Command Palette
Search for a command to run...
斯坦福/苹果等 23 所机构发布 DCLM 基准测试,高质量数据集能否撼动 Scaling Laws?基础模型与 Llama3 8B 表现相当

人们对 AI 模型的关注高热不下,关于 Scaling Laws 的争论也愈发热烈。
OpenAI 于 2020 年在论文「Scaling Laws for Neural Language Models」中首次提出 Scaling Laws,它被看作是大语言模型的摩尔定律。其释义可简要总结为:随着模型大小、数据集大小、(用于训练的)计算浮点数的增加,模型的性能会提高。
在 Scaling Laws 的影响下,不少追随者始终认为「大」依然是提高模型性能的第一性原理。尤其是「财大气粗」的大厂,更加依赖于大型、多样化的语料数据集。
对此,清华大学计算机系博士秦禹嘉指出,「LLaMA 3 告诉大家一个悲观的现实:模型架构不用动,把数据量从 2T 加到 15T 就可以暴力出奇迹。这一方面告诉大家基座模型长期来看就是大厂的机会;另一方面,考虑到 Scaling Laws 的边际效应,我们想继续看到下一代模型能够有 GPT3 到 GPT4 的提升,很可能需要再洗出至少 10 个数量级的数据(例如 150T)」。

针对语言模型训练所需数据量持续提升,以及数据质量等问题,华盛顿大学、斯坦福大学、苹果等 23 所机构联手,提出了一个实验测试平台 DataComp for Language Models (DCLM),其核心是来自 Common Crawl 的 240T 新候选词库,通过固定训练代码,鼓励研究人员提出新的训练集来进行创新,对于语言模型的训练集改进具有重大意义。
相关研究已经以「DataComp-LM: In search of the next generation of training sets for language models」为题,发表于学术平台 http://arXiv.org 上。
研究亮点
* DCLM 基准测试的参与者,可以在 412M 到 7B 参数的模型尺度上试验数据管理策略
* 基于模型的过滤是构建高质量训练集的关键,生成的数据集 DCLM-BASELINE 支持使用 2.6T 训练 tokens 在 MMLU 上从头开始训练 7B 参数语言模型,达到 64% 的 5-shot 准确性
* DCLM 的基础模型在 MMLU 上与 Mistral-7B-v0.3 和 Llama3 8B 表现相当

