Command Palette
Search for a command to run...
微小模型,强大逻辑:基于多样性的优化策略激发VibeThinker-1.5B的类大模型推理能力
微小模型,强大逻辑:基于多样性的优化策略激发VibeThinker-1.5B的类大模型推理能力
Sen Xu Yi Zhou Wei Wang Jixin Min Zhibin Yin Yingwei Dai Shixi Liu Lianyu Pang Yirong Chen Junlin Zhang
摘要
挑战当前普遍认为小型模型固有地缺乏强大推理能力的共识,本报告提出 VibeThinker-1.5B——一款基于我们提出的“谱域到信号域原理”(Spectrum-to-Signal Principle, SSP)训练而成的15亿参数密集型模型。该成果打破了依赖模型参数规模扩展以提升能力的传统范式,与 DeepSeek R1(6710亿参数)和 Kimi k2(超过1万亿参数)等大规模模型的发展路径形成鲜明对比。SSP 框架首先通过两阶段多样性探索蒸馏(Two-Stage Diversity-Exploring Distillation, SFT)生成广泛多样的解决方案,随后采用最大熵引导的策略优化(MaxEnt-Guided Policy Optimization, RL)强化正确信号。整个训练过程总成本仅为7800美元,却使 VibeThinker-1.5B 在推理能力上超越了 Magistral Medium 和 Claude Opus 4 等闭源模型,并达到与开源模型 GPT OSS-20B Medium 相当的水平。尤为突出的是,在三项数学基准测试中,VibeThinker-1.5B 的表现显著优于参数规模大400倍的 DeepSeek R1:在 AIME24 上取得80.3分(DeepSeek R1为79.8),AIME25 上达74.4分(DeepSeek R1为70.0),HMMT25 上取得50.4分(DeepSeek R1为41.7)。相较其基础模型(对应分数分别为6.7、4.3和0.6),性能实现质的飞跃。在 LiveCodeBench V6 上,该模型获得51.1分,优于 Magistral Medium 的50.3分,且远超其基础模型的0.0分。上述结果表明,通过创新的训练范式,小型模型同样可实现与大型模型相当的推理能力,大幅降低训练与推理成本,从而推动先进人工智能研究的普惠化与民主化。
