Command Palette
Search for a command to run...
数据集汇总丨英伟达/OpenAI 及多所科研机构开源推理数据集,覆盖数学/全景空间/Wiki 问答/科研任务/视觉常识等

当大模型从「能说会写」迈向「能推理、会思考」,数据的重要性正在被重新定义。
过去,海量通用语料支撑了语言模型的表达能力;而今天,真正决定模型上限的关隘,正在逐步过渡为结构清晰、逻辑严密、具备多步推演过程的推理数据。无论是复杂数学问题、跨领域知识问答,还是多步骤决策与工具调用能力,背后都离不开高质量推理数据集的支撑。
推理数据集可能专注于数学与逻辑,亦或通过合成方式构造复杂推理链条,再者也可用于多任务能力评估,或是服务于科研基准测试与问答系统优化。但与此同时,这些数据资源也呈现出明显的碎片化特征,甚至以不同格式存在,难以统一使用。这也让不少开发者和研究者在「找数据」这一步,就消耗了大量时间。
因此,HyperAI 整理了一批优质的推理数据集,覆盖多领域、多任务推理、合成推理训练数据,科研评测基准以及大规模问答数据,并支持下载或在线使用数据集,降低推理数据集使用门槛。
更多优质数据集:
Open-RL 推理问题数据集
* 在线使用:
Open-RL 是由 Turing 于 2026 年发布的多领域推理问题数据集,包含物理学、数学、生物学和化学的独立、可验证和明确的 STEM 推理问题。
每个问题需要多步推理,涉及符号操作和/或数值计算,且具有可客观验证的最终答案。该数据集适合用于强化学习微调、奖励建模、结果监督训练以及可验证推理基准测试。每个问题需要多步推理,并涉及符号操作和数值计算,具有可验证的最终答案。
CHIMERA 通用推理合成数据集
* 在线使用:
CHIMERA 是一个专为推理训练设计的合成推理数据集,涵盖广泛的 STEM 学科,并提供长链思维(CoT)轨迹。
该数据集包含 9,225 个问题,8 个学科(数学、计算机科学、化学、物理、文学、历史、生物学、语音学),所有示例均由大型语言模型(LLM)生成,并通过自动验证,无需人工标注。
学科分布:
* 数学:4,452
*计算机科学:1,303
*化学:1,102
*物理:742
*文学:504
*历史:422
*生物学:383
*语言学:317
Nemotron-Math-v2 数学推理数据集
* 在线使用:
Nemotron-Math-v2 是一个由 NVIDIA Corporation 发布的数学推理数据集,主要用于训练 LLM 以执行结构化数学推理,研究工具增强的推理与纯语言推理的差异,以及构建长语境或多轨迹推理系统等。
该数据集包含约 34.7 万个高质量数学问题和 700 万个模型生成的推理轨迹。每个问题在六种配置下进行求解:高 / 中 / 低推理深度与是否使用 Python TIR,答案通过 LLM 作为裁判的管道进行验证。
OmniSpatial 全景空间推理基准数据集
* 在线使用:
OmniSpatial 是由清华大学联合上海期智研究院、上海人工智能实验室等机构于 2025 年发布的一个全景空间推理基准数据集,相关论文成果为「OmniSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Language Models」,旨在填补视觉 – 语言模型空间理解评测的空白。
