Command Palette
Search for a command to run...
别回校园了,老师的套路都智能了。

By 超神经
今天是国际教师节,朋友圈已经被各种送给老师的祝福攻占,大家纷纷致敬老师、怀念校园,但如果知道了现在中学生「水深火热」的生存环境,不知道会作何感想。
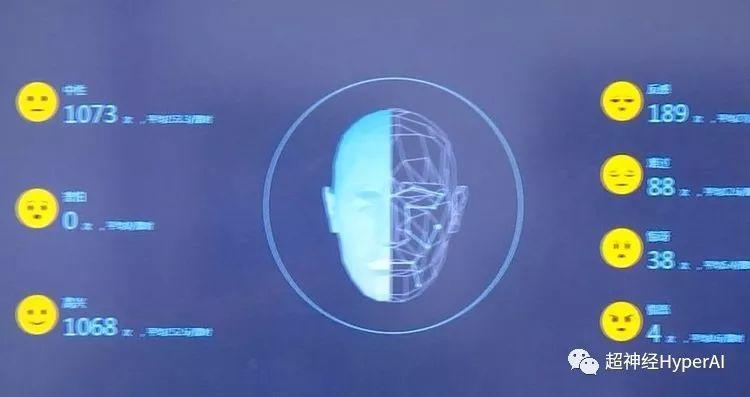
最近,杭州第十一中学试行的慧眼系统,通过教室内安装组合摄像头,捕捉学生在课堂上的表情和动作,借助人脸识别技术,采集学生的 6 种课堂行为和 7 种课堂表情。

这套引起了轩然大波的教学系统叫「智慧课堂行为管理系统」简称「慧眼」。
据说它能准确捕捉学生阅读、起立、举手、趴桌子、听讲和书写等 6 种行为,并结合学生面部表情分析出中性、高兴、难过、愤怒、害怕、反感和惊讶 7 种情绪。
慧眼——全班最爱打小报告的同学
这些信息经过系统简单处理后,会生成一串代码,比如认真听课为 A 、趴下睡觉为 B 、回答问题为 C ,并以此来判断学生状态。好的状态,比如认真听课就会加分,不好的状态,比如上课睡觉就会减分。
这些数据会在课后直接推送给授课老师,便于让老师了解课堂效果和学生们的反应。
老师以此来优化授课方式,学校也能用来评判老师的授课质量。但由于摄像头的存在,难免会让学生有些不自在,这也是可以理解的。
对于吃瓜群众担心的隐私和数据泄露问题,据说这套系统生成的数据信息,仅任课老师,及学校高层有权查看,其他老师或者校外人员无权查看。

(上面红圈是面部识别设备,下面是采集信息的摄像头)
硬件部分是由一个可旋转摄像头和一个面部识别仪组成,每间教室大概有三台,隔 30 秒就会扫描一次。
所有的摄像头仅用来搜集行为信息,不会用来监控,也不会录像,不存在隐私和数据泄露的问题。
十一中学计划今年在所有教室里安装该系统,观察学生课堂情绪的同时,还能刷脸考勤。不过,目前该系统仍处于初级阶段,还需要更多数据来供它学习,以提高情绪识别的准确性。
在未来,他们打算将学校所有的刷卡行为都用刷脸替代,打造全国第一家无卡校园,不知道这是不是受隔壁阿里马云爸爸的启发。
课堂监控,说不定是件好事
把高科技带到校园,杭州十一中应该算头一个,但也希望学校不要把用于提高教学质量的情绪识,用成了实时监控工具。毕竟即使校园是个公共场合,但是每个同学还都应该在一定限度内,保留一些个人隐私。
说到底,慧眼系统之所以引起关注和讨论,是因为大家觉得学生被监控。但反过来想想,慧眼宣称数据不存储,不公开,其实跟传统意义上老师的眼睛差不多。
所以最重要的还是「用户协议」,校方现在最应该明确的是,慧眼中视频内容的使用途径、授权范围。
情绪识别的技术实现
让机器可以识别人类情感已经成为事实,但海量训练数据和模型构建的复杂性,却让很多研究者望而却步。
现在,有五位大佬搞出一个轻量级情感识别模型,不仅可以自动完成训练集分类,模型构建过程也很简单,大大降低了情感识别模型的创建门槛。
情感识别是在图像和人脸识别等技术基础上,通过分析人物身体行为(如面部表情识别、语音和姿态等),识别人类情感状态。