一句话总结
来自新浪微博公司的作者介绍了 VibeThinker-1.5B,这是一个拥有 15 亿参数的模型,通过一种新颖的“谱到信号原理”(Spectrum-to-Signal Principle)框架,实现了大模型级别的推理性能。该框架在监督微调中增强输出多样性,并通过 MaxEnt 引导的策略优化(MaxEnt-Guided Policy Optimization)放大正确的推理路径,使其在关键基准测试中超越参数量超过 400 倍的模型,同时将训练成本降低了两个数量级。
主要贡献
-
本工作挑战了当前普遍认为只有大规模模型才能实现高级逻辑推理的观念,证明了一个紧凑的 15 亿参数模型 VibeThinker-1.5B,可以在数学定理证明和编程等复杂推理任务上达到甚至超越数百倍于其规模的模型性能。
-
核心创新在于“谱到信号原理”(Spectrum-to-Signal Principle, SSP),该原理将监督微调与强化学习解耦为两个独立阶段:一个探索多样性的蒸馏阶段,用于生成广泛的推理路径;随后是 MaxEnt 引导的策略优化(MGPO)阶段,通过不确定性感知训练放大高质量解。
-
VibeThinker-1.5B 在 AIME24、AIME25 和 LiveCodeBench v6 等严格基准上取得最先进结果,超越了参数量超过 400 倍的模型(如 DeepSeek R1-0120 和 Kimi-K2),且训练成本低于 8000 美元,证明算法创新可显著降低高性能推理系统的成本与环境影响。
引言
作者挑战了当前业界普遍认为极端参数扩展是语言模型实现强大逻辑推理所必需的信念。尽管 DeepSeek-R1 和 Kimi-K2 等大模型凭借巨大规模树立了新基准,但以往研究大多忽视了紧凑模型的潜力——这些模型通常被认为因容量不足和训练方法欠佳而推理能力受限。作者提出 VibeThinker-1.5B,一个 15 亿参数的密集模型,通过“谱到信号原理”重新定义后训练流程,在数学与编程基准上达到最先进性能,超越了数百倍于其规模的模型。