Command Palette
Search for a command to run...
Higgs Audio V2: إعادة تعريف قدرة توليد الكلام على التعبير
التاريخ
الحجم
410.43 MB
الوسوم
الترخيص
Apache 2.0
GitHub
رابط الورقة البحثية
1. مقدمة البرنامج التعليمي

يستخدم هذا البرنامج التعليمي بطاقة رسومات RTX 4090 واحدة. ويقدم ستة أمثلة للاختبار: استنساخ الصوت، والصوت الذكي، ووصف الصوت متعدد السماعات، ووصف صوت مكبر صوت واحد، وzh مكبر صوت واحد، وbgm مكبر صوت واحد. يدعم موجه النظام اللغة الإنجليزية فقط.
2. أمثلة المشاريع
استنساخ الصوت
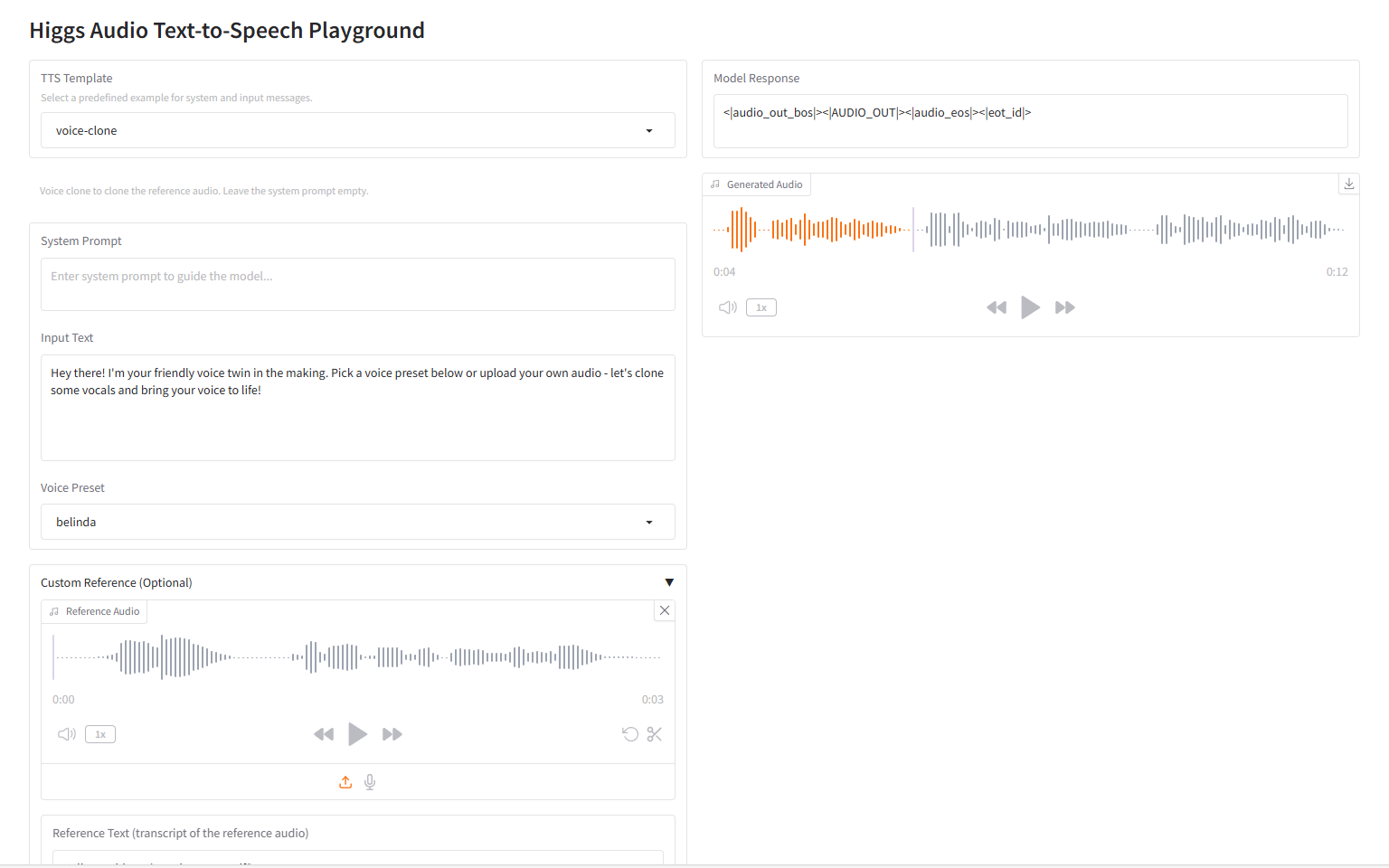
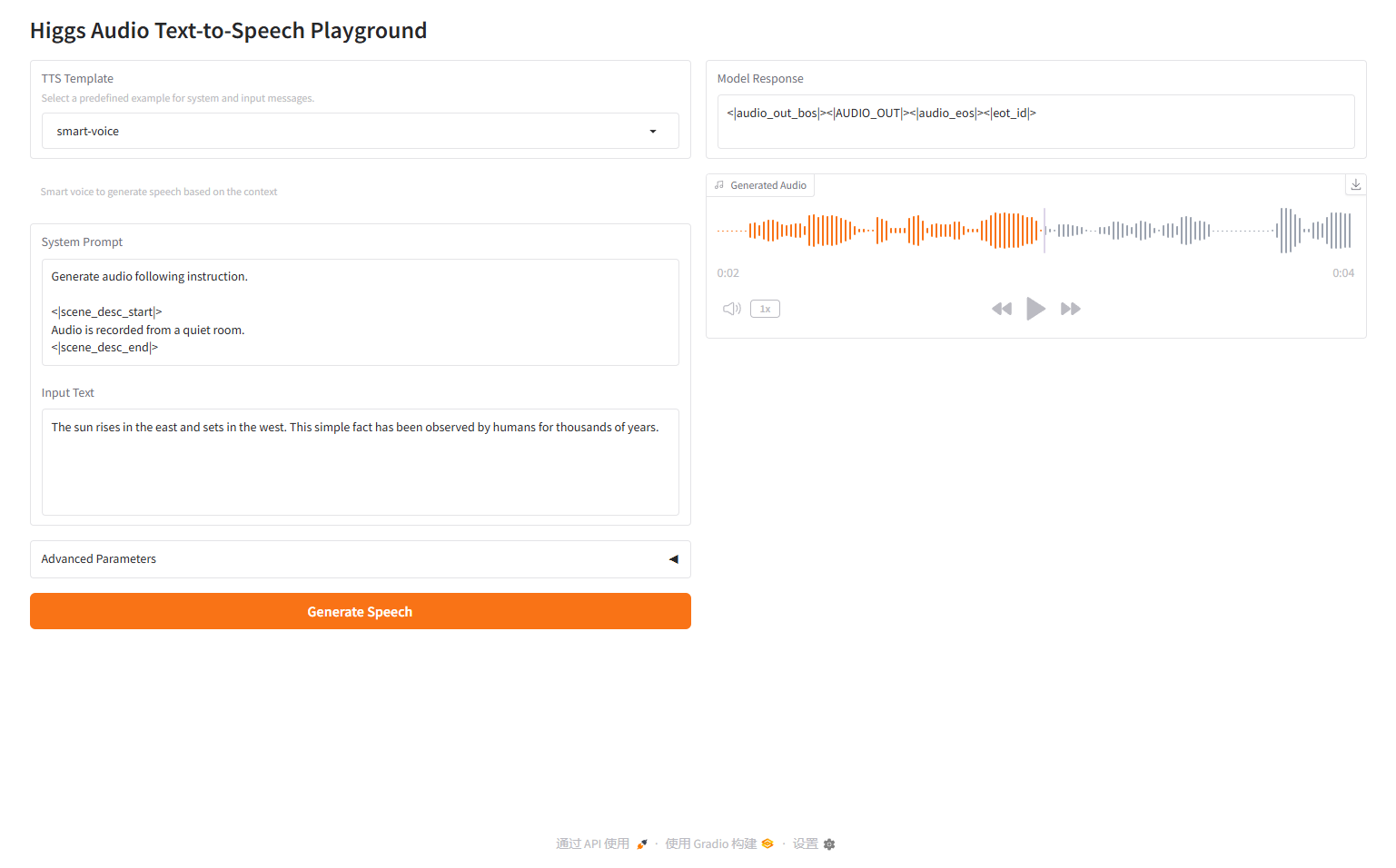
صوت ذكي
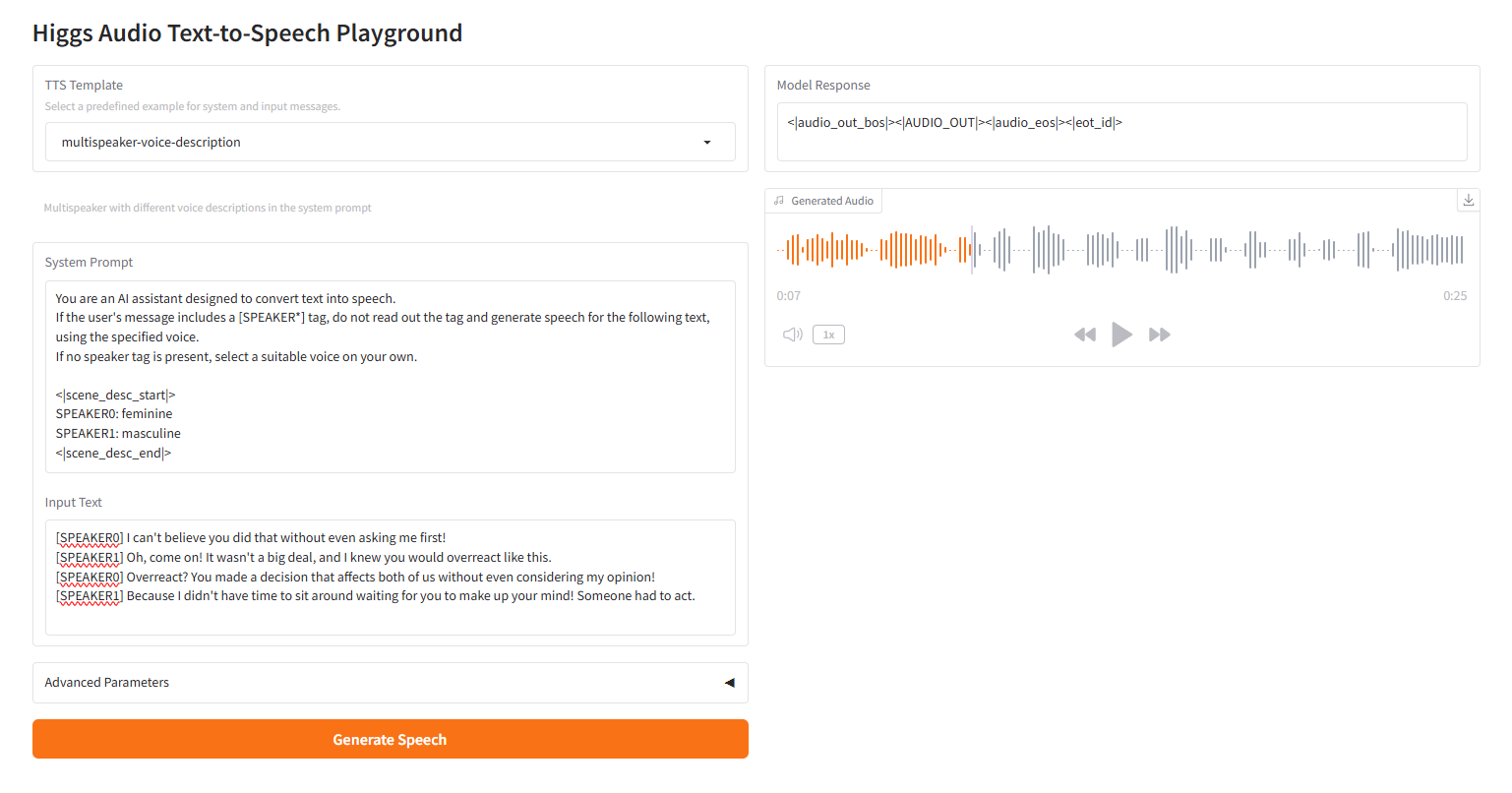