论文地址:
https://arxiv.org/pdf/2406.11794v3
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
DCLM 基准:从 400M 到 7B 多尺度设计,实现不同计算规模需求
DCLM 是一个用于改进语言模型的数据集实验平台,是语言模型训练数据管理的第一个基准。
如下图所示,DCLM 的工作流主要由 4 个步骤构成:选择计算规模 (Select a scale) 、建立数据集 (Build a dataset) 、训练模型 (Train a model) 、基于 53 个下游任务上进行模型评估 (Evaluate) 。
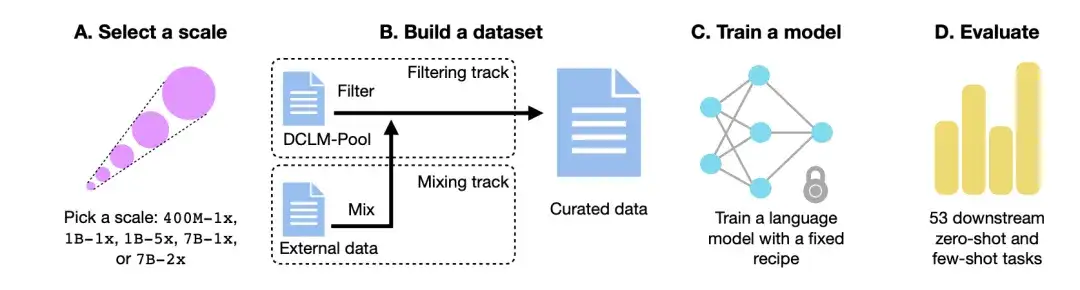
选择计算规模
首先,在计算规模方面,研究人员创建了跨越 3 个数量级计算规模的 5 个不同竞赛级别。每个级别(即 400M-1x 、 1B-1x 、 1B-5x 、 7B-1x 和 7B-2x)指定了模型参数量(例如 7B)和一个 Chinchilla 乘数(例如 1x)。每个规模的训练 tokens 数是参数数量的 20 倍乘以 Chinchilla 乘数。
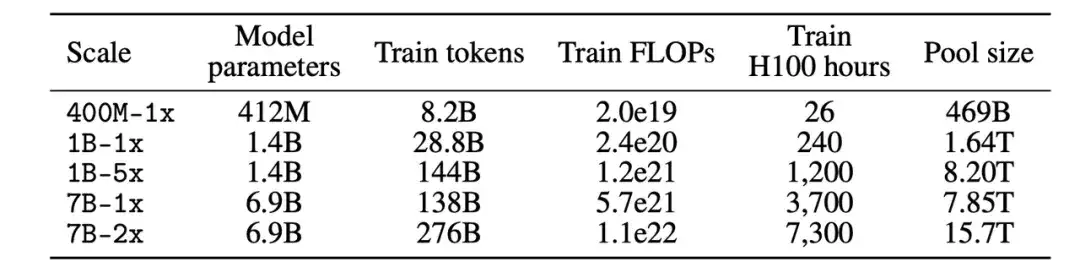
建立数据集
其次,确定参数规模后,在建立数据集的过程中,参与者可以通过过滤 (Filter) 或混合 (Mix) 数据来创建数据集。
在过滤轨道 (Filtering track) 中,研究人员从未经过滤的爬虫网站 Common Crawl 上提取了 240T tokens 的标准化语料库,构建了 DCLM-Pool,并根据计算规模划分了 5 个数据池。参与者提出算法,并从数据池中选择训练数据。
在混合轨道 (Mix track) 中,参与者可以从多个来源自由组合数据。例如,合成来自 DCLM-Pool 、自定义爬取的数据、 Stack Overflow 和维基百科的数据文档。
训练模型
OpenLM 是一个以 PyTorch 为基础的代码库,专注于 FSDP 模块进行分布式训练。为了排除数据集干扰的影响,研究人员在每个数据规模上使用固定的方法进行模型训练。
基于之前对模型架构和训练的消融研究,研究人员采用像 GPT-2 、 Llama 这样的仅解码器的 Transformer 架构,最终在 OpenLM 中进行模型训练。
模型评估