该方法将监督微调与强化学习解耦为两个阶段:一个探索多样性的蒸馏阶段,用于生成广泛的推理路径;随后是 MaxEnt 引导的策略优化阶段,高效放大高质量解。最终结果是一个高效、低成本的模型,训练成本低于 8000 美元,其推理能力与更大系统相当,表明算法创新可显著提升小模型性能,推动先进 AI 研究的普惠化。
数据集
- 训练数据主要由公开可用的开源数据构成,少量来自内部专有合成数据,旨在提升领域覆盖度与模型鲁棒性。
- 为确保评估无偏且泛化真实,监督微调(SFT)与强化学习(RL)阶段均实施了严格的去污染处理。
- 在匹配前进行了文本标准化,包括移除无关标点与符号,以及大小写归一化,以降低噪声并提升匹配精度。
- 语义去污染采用 10-gram 匹配技术,检测并移除与评估集存在潜在语义重叠的训练样本,增强对局部语义相似性的敏感度。
- 去污染过程有助于防止训练与评估数据之间的信息泄露,确保模型在 AIME25 和 LiveCodeBench 等基准上的表现反映真实的推理与泛化能力,而非数据污染。
- 尽管部分基础模型(如 Qwen 2.5-7B)存在数据泄露争议,但 VibeThinker-1.5B 模型在 2025 年发布的基准(如 AIME25、HMMT25)上表现出色,这些数据在模型定型前尚未存在,有力反驳了泄露指控。
- 基础模型在 LiveCodeBench v5 和 v6 上的编码能力极低(得分为 0.0),但后训练优化后分别提升至 55.9 和 51.1,甚至超过 Magistral medium 在 v6 上的表现。
- 这些提升表明性能进步源于针对性对齐与先进训练技术,而非数据污染。
方法
作者利用“谱到信号原理”(Spectrum-to-Signal Principle, SSP)设计了 VibeThinker-1.5B 的两阶段训练框架,重新定义了监督微调(SFT)与强化学习(RL)之间的协同机制。该框架分为两个独立阶段:谱阶段(Spectrum Phase)与信号阶段(Signal Phase)。谱阶段在 SFT 阶段实施,旨在生成广泛而多样的合理解,从而最大化模型的 Pass@K 指标。该阶段通过“两阶段探索多样性蒸馏”方法实现。第一阶段为“领域感知多样性探测”,将问题空间划分为子领域(如代数、几何、微积分、统计),并通过在探测集上最大化 Pass@K 来识别各子领域的专家模型。第二阶段为“专家模型融合”,通过加权平均各专家模型的参数,将其合成一个统一的 SFT 模型,从而构建出具有最大解谱的模型。
