Command Palette
Search for a command to run...
登天文学顶刊 MNRAS!中科院上海天文台利用 AI 发现 107 例中性碳吸收线,探测精度达 99.8%

人们仰望星空,那些遥远的星光其实已经穿越了数十亿年的时空,诉说着古老的故事。而中性碳吸收线,作为早期星系内冷气体云块的关键探针,就像是宇宙历史的见证者,它们的存在为人们窥探星际奥秘提供了一扇窗口。
在恒星演化的过程中,恒星爆发释放出的物质中含有丰富的化学元素,这些元素在恒星内部经过核融合反应,并随着爆发扩散到周围空间。其中,包括碳、氧、硅等元素的星际尘埃也随着爆发的扩散在星际介质中富集,不但为新恒星和行星系统的形成提供了重要的物质基础,也在星际介质的冷却和凝聚过程中起着关键作用。
研究表明,在不同的星际介质中,中性原子碳 (C Ⅰ) 在波长为 1560 和 1656 处的吸收线可以用来探测冷气体的丰度,进而揭示分子云、星际尘埃以及恒星的形成。然而,目前包含 C I 吸收线的类星体光谱样本量太小,使其无法成为理解早期宇宙整体化学丰度演化和星系演化的有力工具。
近期,中国科学院上海天文台研究员葛健带领的国际团队,通过深度学习方法,在斯隆巡天三期释放的数据中搜寻中性碳吸收线(C Ⅰ 吸收线),揭开了宇宙早期星系内冷气体云块成分的神秘面纱,发现了 107 例宇宙早期中性碳吸收线。这一发现不仅刷新了人们对宇宙早期星系演化的认知,更是证明了人工智能在天文研究中的巨大潜力。相关研究成果已经发表于「皇家天文学会月报」(MNRAS)。
研究亮点:
- 该研究使用修改后的深度学习算法,以 Mg II 吸收线为标志物,搜索 C I 吸收线的结果
- 该研究发现了 107 例宇宙早期中性碳吸收线,获得的样本数是此前获得的最大样本数的近两倍之多