最后,研究人员通过 LLM-Foundry 工作流程 ,以 53 个适合基础模型评估的下游任务为标准,进行了模型评估。这些下游任务包含了问答、开放式生成的形式,涵盖了编码、教科书知识和常识推理等各种领域。
为了评估数据整理算法,研究人员主要关注 3 个性能指标:MMLU 5-shot 准确率、 CORE 中心准确率、 EXTENDED 中心准确率。
数据集:使用 DCLM 构建高质量的训练数据集
DCLM 是如何构建高质量数据集 DCLM-BASELINE,并量化数据管理方法的效果的呢?
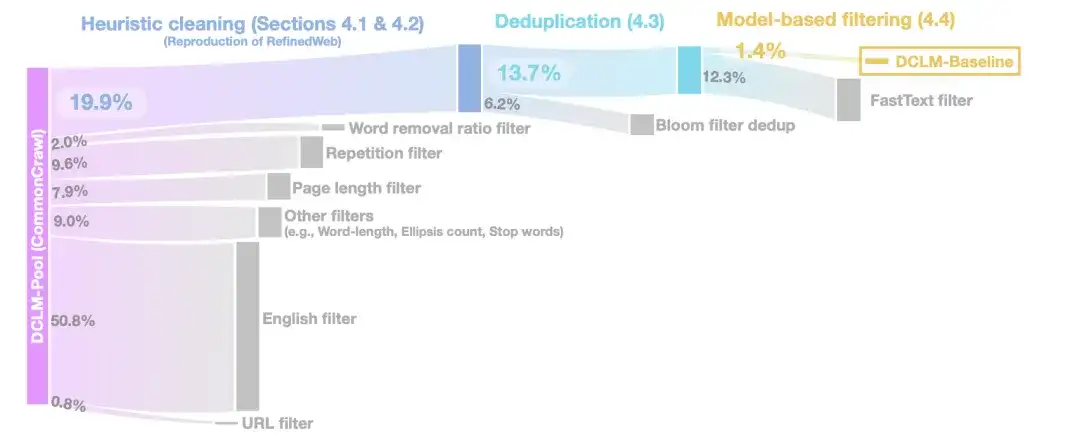
在启发式数据清洗 (Heuristic cleaning ) 阶段,研究人员使用 RefinedWeb 的方法进行数据清洗,具体操作包括移除 URL (URL filter) 、英文过滤 (English filter) 、页面长度过滤 (Page length filter) 、重复内容过滤 (Repetition filter) 等。
在重复数据删除 (Deduplication) 阶段,研究人员使用 Bloom 过滤器对提取到的文本数据进行重复数据的删除,同时还发现,修改后的 Bloom 过滤器更容易扩展到 10TB 的数据集。
为进一步提高数据的质量,在基于模型的过滤 (Model-based filtering) 阶段,研究人员比较了 7 种基于模型的过滤方式,包括使用 PageRank 得分进行过滤、语义去重(SemDedup)、 fastText 二元分类器等,发现基于 fastText 的过滤优于所有其他方法。
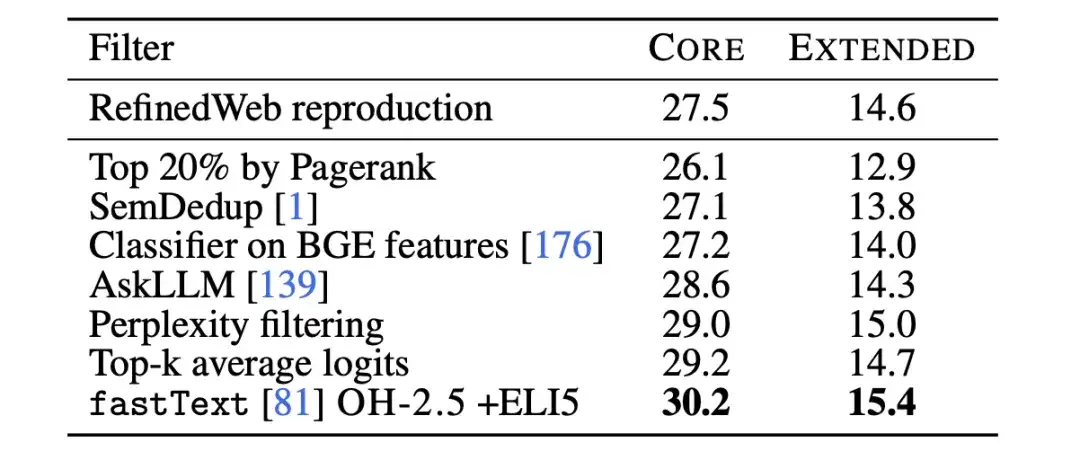
随后,研究人员利用文本分类消融实验 (Text classifier ablations),进一步研究了基于 fastText 进行数据过滤的局限性。研究人员训练了多个不同的变体,探索了参考数据、特征空间和过滤阈值的不同选择,如下图所示。对于参考数据,研究人员选择了常用的 Wikipedia 、 OpenWebText2 、 RedPajama-books,这些都是 GPT-3 使用的参考数据。
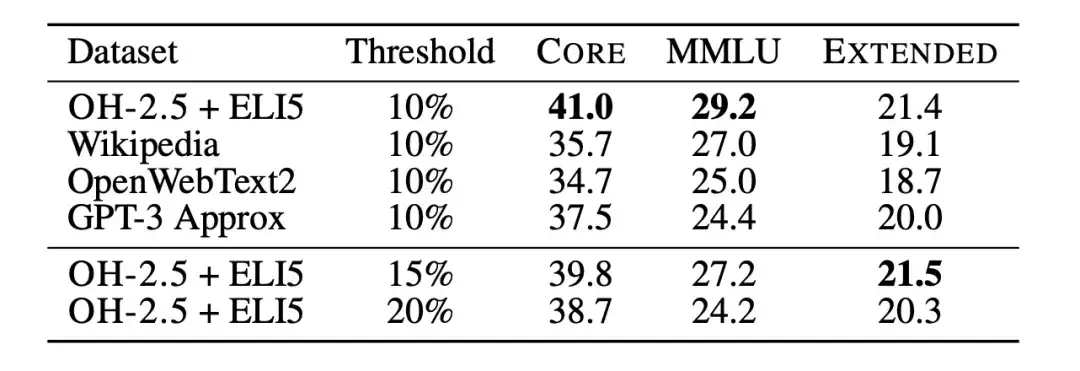
同时,研究人员还创新性地使用了指令格式的数据,从 OpenHermes 2.5 (OH-2.5) 和 r/ExplainLikeImFive (ELI5) subreddit 的高分帖子中提取示例。结果显示,OH-2.5 + ELI5 的方法相较常用参考数据,在 CORE 上提升了 3.5% 。