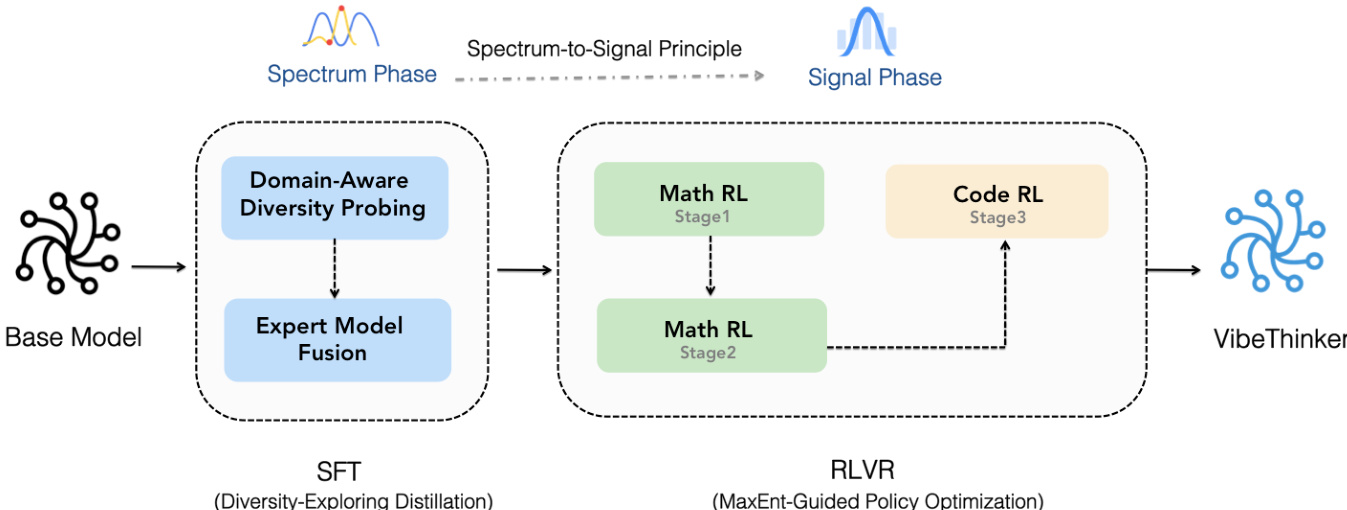
信号阶段在 RL 阶段实施,负责从 SFT 阶段建立的多样化解池中放大正确的“信号”。该阶段由“MaxEnt 引导的策略优化”(MaxEnt-Guided Policy Optimization, MGPO)框架驱动,该框架运行于组相对策略优化(Group Relative Policy Optimization, GRPO)框架内。MGPO 通过动态优先级机制,聚焦于模型当前表现最不确定的问题,因为这代表了关键的学习前沿。这一机制通过基于 Kullback-Leibler(KL)散度的加权函数实现,该散度衡量问题实际准确率与理想最大熵状态(准确率为 0.5)之间的差异。这种“熵偏差正则化”调节 GRPO 目标中的优势项,有效构建了一个引导模型聚焦于最具教学价值问题的课程。RL 阶段分为子阶段:首先在 16K 上下文窗口中进行数学推理,扩展至 32K,随后进入代码生成,确保系统化且专注的优化过程。
实验
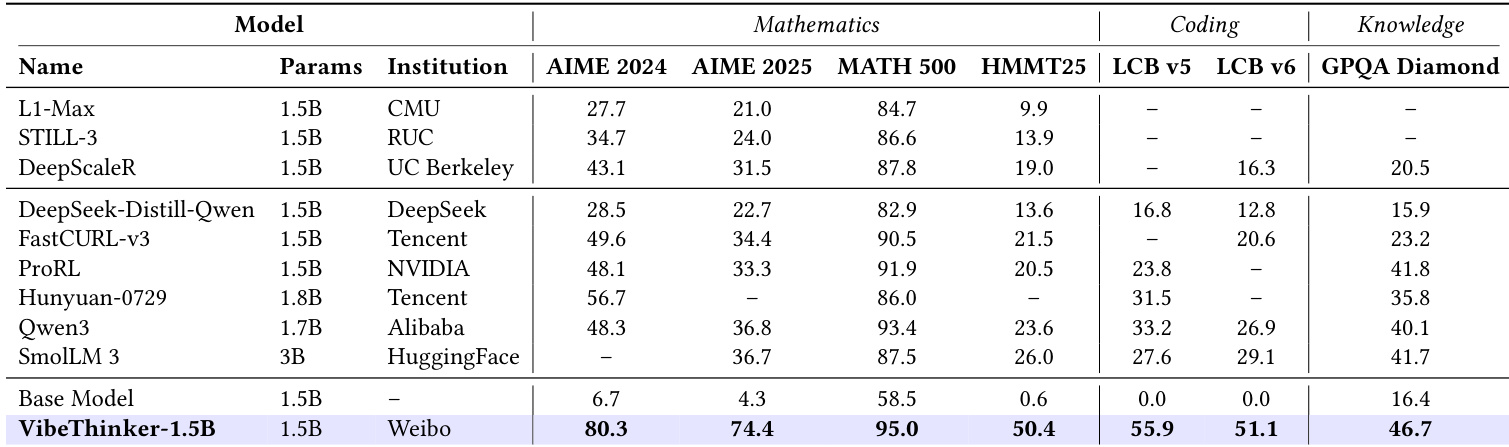
- VibeThinker-1.5B 在 AIME25 上达到 74.4 的通过率,成为 30 亿参数以下模型中的最先进水平,超越 FastCURL、ProRL 和 Qwen3-1.7B,并在数学、编程和知识任务上大幅领先于 SmolLM-3B 和 Qwen2.5-Math-1.5B(基础版)等更大模型。
- 在 AIME25 上,VibeThinker-1.5B 超过 DeepSeek-R1-0120,其表现与 MiniMax-M1 相当,表明小模型即使在参数量相差 10–100 倍的情况下,仍可与大型推理模型比肩。
- 在 LiveCodeBench V5 上得分为 55.9,在 V6 上得分为 51.1,展现出强大的编程能力,但与顶级非推理模型相比仍存在性能差距,这归因于基础模型在代码预训练上的局限。
