Command Palette
Search for a command to run...
AI 论文周报丨阿里巴巴/厦门大学/浙江大学等最新成果,涵盖强化学习优化算法/GUI Agent/多模态上下文压缩……

随着大型语言模型规模不断扩大,如何高效稳定地进行强化学习训练成为一个关键挑战。为此,阿里巴巴集团 Qwen 团队提出了一种新颖的强化学习算法 Group Sequence Policy Optimization(GSPO)。
与传统基于 token 级别重要性比的方法不同,GSPO 基于序列概率定义重要性比,并在序列层面进行截断、奖励与优化,从而显著提升了训练的稳定性与效率。 GSPO 在 Mixture-of-Experts 架构下表现出色,不仅简化了强化学习基础设施的设计,还为最新 Qwen3 模型带来了显著性能提升。
论文链接:https://go.hyper.ai/FOrdj
最新 AI 论文:https://go.hyper.ai/hzChC
为了让更多用户了解学术界在人工智能领域的最新动态,HyperAI 超神经官网(hyper.ai)现已上线「最新论文」板块,每天都会更新 AI 前沿研究论文。以下是我们为大家推荐的 5 篇热门 AI 论文,一起来速览本周 AI 前沿成果吧 ⬇️
本周论文推荐
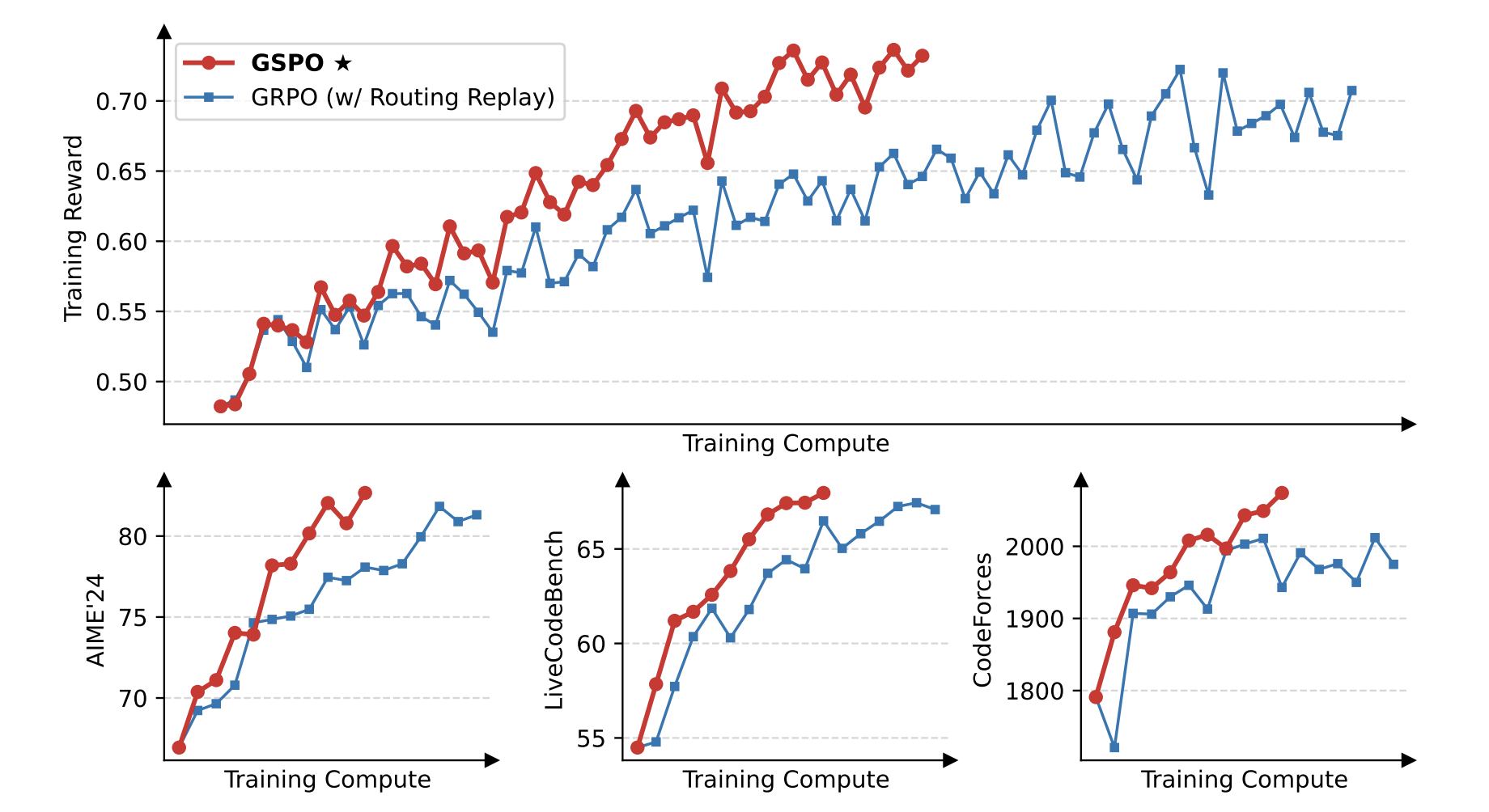
1 Group Sequence Policy Optimization
本文介绍了群体序列策略优化(Group Sequence Policy Optimization,GSPO),这是一种稳定、高效且性能优越的强化学习算法,用于训练大语言模型。与以往采用基于 token 的重要性比率的算法不同,GSPO 基于序列似然性定义重要性比率,并进行序列级别的裁剪、奖励和优化。
论文链接:https://go.hyper.ai/FOrdj
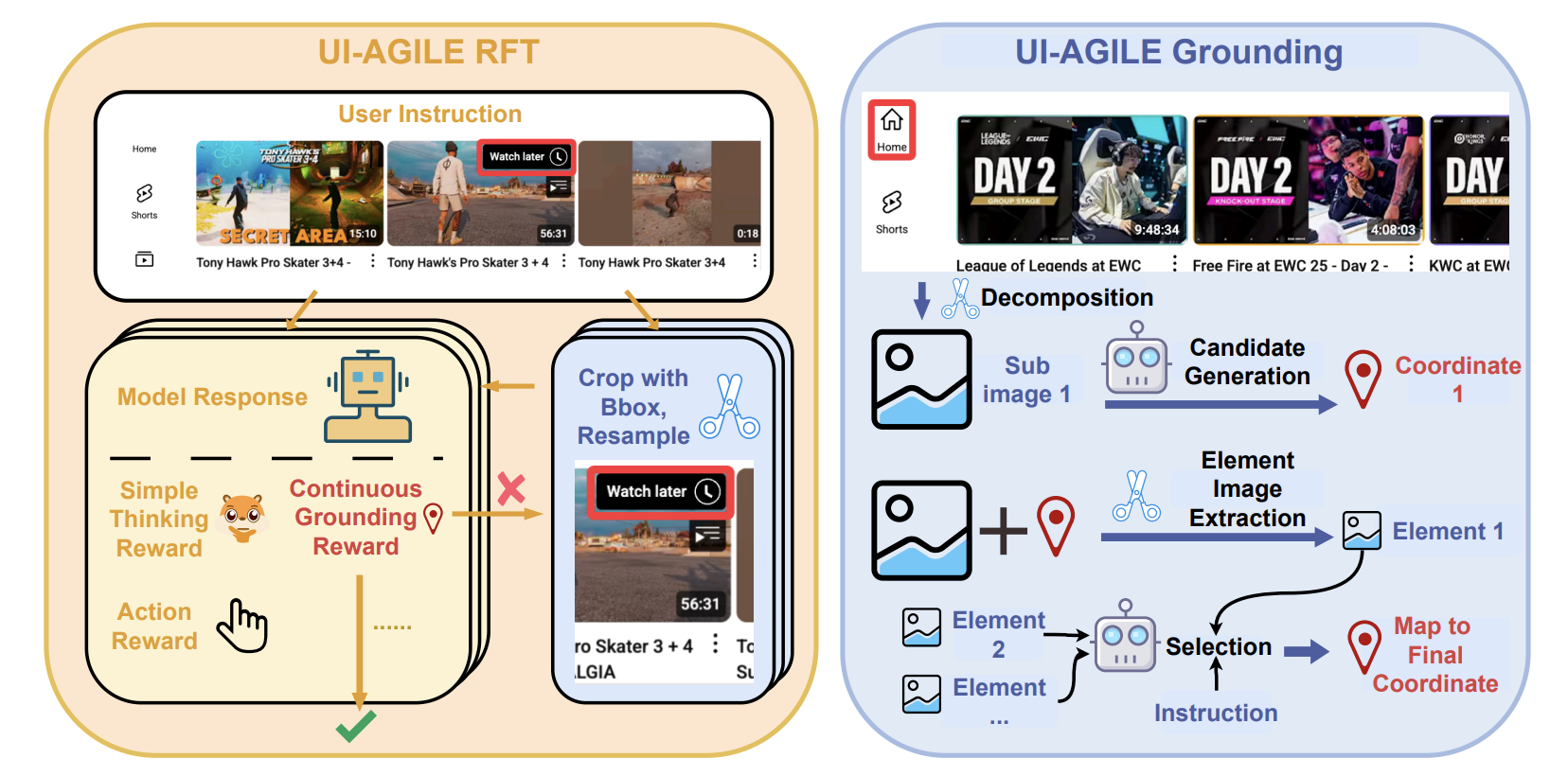