- 该研究能够探测到更多比以前更微弱的信号,为未来宇宙和星系早期演化研究提供全新的研究手段

论文地址:
https://doi.org/10.1093/mnras/stae799
数据集:以 Mg II 吸收线为标志物,生成 500 万条随机样本
由于 C Ⅰ 吸收线很难被检测到,本研究缩小了搜索范围,只针对已知具有 Mg Ⅱ 吸收线的 QSO (Quasi-Stellar Objects,类星体) 进行研究,将 Mg Ⅱ 吸收线作为发现其他原子物种吸收的路标。此外,本研究选择对 1.3<Z(abs)<2.7 的 Mg Ⅱ 吸收线进行搜索,确保了 C I 吸收线位于 SDSS-III BOSS 光谱仪的可观测波长范围内,从而有助于将总搜索目标数量减少到约 1.4 万个。
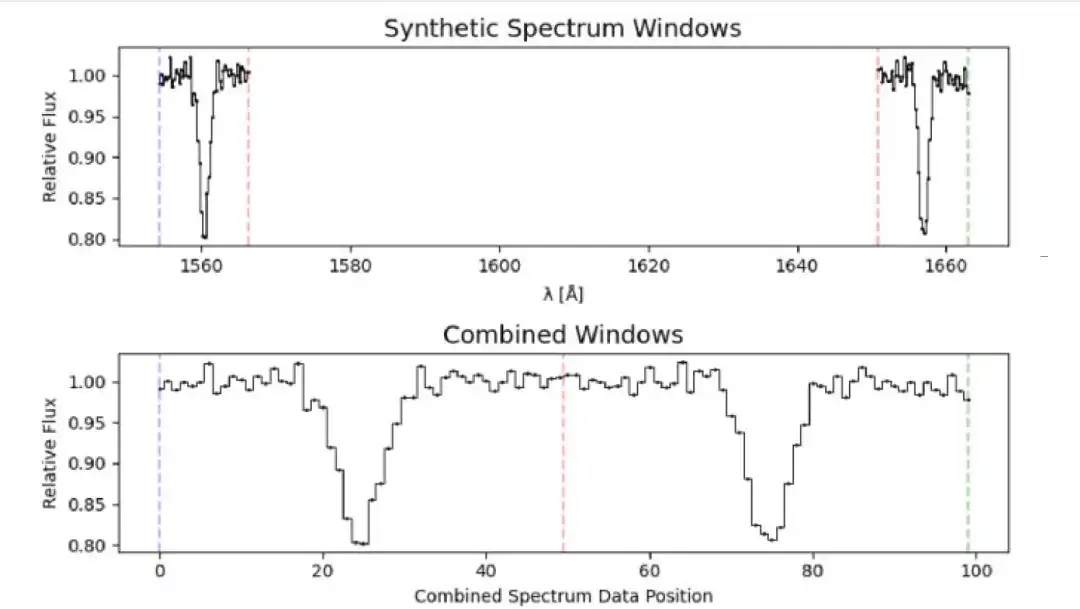
考虑到两条 C Ⅰ 吸收线通常非常微弱和罕见,它们在 1560 和 1656 Åare 的静止波长内彼此相隔很远,加大了深度神经网络的搜索难度。因此,本研究创新性的提出了「假双线法」(fake doublet method),可在两条 C Ⅰ 吸收线周围的光谱区域内分别提取一小部分,形成一个假型 C Ⅰ 双重吸收线。
然后,由两个 12Å 的窗口连接在一起形成一个 100 元素长的一维通量数组,便能够提供对局部光谱特性和信噪的清晰视图,同时不包括吸收线之间的整个波长范围,从而减小了样本的大小和计算要求。此后,深度学习程序即可很容易的在其中搜索 Mg II 和 Ca II 双重吸收线。通过对神经网络进行适当训练,即可在类星体光谱中搜索不饱和的 C I 双重吸收线。