人类面部情感的多样性
虽然用于情感识别的神经网络已经在医疗保健、客户分析等领域被广泛应用,但大部分情感识别模型,仍无法深入理解人类情感,而且构建这样一个模型成本很高,开发难度也大。
轻量情感识别模型,了解一下
为了解决这个问题,来自法国 Orange Labs 和诺曼底卡昂大学(University of Caen Normandy,简称 UNICAEN)的五位工程师联合发表了一篇论文 《An Occam’s Razor View on Learning Audiovisual Emotion》。
他们在论文中提出一种基于视听情感识别(即利用音频和视频进行情感识别)的轻量深度神经网络模型。据说该模型容易训练,可以自动对训练集进行分类,而且准确度高,即便是小型训练集也能获得很好的表现。
该论文提出的这个模型,遵循奥卡姆剃刀定律,并基于 AFEW 数据集进行训练。通过多个处理层(分别用于特征的提取、分析等)同时对音频和视频进行预处理和特征分析,最后结合二者输出情感识别结果。
AFEW 全称为「Acted Facial Expressions In The Wild」,是一个表情识别数据整理集,专为情感识别模型训练和 EmotiW 系列情感识别挑战赛提供测试数据。
所有数据都源自影视剧中剪辑的包含表情的视频片段,包括「愉快、惊讶、厌恶、愤怒、恐惧和悲伤」六种基本表情,及中性表情。
为了让模型更好的识别 AFEW 中的训练数据,五位研发人员还对模型进行了一些创新:
1)通过迁移学习和低维空间嵌入来减少特征维度,简化模型分析流程;
2)为每帧图像评分来进行抽样,降低训练集大小;
3)用一种简单的帧选择机制来对图像序列进行加权;
4)在预测阶段进行了不同形式的特征融合,即先对视频和音频分开处理,然后进行融合。
这一系列的创新,大大减少了表征数据集特征的参数数量,在简化模型训练过程的同时,提高了情感识别的精度。在 2018 年情感识别比赛 EmotiW(Emotion Recognition In The Wild Challenge)上,该模型的识别精度达到了 60.64%,排名第四。
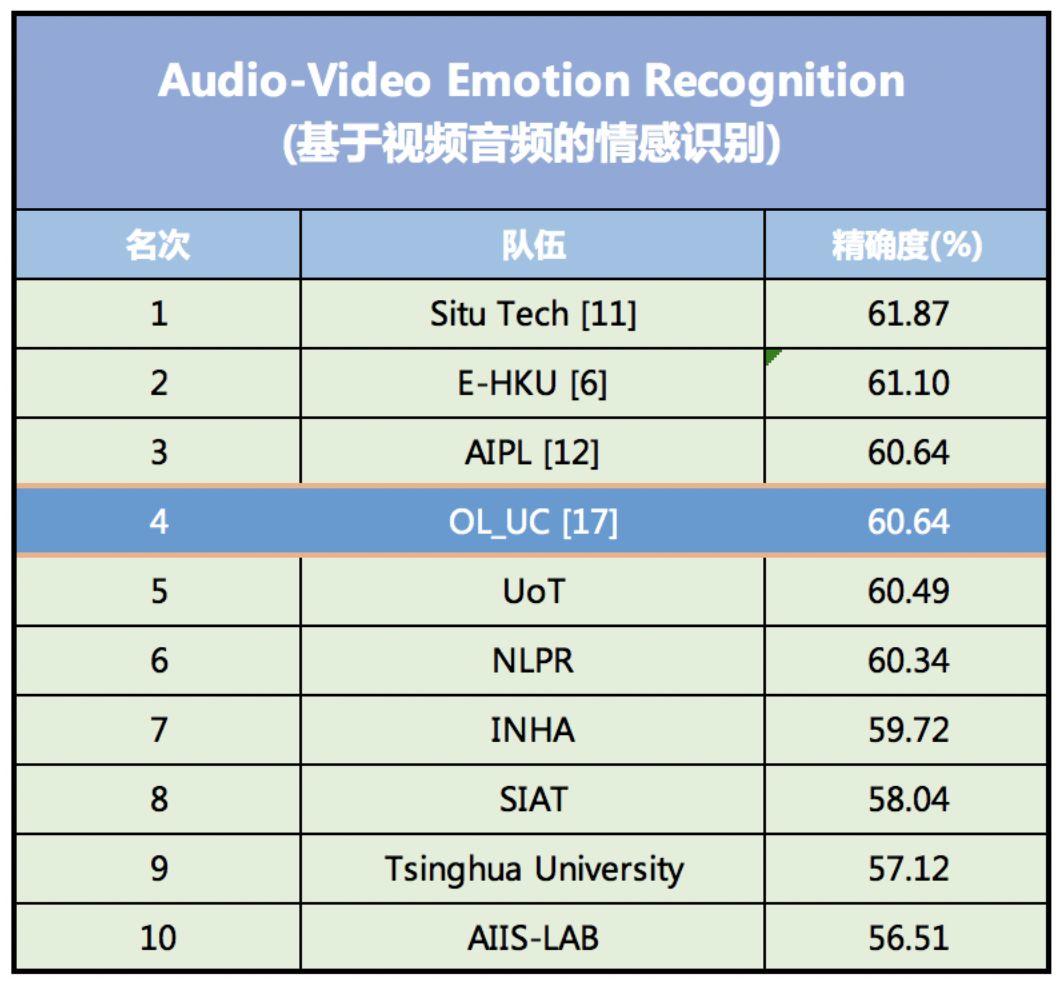
2018 EmotiW 视听情感识别模型精度排行榜,该模型位列第四
其中排名第一的情感识别模型是由国内一家 AI 金融科技公司 SEEK TRUTH (思图场景) 研发,准确率为 61.87% 。排名第二的模型由美国加州的一家 AI 初创公司 DeepAI 研发,准确率为 61.10% 。
该模型能自动为训练集添加标签
跟其他情感识别模型相比,该模型最大优势在于模型构建和训练难度很低。可以让计算机更容易感知人类的微表情,包括肢体语言等。
目前,大部分情感识别模型都是通过影视剧中角色表情来进行训练,一来获取成本低,二来表情丰富。

但这些数据在输入到训练集时,没有分类(即为每段视频添加情绪标签),因此在训练之前,需要手动或者通过其他方式来进行分类,操作难度较大,而且容易导致训练集失真。
而 Frédéric Jurie 等人开发的这个视听情感识别模型,可以通过深度神经网络自动对训练集中的表情进行分类,供模型使用。
这样一来,在降低模型训练难度的同时,还提高了识别精度。
该模型也证明,轻量级的神经网络模型可以取得很好的效果,也更容易训练,与当下愈发复杂的神经网络模型形成鲜明对比。
今后,他们将进一步研究如何更好地融合非视频格式的数据,以及识别分类更少,甚至没有分类的数据。