2 UI-AGILE: Advancing GUI Agents with Effective Reinforcement Learning and Precise Inference-Time Grounding
现有的 GUI Agent 训练与推理方法仍面临推理设计困境、奖励机制无效以及视觉噪声干扰等问题。本文提出了一种全新的方法——选择式分解对齐,该方法通过将图像划分为更小且可控的部分,显著提升了在高分辨率界面上的对齐精度。实验结果表明,UI-AGILE 在两个基准任务 ScreenSpot-Pro 和 ScreenSpot-v2 上均实现了当前最先进的性能。
论文链接:https://go.hyper.ai/SRpdE
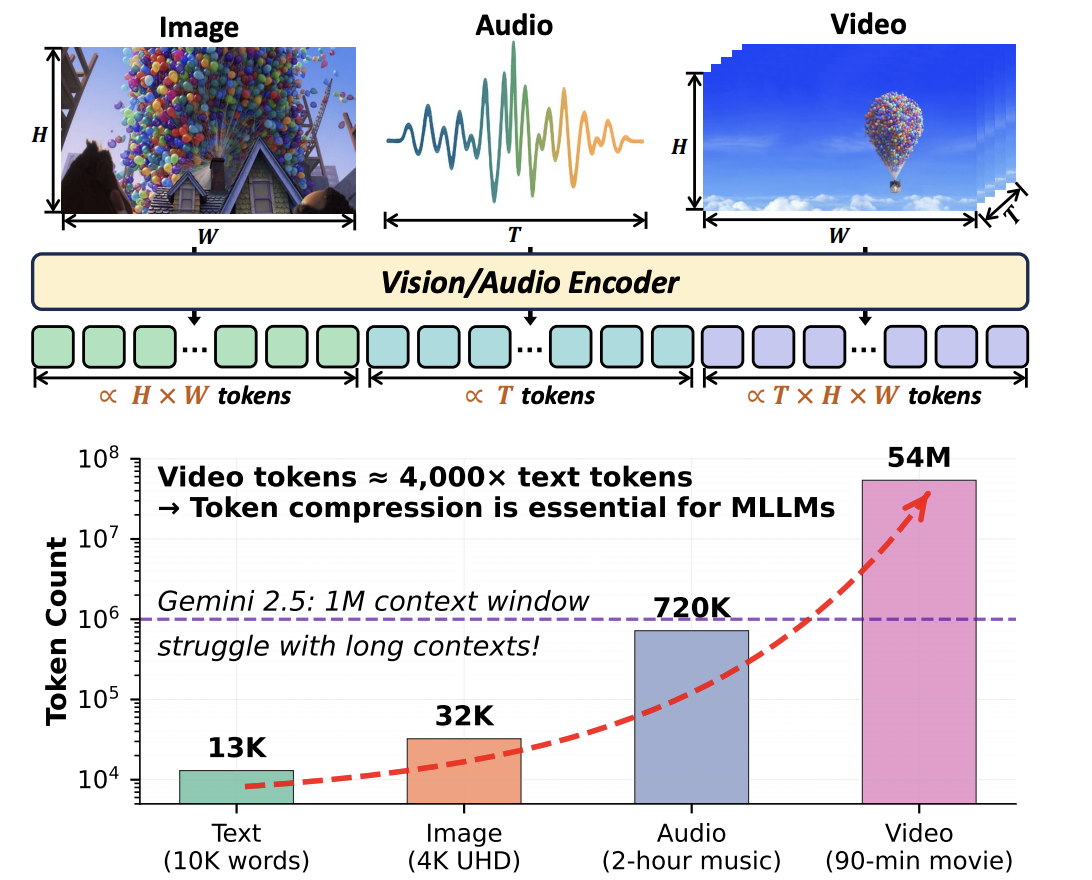
3 When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios
本文首次对快速发展的研究领域「多模态长上下文 token 压缩」进行了系统性的综述与归纳。鉴于不同模态具有各自独特的特征与冗余形式,研究人员将现有方法按其主要处理的数据类型进行分类,使得能够快速查阅并掌握适用于特定研究方向的方法:以图像为中心的压缩、以视频为中心的压缩、以音频为中心的压缩。
论文链接:https://go.hyper.ai/nOYw4
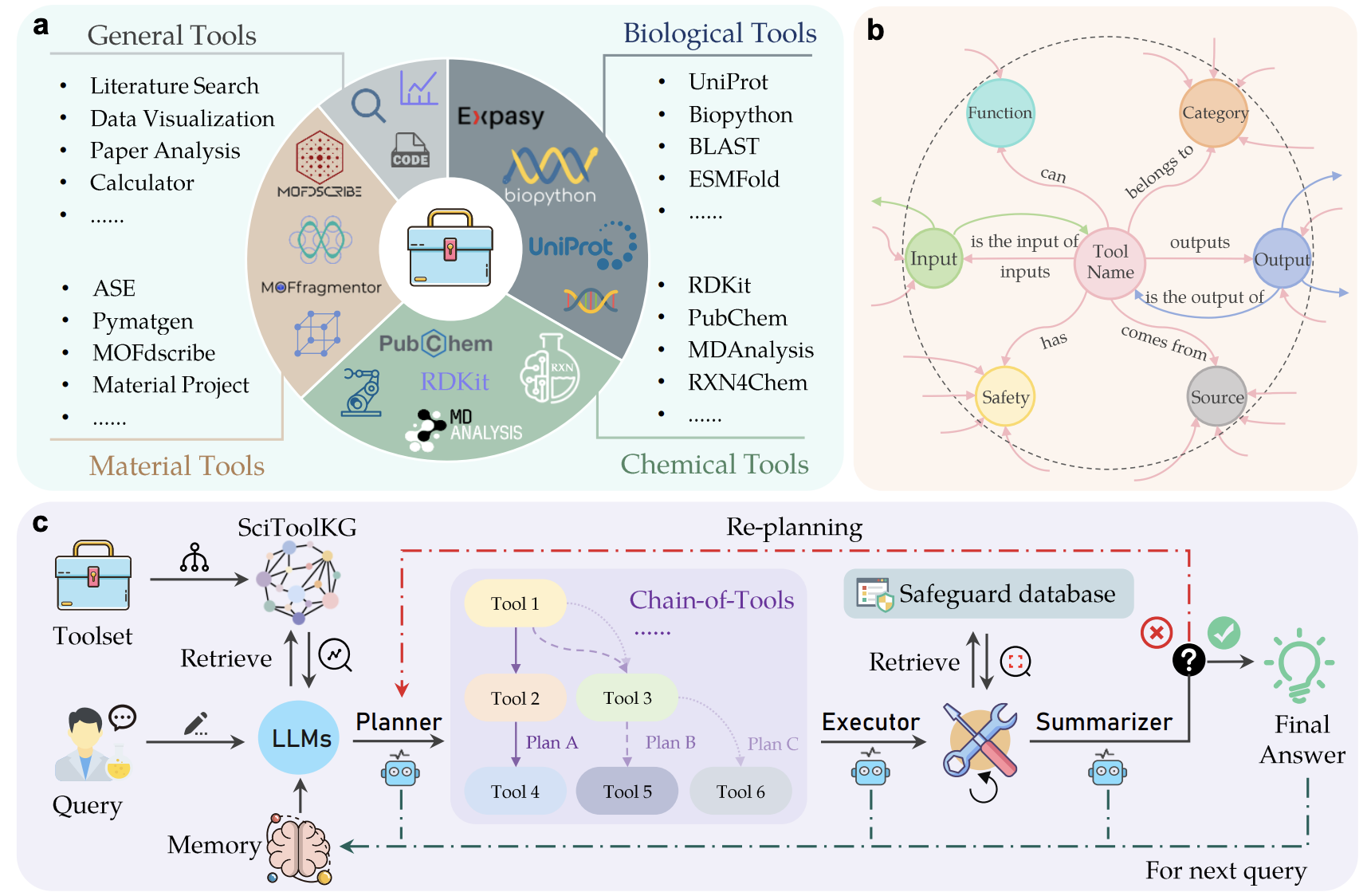
4 SciToolAgent: A Knowledge Graph-Driven Scientific Agent for Multi-Tool Integration
本文提出了 SciToolAgent,一个由 LLM 驱动的 Agent,能够自动化操作覆盖生物学、化学与材料科学的数百种科研工具。 SciToolAgent 的核心是一个科学工具知识图谱,借助基于图的检索增强生成(RAG)机制,实现智能的工具选择与执行。该系统还集成了全面的安全检查模块,以保障工具使用的责任性与伦理性。
论文链接:https://go.hyper.ai/IOiRk