该数据集包含约 1,533 个图像 – 问答样本,涵盖动态推理(Dynamic Reasoning)、复杂空间逻辑(Complex Spatial Logic)、空间交互(Spatial Interaction)和视角转换(Perspective Taking)四大类空间推理任务,共计 50 个子任务。数据来源多样,涵盖互联网图像、心理学测试与驾驶考试题,标注经多轮审核,保证质量与多样性。与传统基准相比,OmniSpatial 避免了模板化构造,更贴近真实复杂场景,不仅测试基础空间关系(如前后、左右、远近),还强调多物体交互、场景变化和跨视角推理。
该数据集适用于训练与评测多模态大模型的空间推理能力,特别是在智能导航、增强/虚拟现实以及复杂场景理解等应用中,是一个全面而具有挑战性的标准化基准数据集。
FrontierScience 推理科研任务评测数据集
* 在线使用:
FrontierScience 是由 OpenAI 于 2025 年发布的一个推理 + 科研任务评测数据集,旨在系统性评估大模型在专家级科学推理与科研子任务的能力。
该数据集采用了「专家原创 + 双层任务结构 + 可自动评分机制」的设计机制,划分为两个子集,分别对应封闭式精确推理与开放式科研推理两类能力:
Olympiad 数据集
由国际物理、化学和生物奥林匹克竞赛的奖牌获得者及国家队教练原创设计,问题难度对标 IPhO 、 IChO 和 IBO 等国际顶级竞赛;聚焦短答案推理任务,要求模型输出单一数值、代数表达式或可模糊匹配的生物学术语,以保证结果的可验证性和自动评测的稳定性。
Research 数据集
由博士生、博士后及教授等在职科研人员撰写,题目模拟真实科研过程中可能遇到的子问题,覆盖物理、化学与生物三大领域。每道题目均配套 10 分制的细粒度评分,用于评估模型在答案正确性之外,在建模假设、推理路径与中间结论等多个关键环节的完成情况。
HotpotQA 问答数据集
* 在线使用:
HotpotQA 数据集是一个在英文维基百科上收集的大规模问答数据集,包括 11.3 万个众包问题,要回答这些问题,需要参照两篇维基百科文章的介绍段落。
每个问题都包含两个黄金段落 (gold paragraph) 以及部分段落中的句子列表,这些句子列表中提供的支持性事实,被认定为是回答问题所必需的。该数据集具有以下特征:
* 问题需要在多个支持文档中查找和推理才能回答;
* 问题是多样化的,不受任何预先存在的知识库或知识模式的限制;
* 该数据集提供推理所需的句子级支持事实,让 QA 系统在强监督下进行推理并解释预测;
* 该数据集提供了一种新型的事实比较问题来测试 QA 系统提取相关事实并进行必要比较的能力。
VCR 视觉常识推理数据集
* 在线使用:
VCR 全称 Visual Commonsense Reasoning,是一个用于视觉常识推理的大规模数据集。该数据集提出了关于图像的具有挑战性的问题,机器需要完成两个子任务:正确回答问题以及提供理由证明其答案的合理性。
VCR 数据集包含大量问题,其中 212K 个用于训练,26K 个用于验证,25K 个用于测试。答案和理由来自超过 110K 个不重复的电影场景。

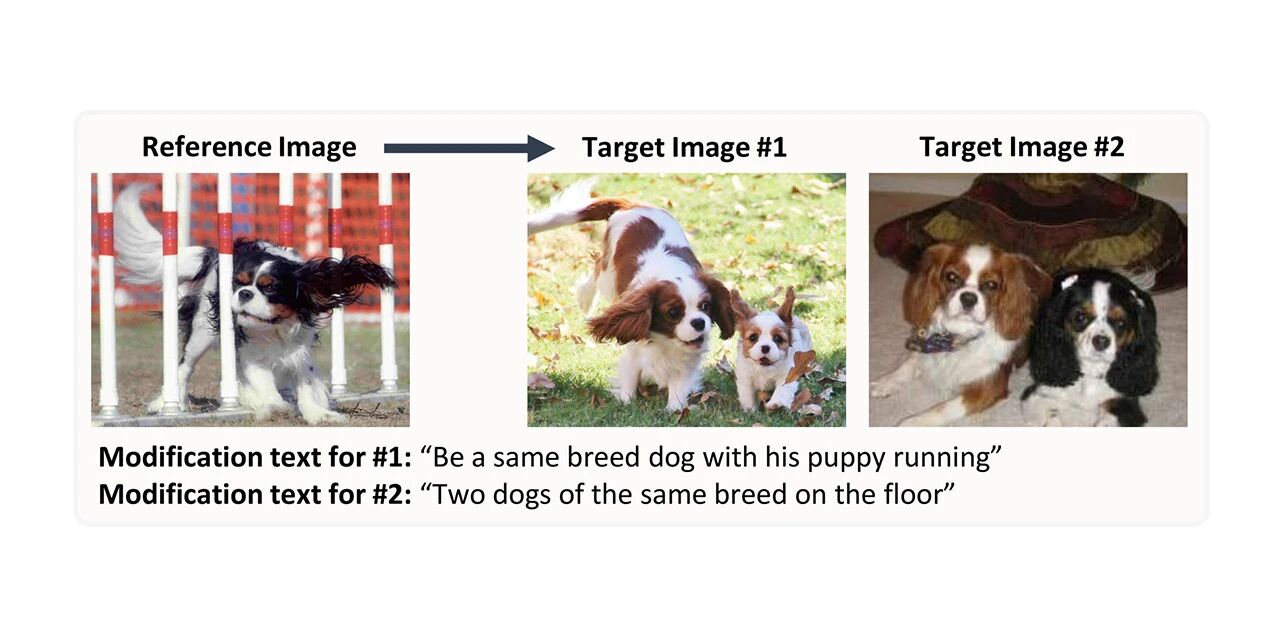
CIRR 图像合成检索数据集
* 在线使用:
CIRR 全称 Compose Image Retrieval on Real-life images,包含超过 36,000 对众包的、开放域图像与人工生成的修改文本。该数据集旨在促进未来对视觉语言学概念的微妙推理的研究,以及用对话进行迭代检索,通过更强调区分开放域视觉相似图像来解决现有数据集的缺陷。