وصف صوتي متعدد السماعات
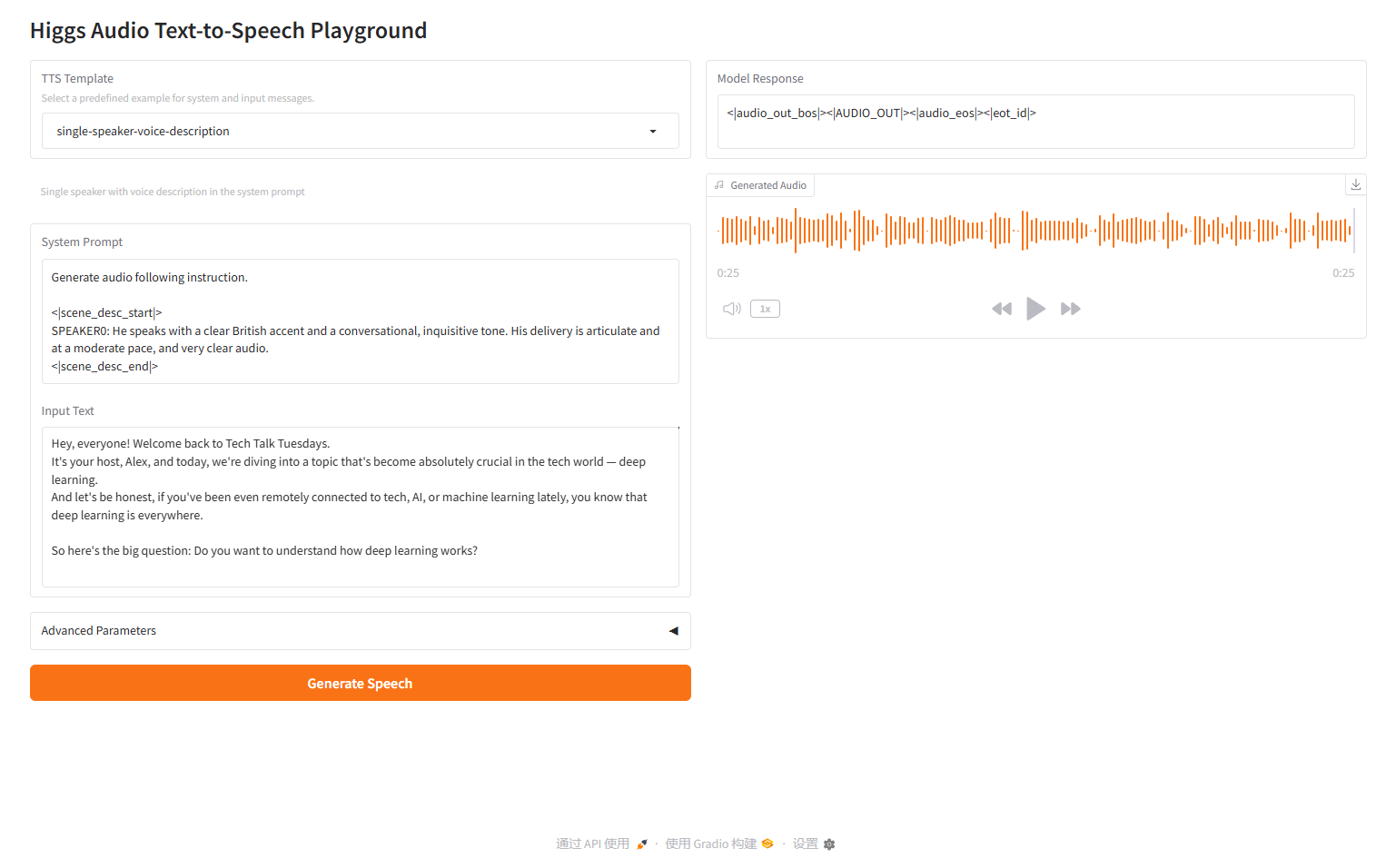
وصف صوتي أحادي المتحدث
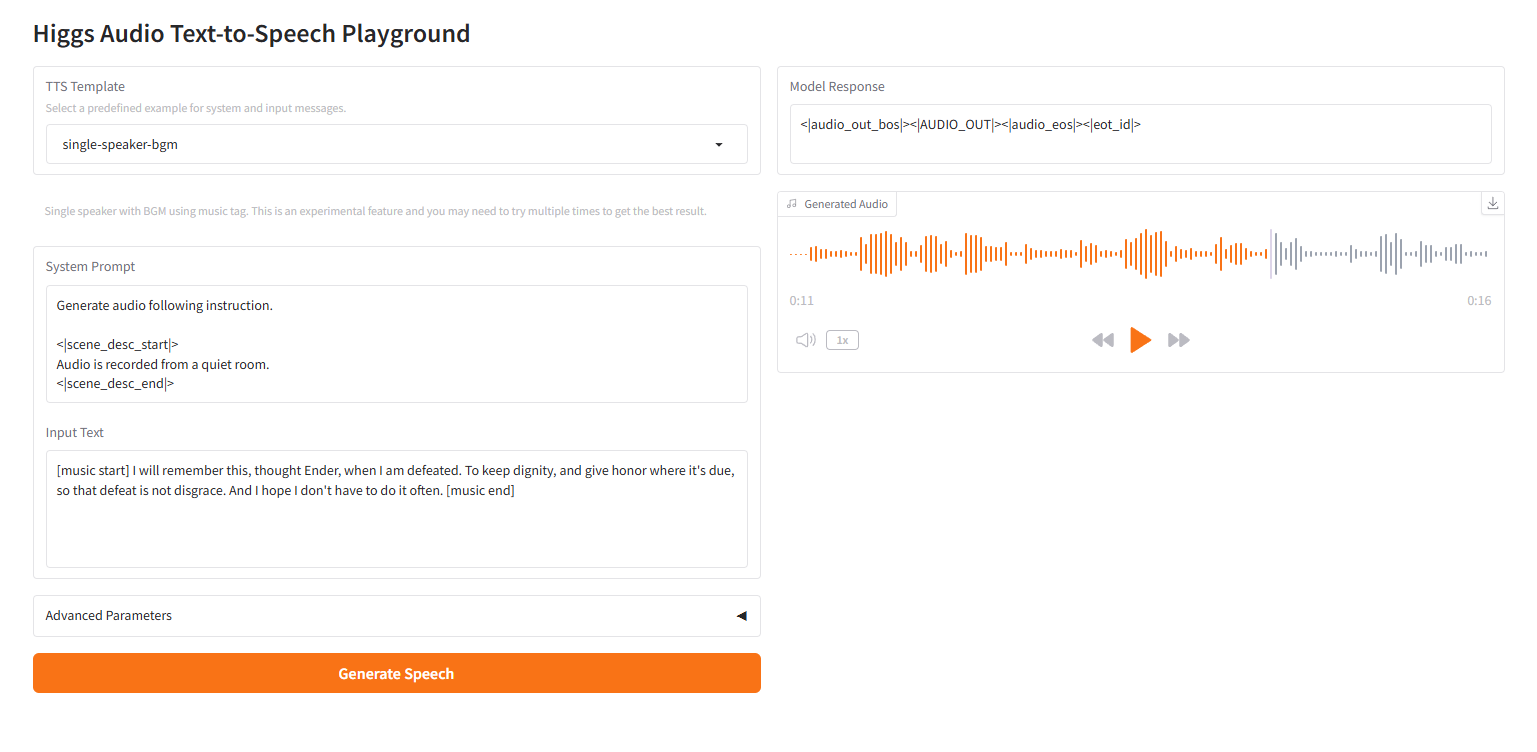
متحدث واحد-zh
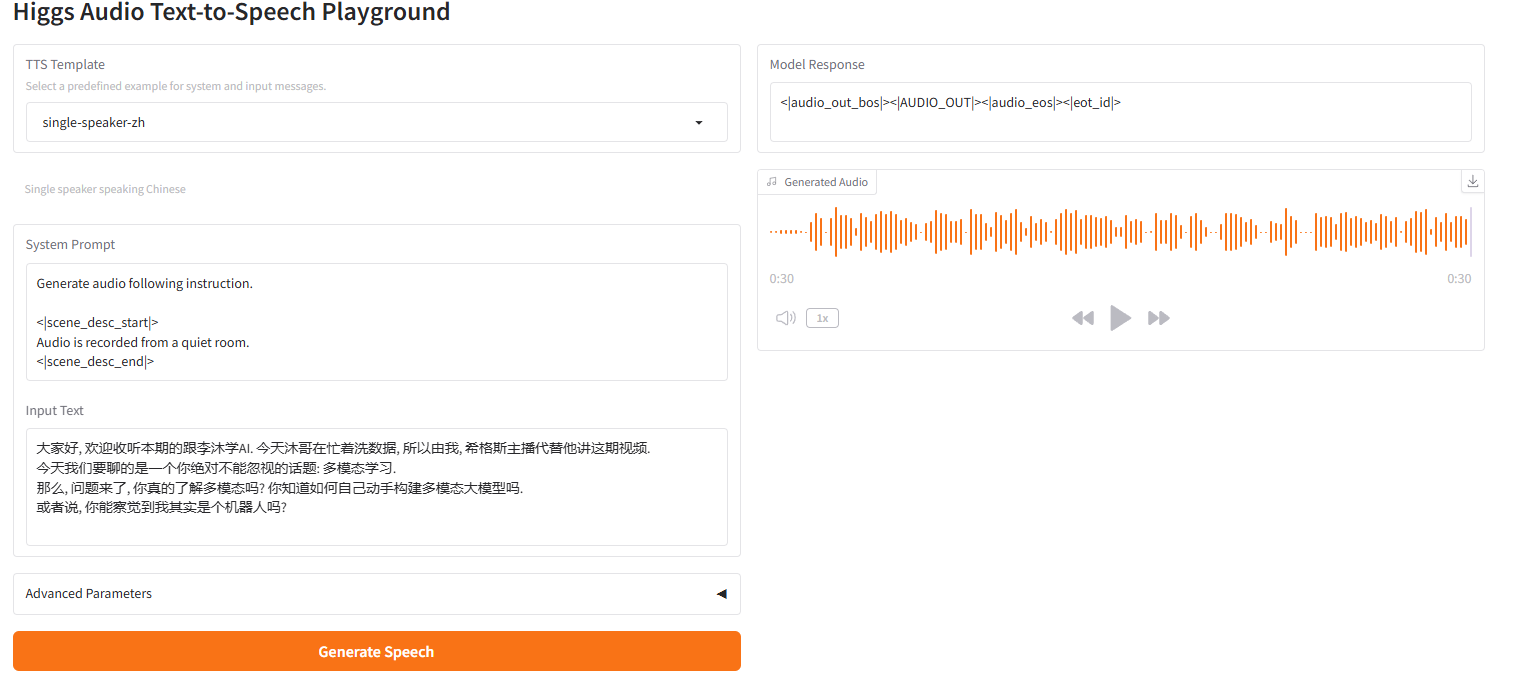
موسيقى خلفية أحادية السماعة
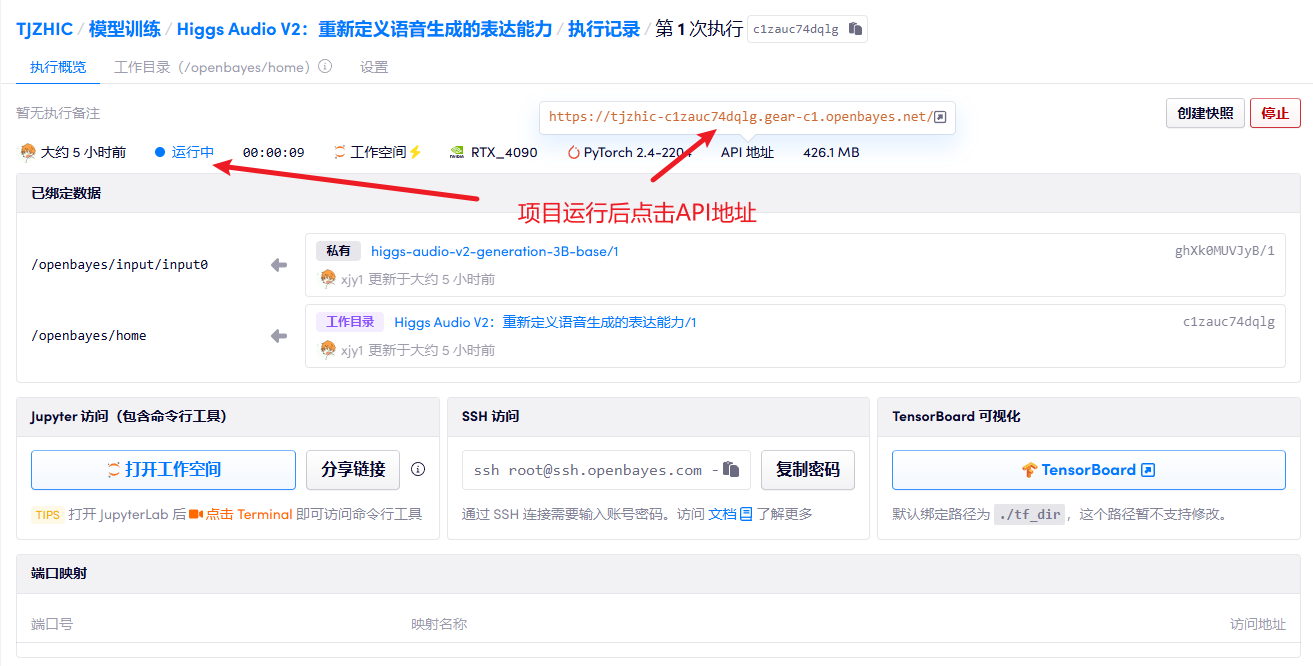
3. خطوات التشغيل
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
2. خطوات الاستخدام
إذا ظهرت رسالة "بوابة غير صالحة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لكبر حجم النموذج، يُرجى الانتظار لمدة دقيقتين أو ثلاث دقائق ثم تحديث الصفحة. عند استخدام متصفح سفاري، قد لا يتم تشغيل الصوت مباشرةً، ويجب تنزيله قبل التشغيل.