此外,研究人员发现,严格的阈值 (即 Threshold 为 10%) 能够获得更好的性能。所以,研究人员使用 fastText OH-2.5 + ELI5 分类器得分来进行数据过滤,保留前 10% 的文档便得到了 DCLM-BASELINE 。
研究结果:生成高质量数据集,基于模型的过滤是关键
首先,研究人员分析了未经评估的预训练数据污染,是否会影响研究结果。
MMLU 作为衡量大语言模型性能的基准测试,旨在更全面考察模型对不同语言的理解能力。因此,研究人员将 MMLU 作为评估集,并从 MMLU 中检测、删除 DCLM-BASELINE 中存在的问题。随后,研究人员基于 DCLM-BASELINE 训练了一个 7B-2x 模型,而不使用检测到的 MMLU 重叠。
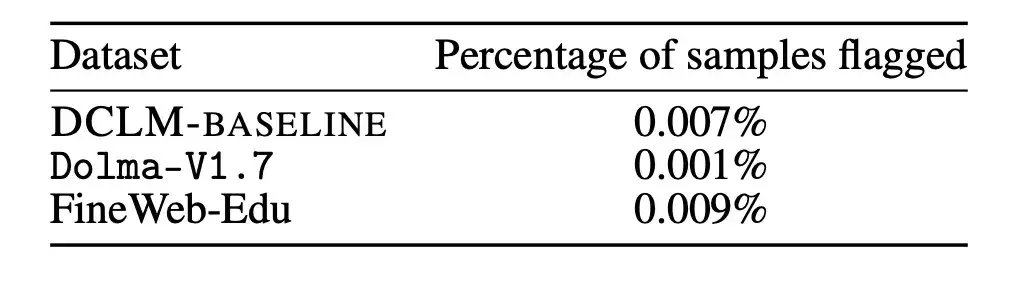
结果如下图显示,污染样品的去除,并不会导致模型的性能下降。由此可见,DCLM-BASELINE 在 MMLU 测试基准上的性能提升,并不是因为其数据集中包含 MMLU 中的数据。

除此之外,研究人员还在 Dolma-V1.7 和 FineWeb-Edu 上应用了上述去除策略,以测量 DCLM-BASELINE 与这些数据集之间的污染差异。结果发现 DLCM-BASELINE 的污染统计数据,和其他高性能数据集大致相似。
其次,研究人员还将训练的新模型,与 7B-8B 参数规模下的其他模型进行了比较。结果显示,基于 DCLM-BASELINE 数据集生成的模型优于在开源数据集上训练的模型,并且比在闭源数据集上训练的模型具有竞争力。
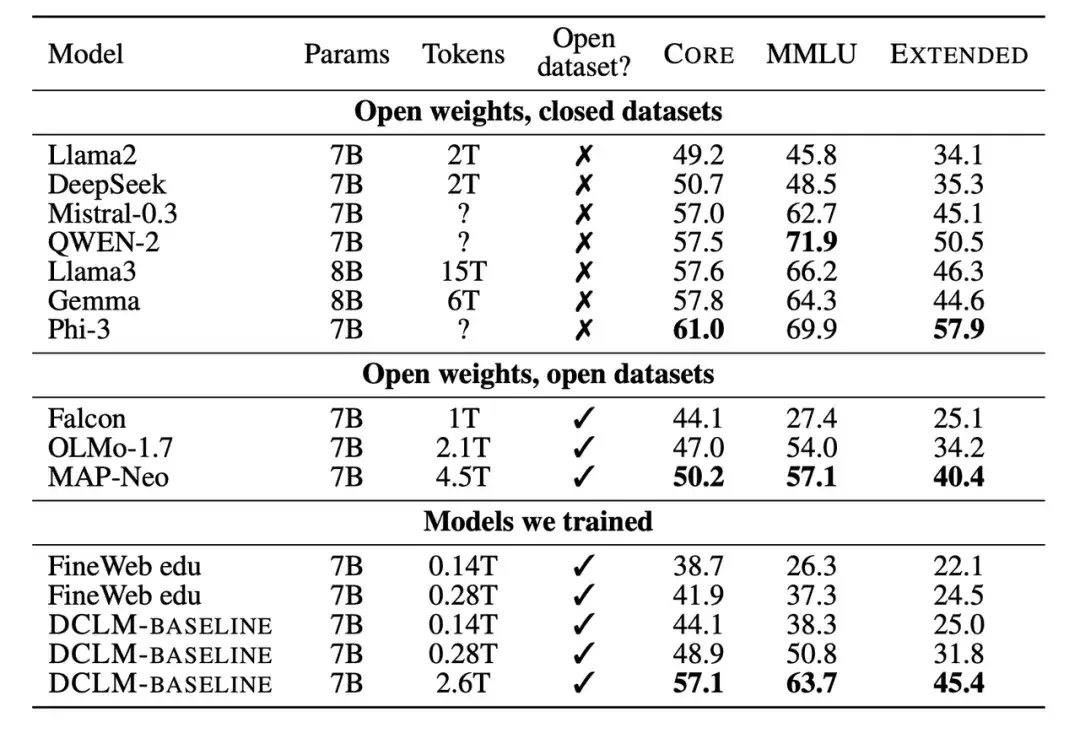
大量的实验结果表明,基于模型的过滤是组成高质量数据集的关键,并且数据集设计对语言模型的训练十分重要。生成的数据集 DCLM-BASELINE 支持使用 2.6T 训练 tokens 在 MMLU 上从头开始训练 7B 参数语言模型,达到 64% 的 5-shot 准确性。
与之前最先进的开放数据语言模型 MAP-Neo 相比,生成的数据集 DCLM-BASELINE 在 MMLU 上提高了 6.6 %,同时训练所需的计算量减少了 40% 。
