因子归一化,该因子定义为有效重投影点图的均值 ℓ2 范数,以稳定训练。该方法使模型实现高细节与强泛化能力,超越先前最先进方法。
实验
- 使用教师模型预测作为监督,训练度量深度估计模型,在 ETH3D(δ₁ = 0.917,AbsRel = 0.104)与 SUN-RGBD(AbsRel = 0.105)上达到最先进结果,超越 UniDepthv2 与其他 SOTA 方法。
- 引入视觉几何基准,评估位姿精度、重建质量与新视角合成,使用 AUC、Chamfer 距离、F1 分数与渲染保真度作为指标。
- 证明深度-射线表示足以实现高质量几何预测,在 Auc3 上优于深度+相机与深度+点云组合达 100%。
- 证明单一通用 Transformer 与部分注意力交替优于多阶段 VGGT 风格架构,验证所提设计的有效性。
- 学生模型在单目深度估计上表现强劲,相比 DA2 在 ETH3D 上提升超 10%,在 SINTEL 上提升 +5.1%,归因于增强的教师监督与更大规模训练数据。
- 验证教师模型监督显著提升深度锐度与细节,尤其在合成与高结构场景(如 HiRoom)中,尽管在 NYUv2 与 KITTI 上指标提升较小。
- 在前馈新视角合成中表现顶尖,基于 DA3 的模型在多样场景中超越专用 3DGS 框架(如 pixelSplat、MVsplat),证明大规模预训练与鲁棒几何主干的强大能力。
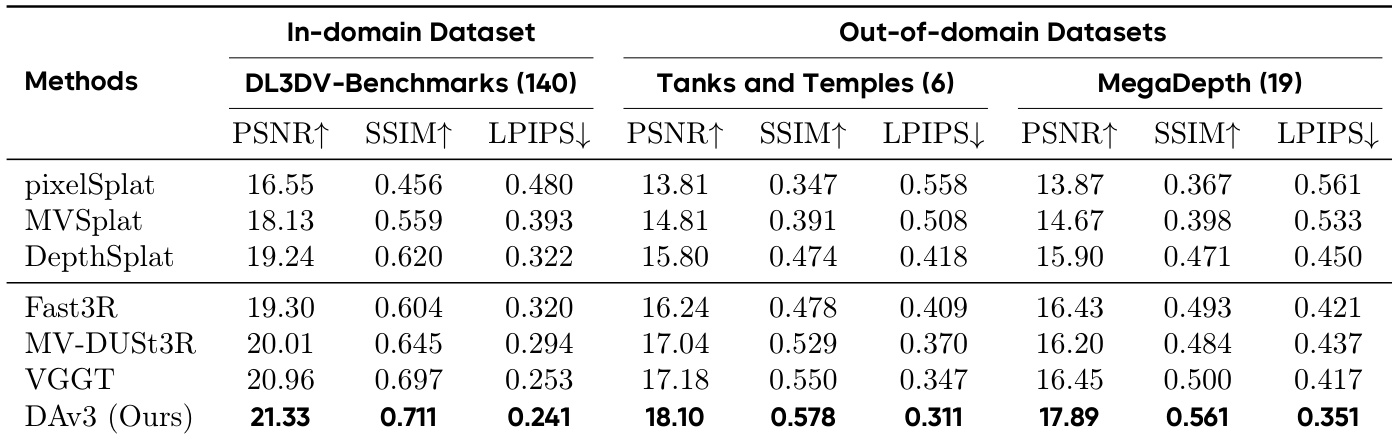
结果表明,所提 DA3 模型在所有指标与数据集上均表现最佳,无论在域内还是域外基准上均超越所有基线。在 DL3DV-Benchmarks 上,DA3 达到最高 PSNR、SSIM 与 LPIPS 分数,并在 Tanks and Temples 与 MegaDepth 上三项指标均领先,展示出卓越的新视角合成质量。
作者评估不同训练数据与损失配置对单目深度估计的影响。结果表明,使用 V3 数据结合多分辨率训练(V3 + mr)在所有指标上表现最佳,δ₁ 为 0.938,AbsRel 为 0.072,SqRel 为 0.452。完整损失(包含提出的 normal-loss 项)相比 MAE-Loss 基线进一步提升性能,δ₁ 达 0.919,AbsRel 为 0.087,SqRel 为 0.596。

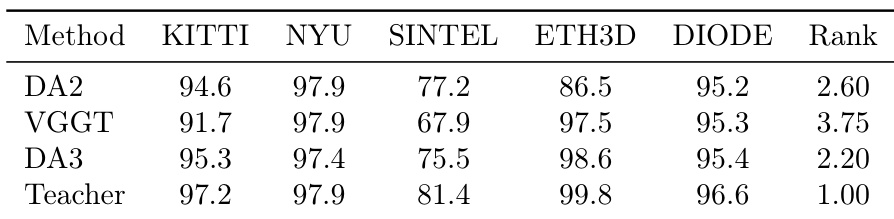
作者将 DA3 模型与 DA2 及 VGGT 在单目深度估计基准上进行比较,结果显示 DA3 在所有数据集上整体表现最佳,综合排名为 2.20,优于 DA2(排名 2.60)与 VGGT(排名 3.75)。教师模型取得最高排名 1.00,表明其在评估数据集上表现最优。
作者将新单目学生模型与 DA2 在多个基准上进行对比,结果显示新学生模型在所有数据集上均优于 DA2。在 ETH3D 上,单目学生模型相比 DA2 提升超过 10%,在 Sintel 等挑战性数据集上也表现出显著优势。

作者评估不同架构与训练组件对几何估计性能的影响。结果表明,所提架构在所有数据集上显著优于 VGGT 风格与全交替基线,最佳结果由完整模型实现。移除 Dual-DPT 头或教师监督导致性能大幅下降,而增加位姿条件进一步提升结果,尤其在 HiRoom 与 ScanNet++ 等数据集上表现更优。