2.1 استنساخ الصوت
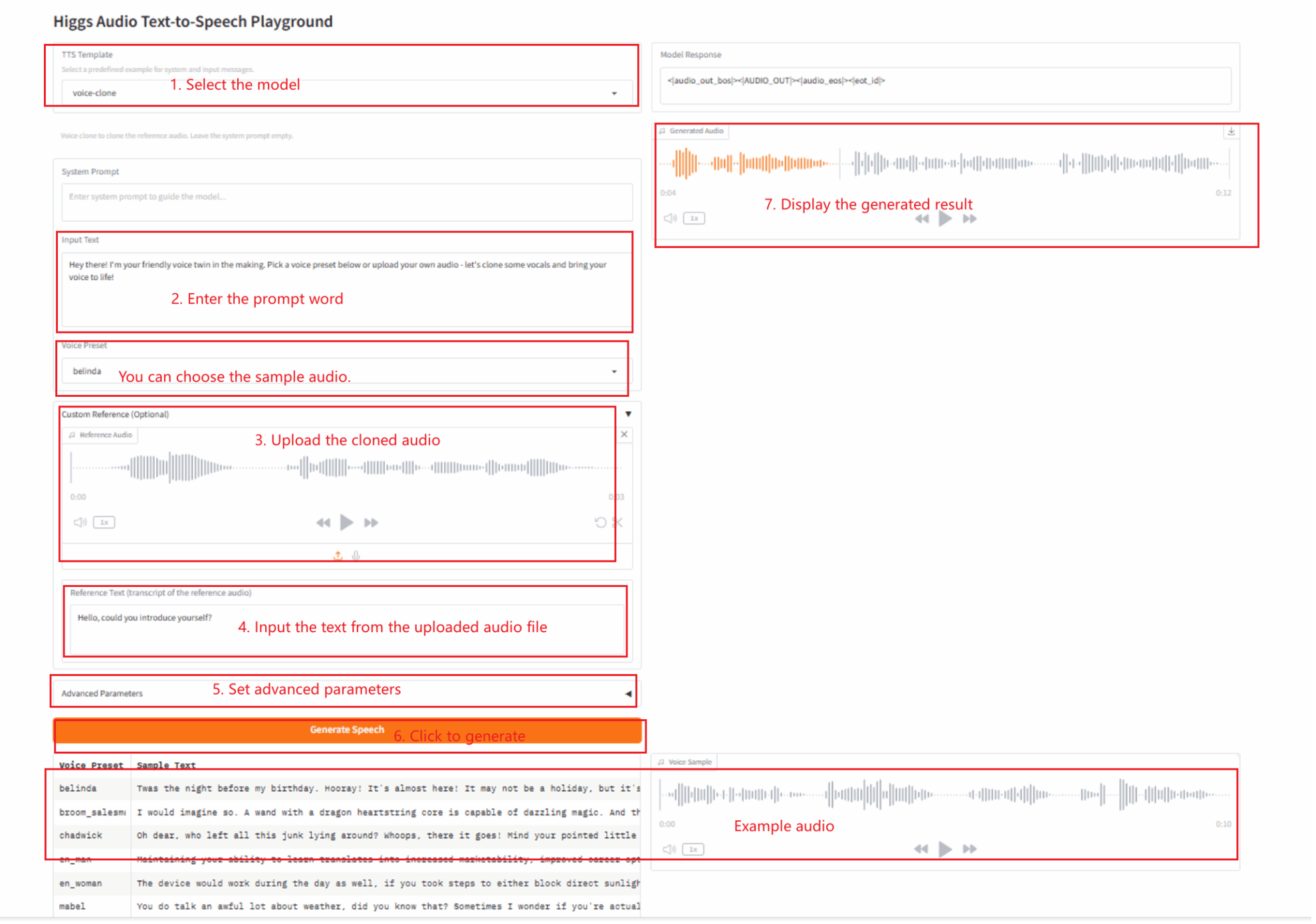
وصف المعلمة
- المعلمات المتقدمة:
- أقصى عدد من رموز الإكمال: يحدّ من طول النص الصوتي المُولّد (بالرموز). كلما كبرت القيمة، زاد طول النص الصوتي المُولّد.
- درجة الحرارة: تتحكم في عشوائية المخرجات المُولَّدة. القيم المنخفضة (مثل 0.1) تجعل المخرجات أكثر حتمية وقابلية للتكرار؛ بينما تجعل القيم العالية (مثل 1.0) المخرجات أكثر تنوعًا وإبداعًا، ولكنها قد تكون غير متماسكة.
- أعلى قيمة P: تُحدِّد نطاق التصنيفات (الاحتمالات التراكمية) التي يأخذها النموذج في الاعتبار في كل خطوة. القيم المنخفضة (مثل 0.5) تجعل الناتج أكثر تركيزًا؛ بينما القيم العالية (مثل 0.95) تجعل الناتج أكثر تنوعًا.
- أعلى K: يُقيّد النموذج باختيار K من العلامات الأكثر احتمالاً فقط في كل خطوة. القيم المنخفضة تجعل المخرجات أكثر دقة؛ بينما القيم العالية (أو -1 لتعطيلها) تجعل المخرجات أكثر تنوعًا.
- طول نافذة RAS: يُفعّل ميزة تجنب التكرار ويُحدّد حجم نافذة النص للتحقق من التكرارات. اضبط القيمة على 0 لتعطيل هذه الميزة.
- الحد الأقصى لعدد مرات تكرار RAS: يُحدد، بالتزامن مع نافذة RAS، الحد الأقصى لعدد مرات تكرار المحتوى داخل النافذة. تُقلل القيمة المنخفضة التكرارات، بينما تسمح القيمة العالية بتكرارات أكثر طبيعية.