DCLM 的基础模型在 MMLU 上与 Mistral-7B-v0.3 和 Llama3 8B 相当 (63% 和 66%),并且在 53 个自然语言理解任务上表现相似,但训练所需的计算量比 Llama3 8B 少 6.6 倍。
Scaling Laws 未来走向莫衷一是,寻找用于语言模型的下一代训练集
总结来看,DCLM 的核心是鼓励研究人员,通过基于模型的过滤来组建高质量训练集,进而提升模型性能。而这也在「以大为美」的模型训练趋势下,提供了全新的解题思路。
正如清华大学计算机系博士秦禹嘉所言,「是时候把数据 scale down 了」。通过分析总结多篇论文,他发现「清洗后的干净数据+更小的模型能够更加逼近脏数据+大模型的效果」。
7 月初,比尔·盖茨在最新一期 Next Big Idea 播客中提到了 AI 技术范式变革的话题,他认为 Scaling Laws 快要走到尽头了。 AI 对于计算机交互的革命还没来到,但它的真正进步在于实现更接近人类的元认知能力,而非仅扩大模型规模。

在此之前,多位国内行业大咖也曾在 2024 北京智源大会上,就 Scaling Laws 未来走向的问题,展开了深度探讨。
零一万物 CEO 李开复表示,Scaling Law 已被验证有效并且尚未达到顶峰,但利用缩放定律不能盲目堆 GPU ,仅仅依靠堆砌更多算力提升模型效果,只会导致那些 GPU 足够多的公司或国家才能胜出。
清华大学智能产业研究院的院长张亚勤则表示,Scaling Law 的实现主要得益于对海量数据的利用以及算力的显著提升。未来 5 年内仍是产业发展的主要方向。

月之暗面 CEO 杨植麟认为,Scaling Law 没有本质问题,只要有更多算力、数据,模型参数变大,模型就能持续产生更多智能。他认为 Scaling Law 会持续演进,只是在这个过程中 Scaling Law 的方法可能会发生很大变化。
百川智能 CEO 王小川认为,在 Scaling Law 之外,一定要寻找算力、算法、数据等范式上的新转化,而不只是简单变成知识压缩,走出这个体系才有机会走向 AGI 。
大模型的成功很大程度上要归因于 Scaling Laws 的存在,它在一定程度上为模型开发、资源分配和选择合适的训练数据提供了宝贵的指导。对于「Scaling Laws 的尽头是什么」我们现在或许还无从得知,但 DCLM 基准测试为提升模型性能提供了一种新的思考范式和可能。
参考资料:
https://arxiv.org/pdf/2406.11794v3
https://arxiv.org/abs/2001.08361