- 在 GPQA-Diamond 上得分为 46.7,显著低于顶级模型(如 70–80+),证实小规模模型在广泛知识保留方面存在固有局限。
- 后训练成本低于 8000 美元(H800 上 3900 GPU 小时),比当前最先进大模型低一到两个数量级(如 DeepSeek R1:29.4 万美元,MiniMax-M1:53.5 万美元),支持低成本训练与边缘部署,推理成本降低 20–70 倍。
作者使用 VibeThinker-1.5B 证明,尽管参数远少于当前最先进模型,小规模模型仍可在复杂推理任务上实现具有竞争力的性能。结果表明,VibeThinker-1.5B 在数学基准上超越所有非推理模型,并在数学、编程和知识任务上优于多个大型推理模型(包括 DeepSeek R1-0120)。
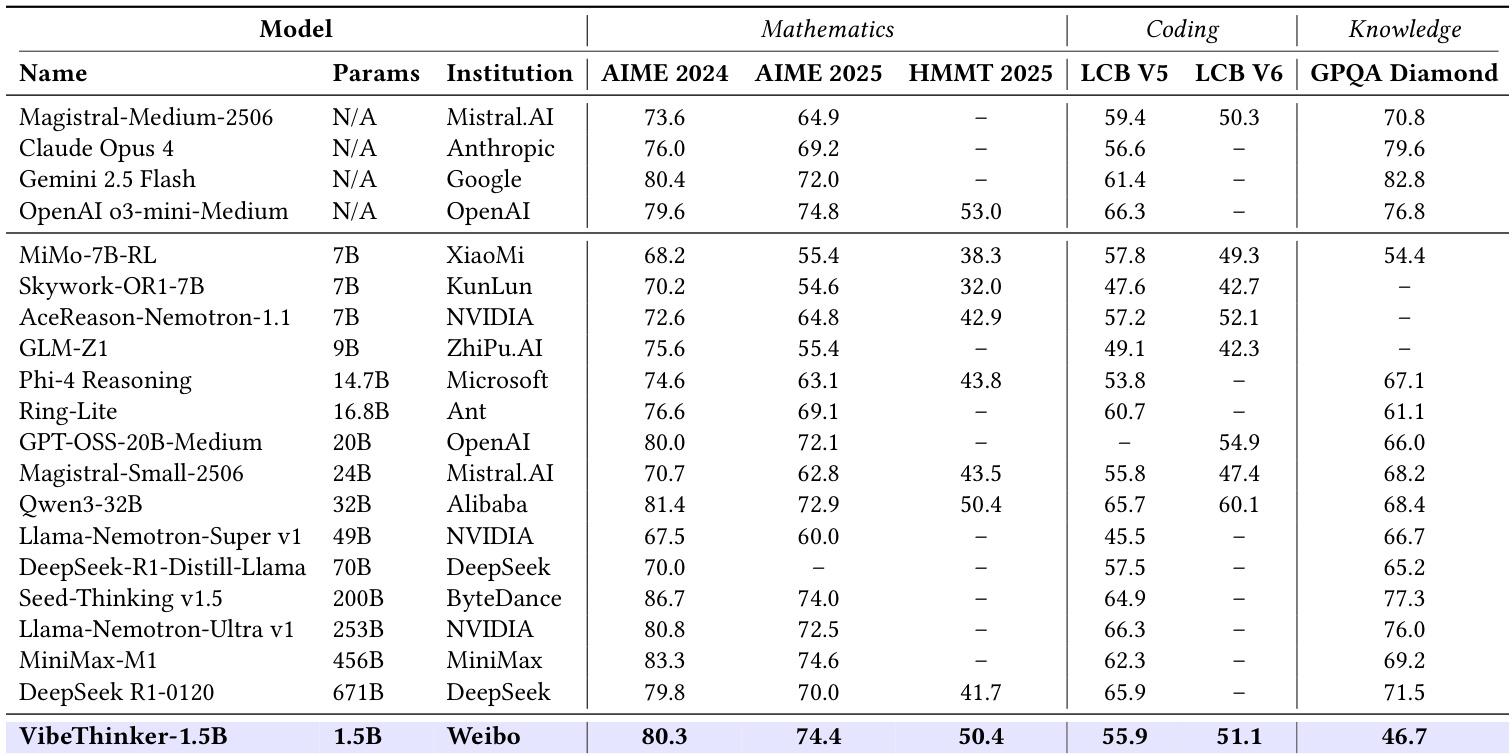
作者使用 VibeThinker-1.5B 证明,尽管参数量有限,小规模模型仍可在推理任务中实现优异表现。结果表明,VibeThinker-1.5B 在关键基准(包括 AIME 2024 和 AIME 2025)上超越所有其他 30 亿参数以下模型,并在数学与编程任务上达到与大型模型相当的分数,但在通用知识方面仍存在差距。
作者将 VibeThinker-1.5B 的后训练成本与更大模型进行对比,结果显示,尽管参数量为 15 亿,VibeThinker-1.5B 总成本仅为 7800 美元,远低于 MiniMax-M1 的 53.5 万美元和 DeepSeek-R1 的 29.4 万美元。结果表明,VibeThinker-1.5B 在 AIME25 上取得 74.4 的高分,性能与大型模型相当,同时训练成本仅为后者的极小部分。

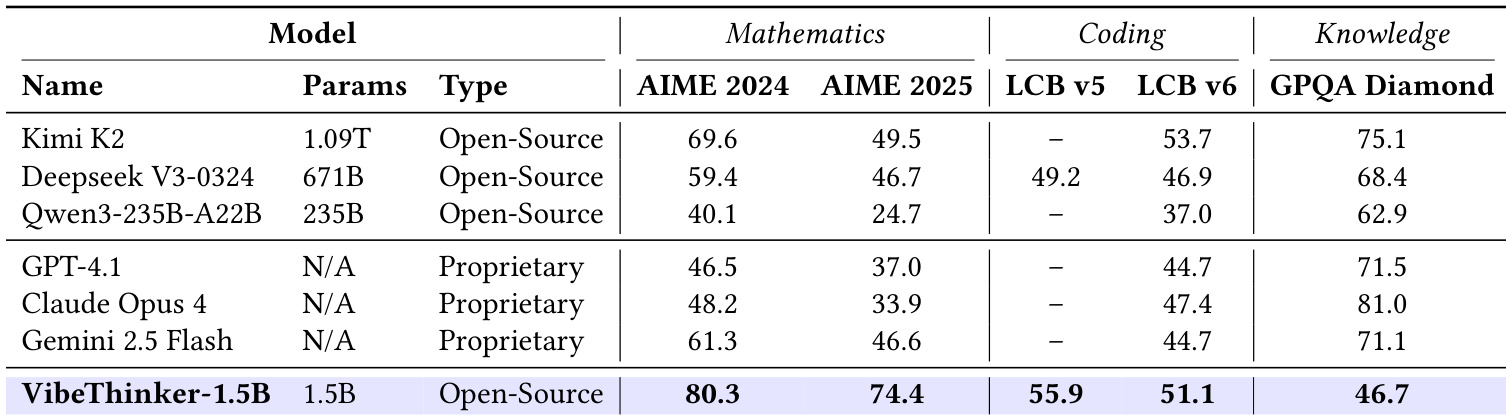
作者将 VibeThinker-1.5B 与顶级非推理模型进行对比,发现尽管其规模显著更小,但在 AIME 2024 和 AIME 2025 基准上超越所有模型,并在代码生成任务中表现优异。然而,在 GPQA Diamond 知识基准上仍存在显著性能差距,表明小模型在广泛领域知识方面仍面临固有局限,难以与大模型比肩。