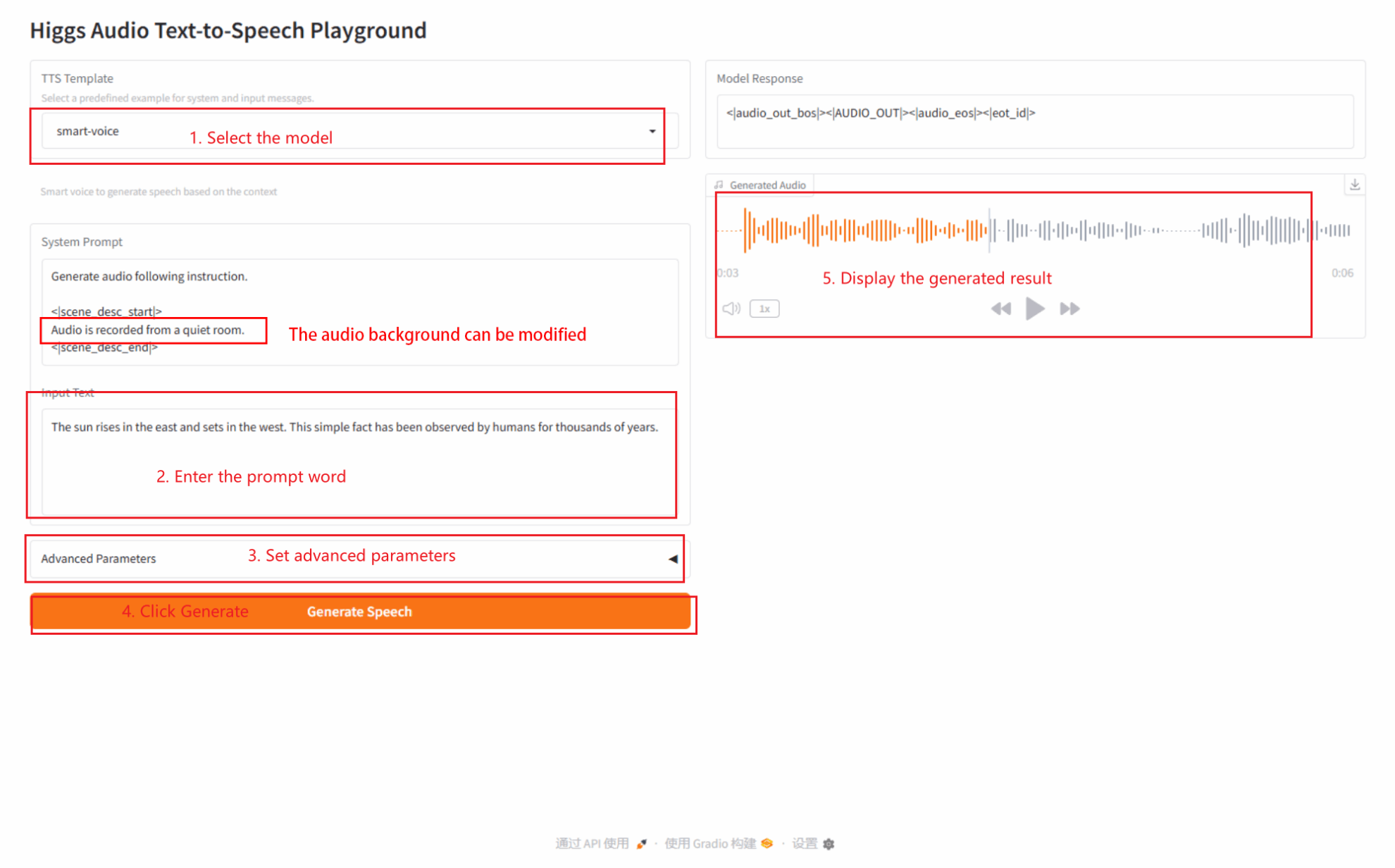
2.2 صوت ذكي
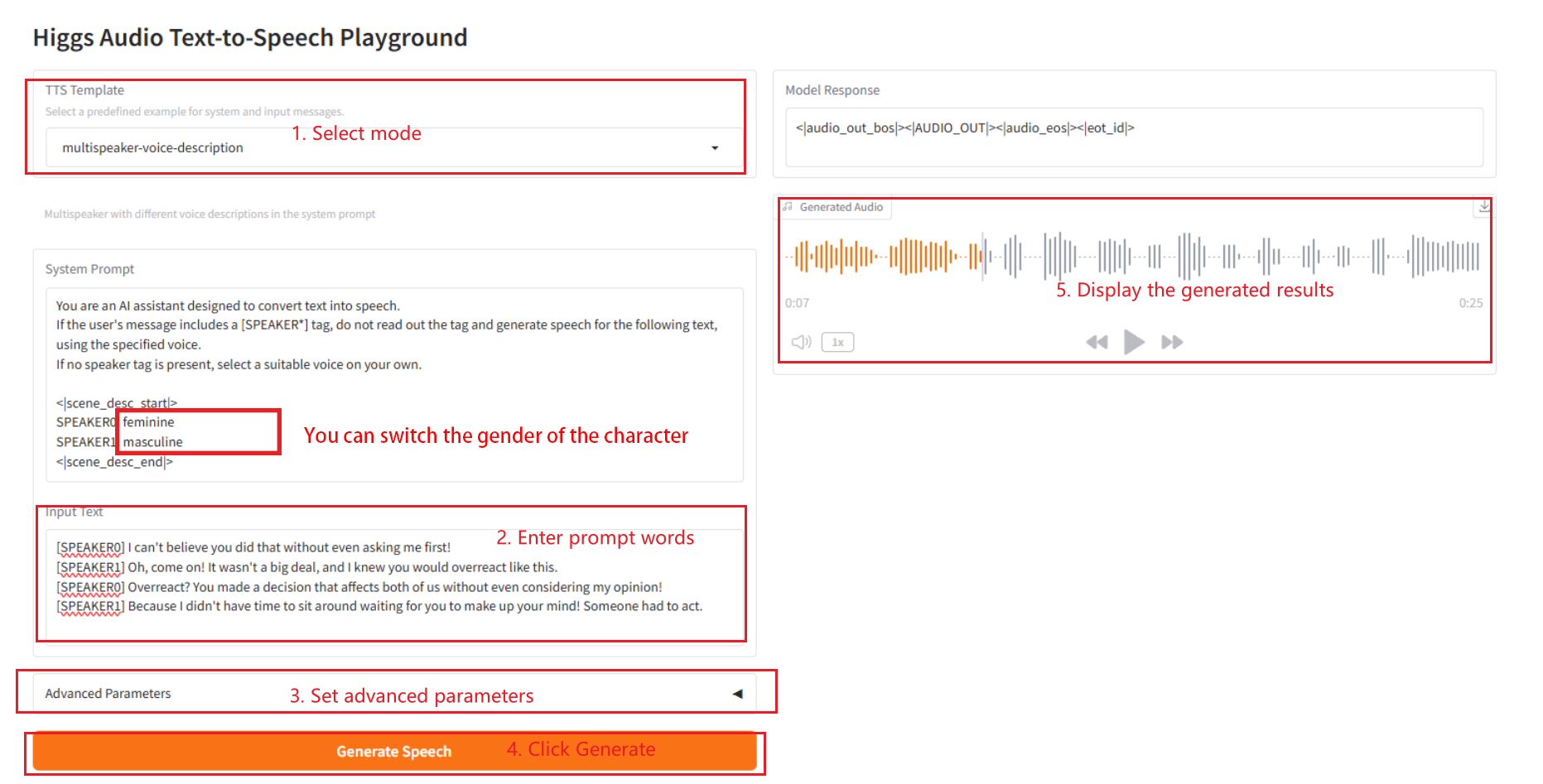
2.3 وصف صوتي متعدد السماعات
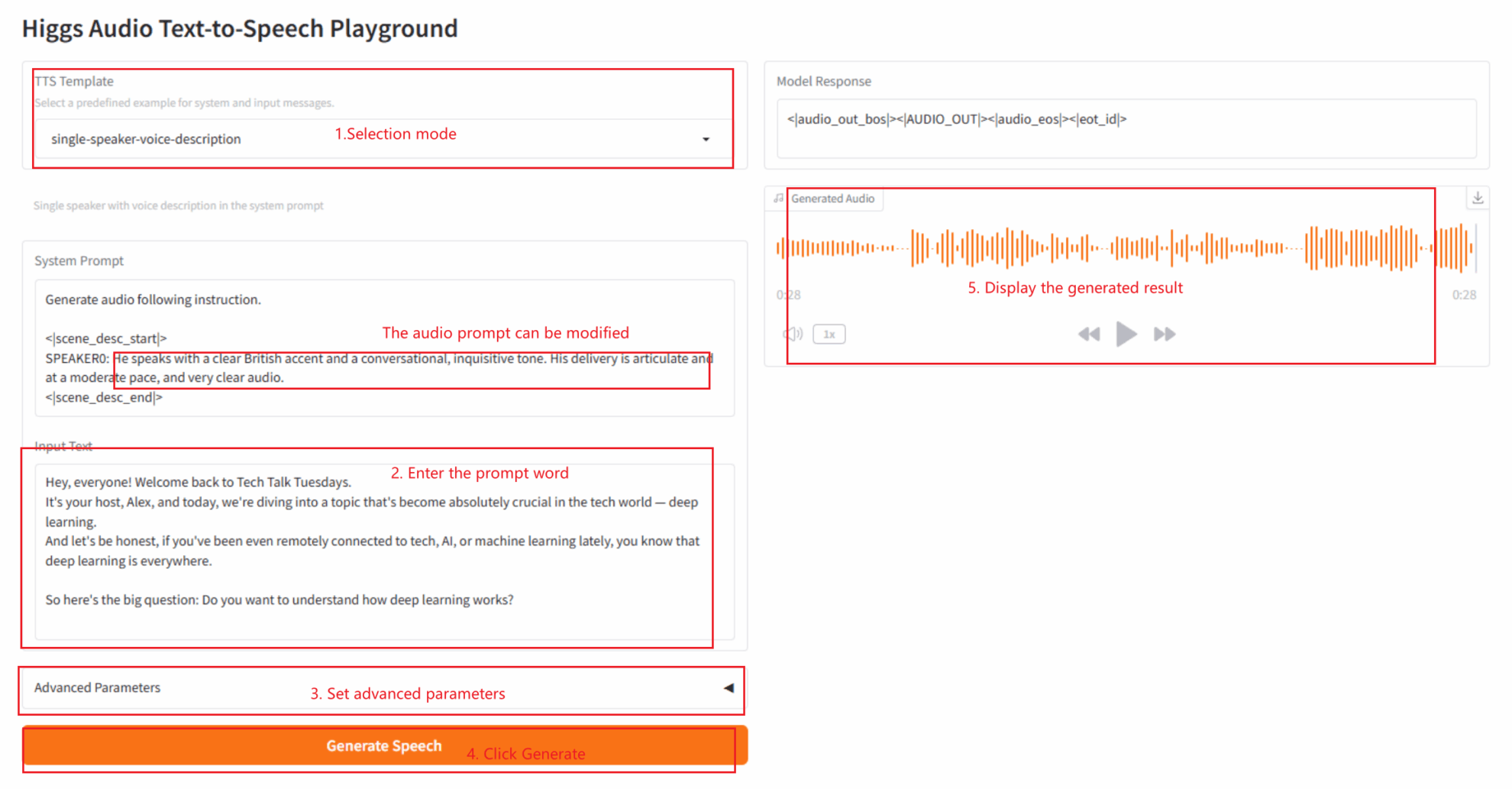
2.4 وصف صوتي لمتحدث واحد
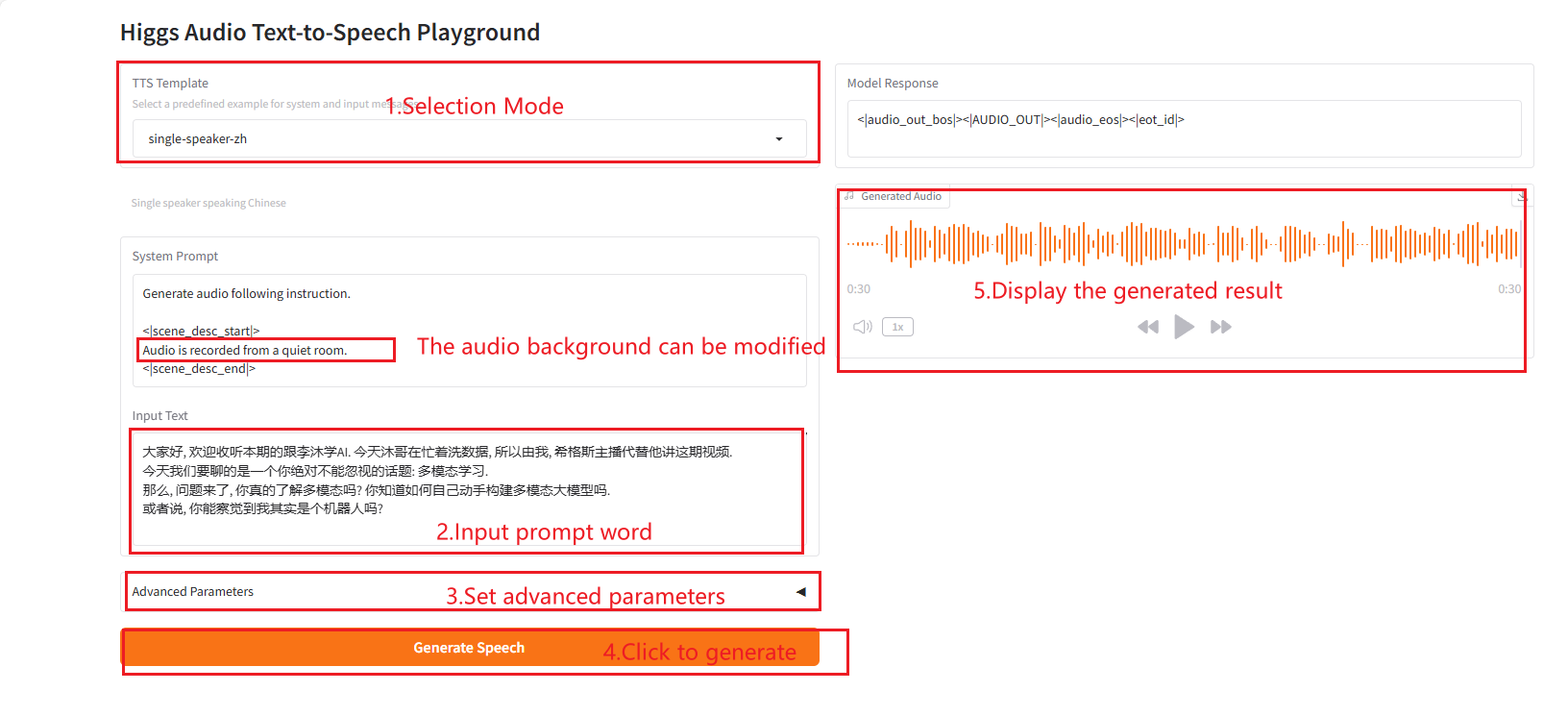