由于 Mg II 吸收线中的吸收红移值存在不确定性,实际搜索中使用的光谱可能有高达约 ±0.25 Å 的波长偏差。为此,本研究在每个生成样本中的 C I 吸收线上都应用了相同范围的随机偏移,总共生成了 500 万条包含相同数量的阳性和阴性样本。其中,阳性样品含有两条 CⅠ 吸收线,在方差参数是从范围为 0.05-0.8 Å 的均匀分布中随机采样;阴性样品则不包含 C Ⅰ 吸收线,在方差参数是从范围为 0.2-1.0 Å 的均匀分布中随机采样。
为了模拟训练数据集中的噪声,本研究从高斯分布中随机抽取样本,通过从三角分布中采样来为每个光谱分配信噪比 (SNR) 。这一过程导致训练集的平均信噪比约为 8.0,与 SDSS DR12 中 10 万个 QSO 光谱的平均信噪比 8.4 非常接近。同时,本研究故意使合成数据集的信噪比偏向较低值,以增强模型检测微弱 C I 吸收线的能力。
模型构建:模型准确率高达 99.8%,证实卷积神经网络非常有效
该研究的卷积神经网络模型旨在识别每个输入光谱中的两条 C I 吸收线。模型由多个关键组件组成,包括单个卷积层 (Single convolutional layer) 、归一化层 (Batch normalization) 、打平层 (Flatten layer) 和 3 个密集层 (Dense layer) 。
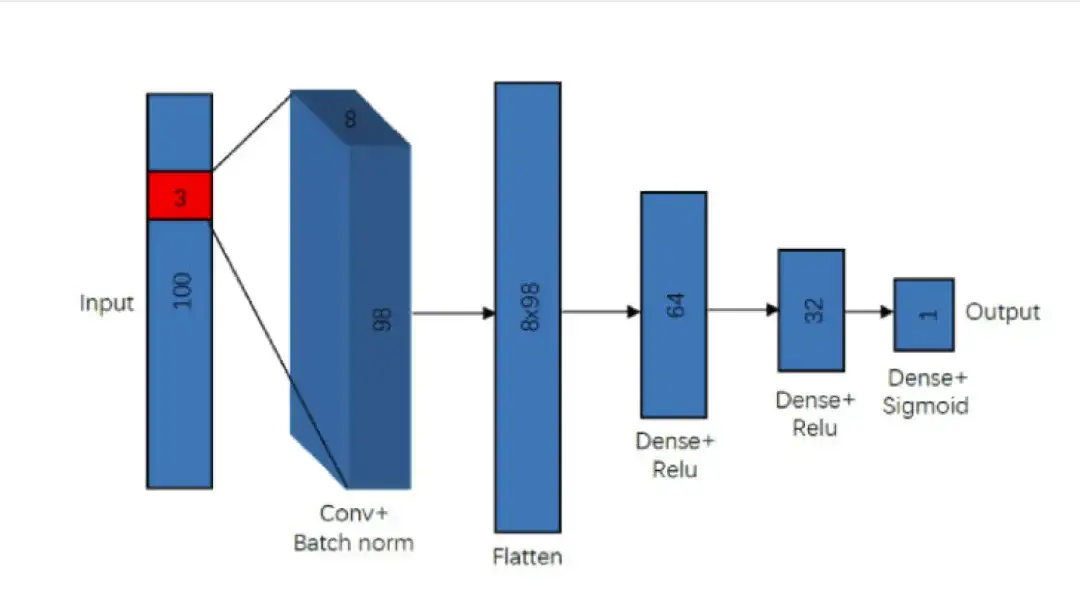
在输入模型之前,该研究对每个频谱进行了噪声归一化,有效消除了模型噪声的影响。在噪声归一化后,还研究还将结果除以 30 并加上 0.5,使通量值保持在 0 到 1 的范围内,这确保了模型第一层(卷积)的数据被归一化,并部分地帮助了第二层 (Batch normalization) 的规范一致性。
卷积层 (Convolutional layer) 主要用于检测谱线及其位置。经过大量的实验和测试,研究发现单个卷积层足以满足需求,其中包含 8 个滤波器和 3×3 的内核大小。