5 SmallThinker: A Family of Efficient Large Language Models Natively Trained for Local Deployment
本文提出 SmallThinker,一组原生为本地设备设计(而非从云模型压缩而来)的 LLMs,专为应对本地设备的独特限制而打造:计算能力弱、内存有限、存储速度慢。 SmallThinker 从架构层面重新设计,以在受限环境中高效运行。其核心是一种「面向部署」的创新架构,将系统限制转化为设计原则。
论文链接:https://go.hyper.ai/tSwpG
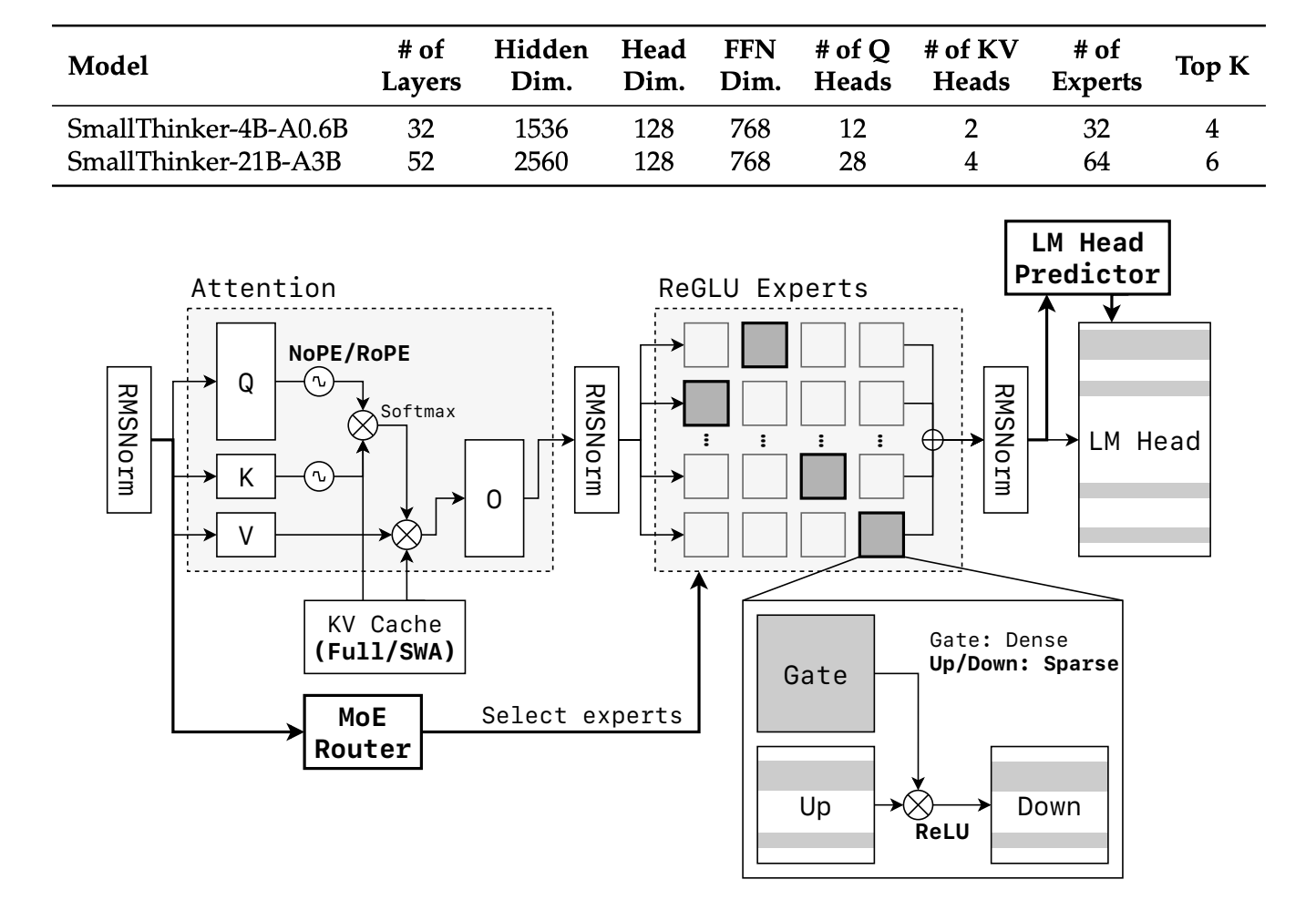
以上就是本周论文推荐的全部内容,更多 AI 前沿研究论文,详见 hyper.ai 官网「最新论文」板块。
同时也欢迎研究团队向我们投稿高质量成果及论文,有意向者可添加神经星星微信(微信号:Hyperai01)。
下周再见!