在卷积之后,样本会通过归一化层 (Batch normalization) 以确保数据位于后续密集层(Dense layer)的正确值范围内。 Flatten 层则主要用来将输入「压平」,即把卷积层输出的多维特征拉为一维向量。
模型前两个密集层均使用了线性激活函数 (ReLU),并且都分配有 dropout 层。同时,输出层也是只有一个神经元的密集层,使用了 Sigmoid 激活函数。这种相对简单的设计提供了出色的检测精度,同时训练和搜索速度也都非常快。
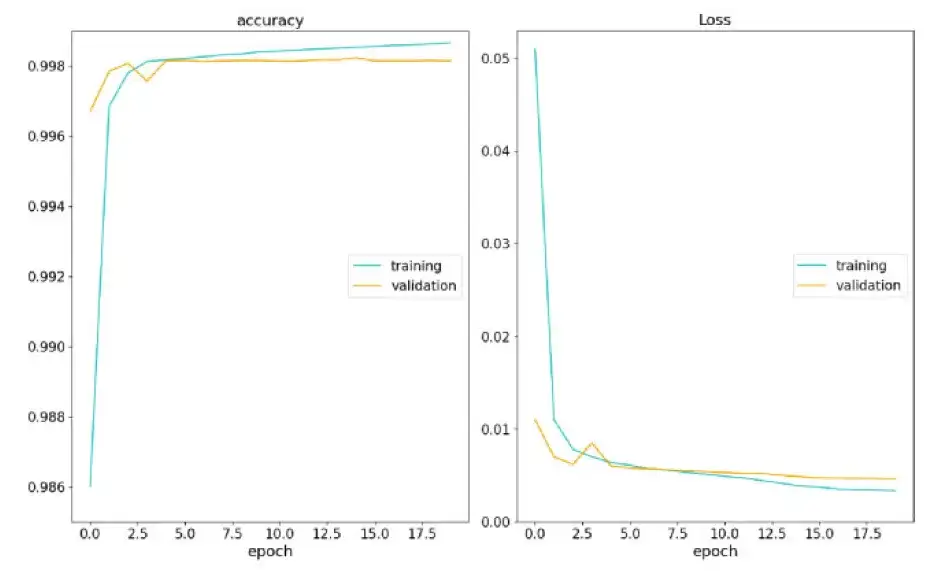
此后,该模型共进行了 20 次迭代。在每次迭代中,所有训练样本都以 32 个一组的形式通过模型。总体而言,该模型准确率为 99.8% 。这种高准确性证明了卷积神经网络在检测光谱中的 C I 吸收线方面非常有效。
研究结果:精选出 107 条 C I 吸收线,CNN 探寻微弱信号的潜力无限
本研究中最终利用训练好的 CNN 搜索了来自 Mg II 目录中的 14,509 个类星体光谱数据集,重点关注红移 (redshifts) 在 1.3 < Z(abs) < 2.7 之间的类星体。
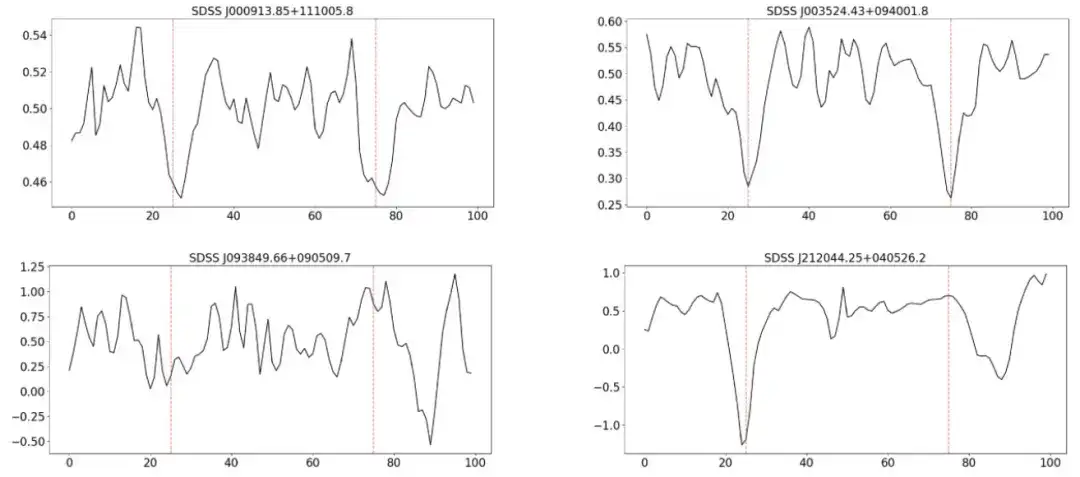
检测和精选吸收线的步骤如下:
初始 CNN 识别
CNN 作为二值分类器部署,本研究评估了 14,509 个类星体光谱,每个光谱的评分在 0 到 1 之间。得分高于 0.5 阈值的光谱被归类为 C I 吸收线候选体,该方法共选出了 2,056 个候选样本进行进一步分析。
人工检查和线验证
研究通过人工检查进一步验证 C I 吸收线,重点关注其精确波长和与相邻吸收特征的区别。当一条 C I 线的位置合适时,但如果它的对偶体有显著的偏差,那么这些也会被排除在外。最终候选样本减少到了 400 。
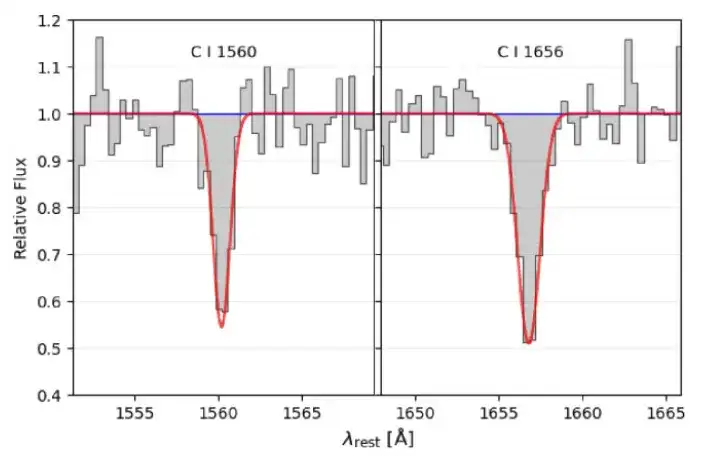
详细的谱线拟合和信噪比计算
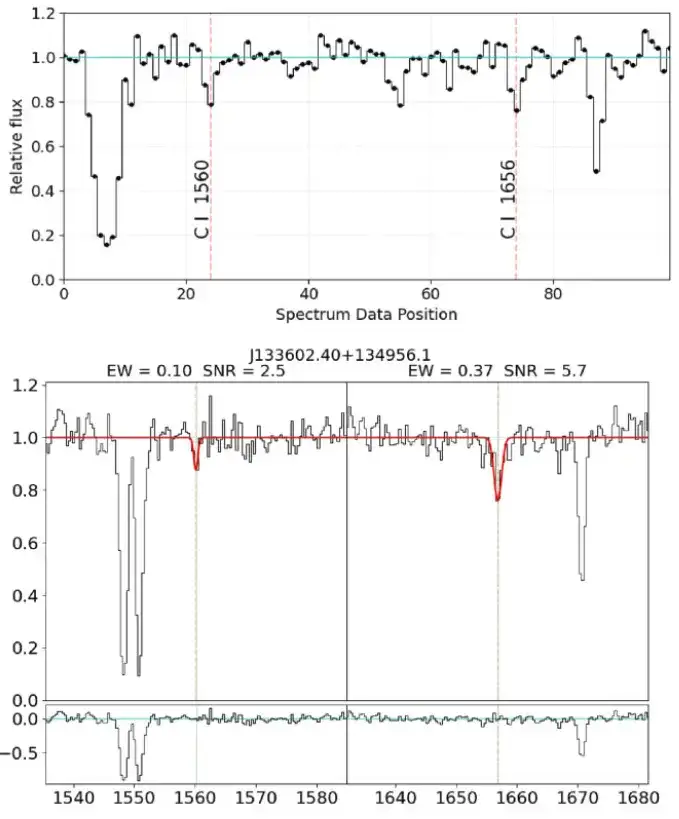
研究使用一维高斯模型拟合候选的 C I 吸收线。这里基于两个关键标准:第一,虽然 λ1656 的静态等效宽度 W 应该大于 λ1560,但只要 λ1560 保持在 3 σ 置信区间内,允许 W(λ1560) 超过 W(λ1656);其次,λ1560 和 λ1656 的最小可接受信噪比分别为 2.5 和 3 。根据这些标准,候选样本的范围缩小到 142 。
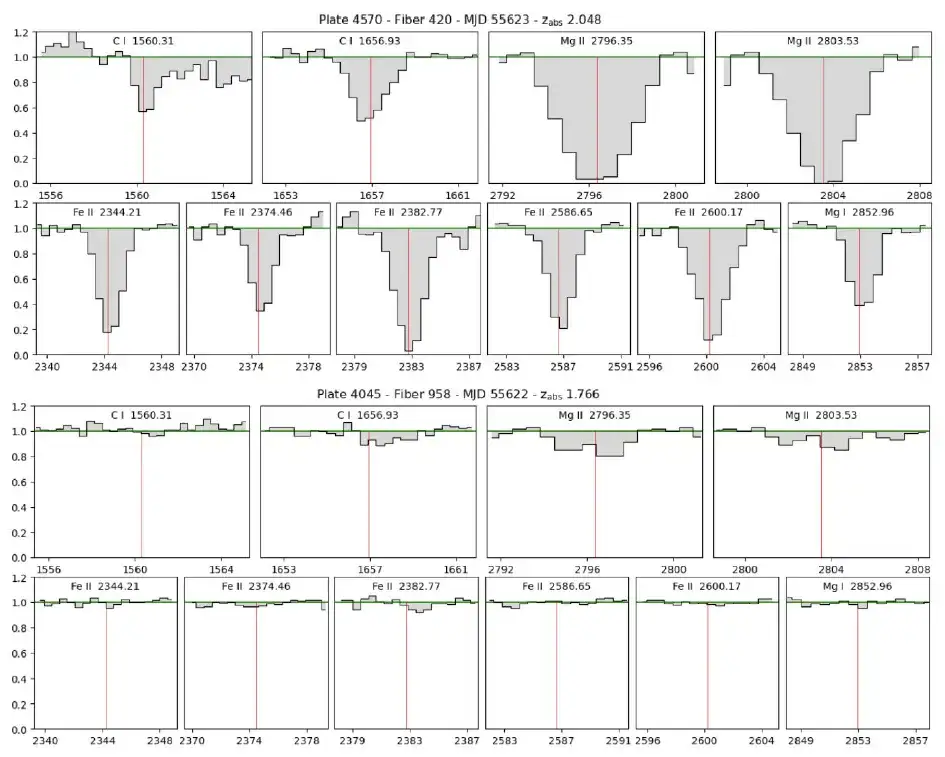
目视检查和光谱线交叉参照
每个剩余的候选材料都进行了最后的目视检查,尤其检查了额外的光谱线,当这些额外的光谱线与 C I 线的相对强度相匹配时。研究排除了 C I 线突出,但所有其他光谱线缺失的情况下的候选样本,最终的候选样本精简得出 107 种碳吸收剂检测的最终目录,下表展示了部分 C I 吸收线。
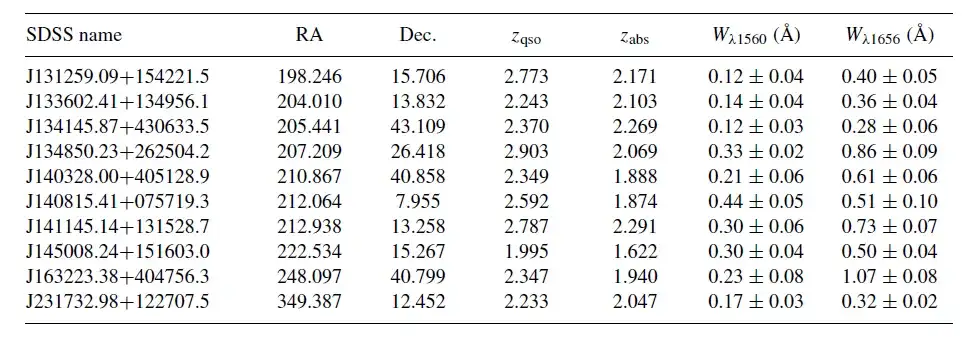
本研究列出了最终目录中的 10 个碳吸收器,其详细信息包括目标名称、坐标、红移和静态等效宽度。结果显示,最强的碳吸收体 W(λ1656) 为 1.92 Å,而最弱的碳吸收体的静态等效宽度为 0.1 Å。同时,CNN 训练方法使得整体 C I 吸收线均取得了较低等效宽度,并且能够检测到更低红移处的 C I 吸收线。
研究还表明,CNN 方法可以有效地用于寻找两个波长较宽的弱碳吸收线。考虑到类星体光谱中的许多其他谱线或具有类似连续光谱的其他谱线(如恒星光谱)彼此之间是广泛分离的,这些谱线在各种研究中都很重要,因此可以采用该方法来搜索吸收谱线或发射谱线的任意组合。
天文领域的 AI 应用,助力人类走向星辰大海
事实上,葛健教授的最新研究只是揭开了 AI 技术在天文领域应用的冰山一角。随着天文学的不断发展,人们所面临的挑战也日益复杂,从海量的数据管理到深空探测的精确导航,再到对遥远星系的细致研究,这些都需要超越传统方法的解决方案。
AI 技术的引入,不仅能够处理和分析天文观测产生的庞大数据集,还能在模式识别、预测建模和自动化观测中发挥关键作用,极大地扩展了我们对宇宙的认知边界。
过去几年,研究者开始越来越多的通过 AI 理解宇宙。 2022 年,美国能源部阿贡国家实验室的计算机科学家和芝加哥大学、伊利诺伊大学厄巴纳香槟分校、 NVIDIA 和 IBM 等机构合作,通过 AI 和超级计算机的结合,在不到 7 分钟的时间里便处理完成了一个月的数据量,同时还识别出 4 种由黑洞合并产生的引力波信号。
2023 年,马斯克正式成立 xAI 公司,目标就是了解宇宙的真实本质。马斯克曾在采访中表示,「从某种意义上说,一个关心理解宇宙的人工智能不太可能灭绝人类,因为我们是宇宙中有趣的一部分。」今年 5 月,xAI 公司获得超 60 亿美元的 B 轮融资,这也使得这家成立不到 10 个月的公司估值达到了约 180 亿美元。
2024 年 4 月,中国科学院国家天文台人工智能工作组发布新一代天文大模型「星语 3.0」,基于通义千问开源模型打造,目前已成功接入国家天文台兴隆观测站望远镜阵列 Mini 司天。这是大模型在科学领域落地的经典案例,也是大模型在天文观测领域的首次应用。
茫茫宇宙,未知似乎永远大于已知,但 AI 的探索已经初现峥嵘。我们有理由相信,随着技术的不断成熟,AI 将在未来揭示更多关于宇宙的奥秘,帮助人类更深入地理解我们所在的宇宙,并带领我们走向星辰大海。