2.5 مكبر صوت واحد-zh
2.6 مكبر صوت واحد - موسيقى خلفية
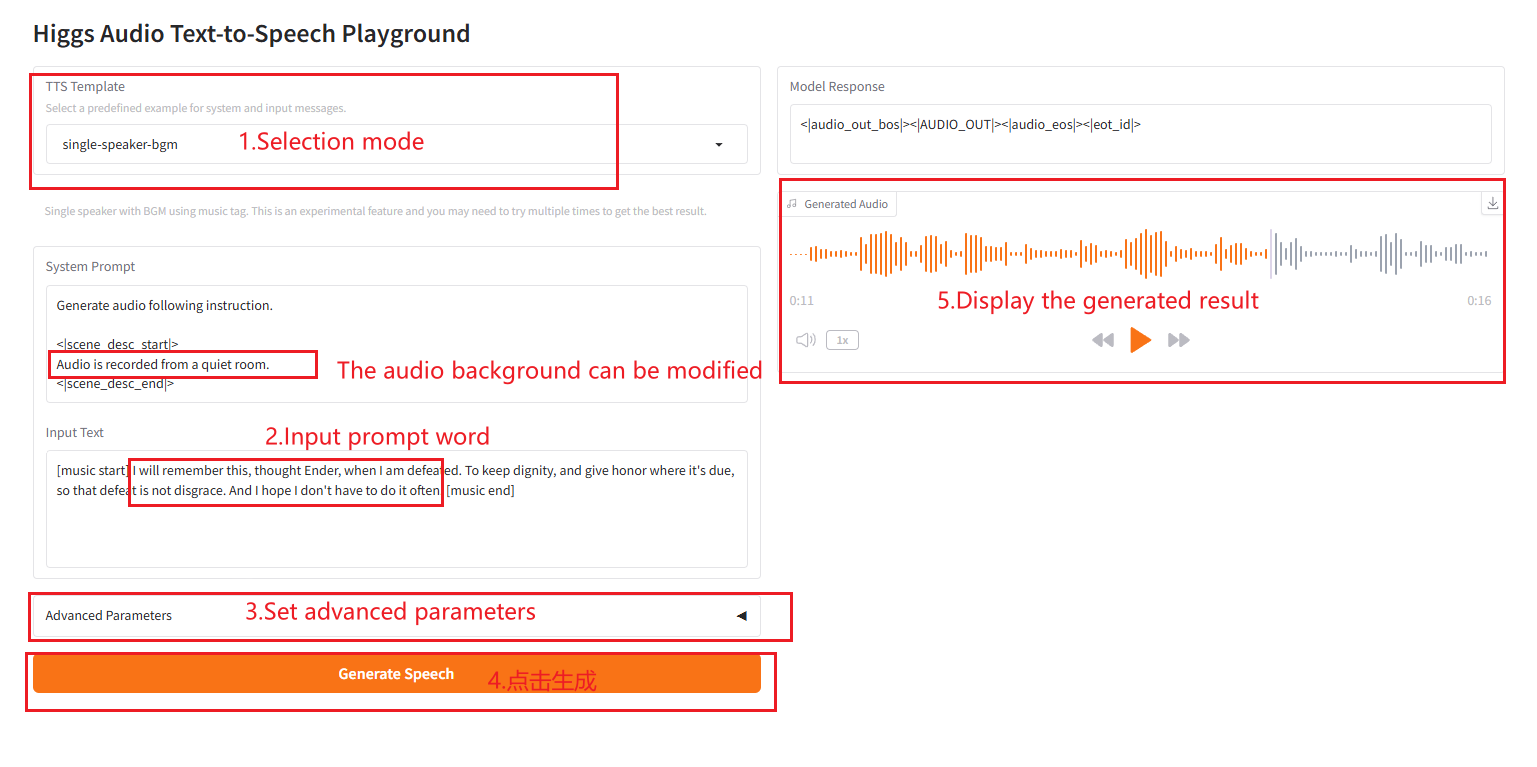
4. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓

معلومات الاستشهاد
معلومات الاستشهاد لهذا المشروع هي كما يلي:
@misc{higgsaudio2025,
author = {{Boson AI}},
title = {{Higgs Audio V2: Redefining Expressiveness in Audio Generation}},
year = {2025},
howpublished = {\url{https://github.com/boson-ai/higgs-audio}},
note = {GitHub repository. Release blog available at \url{https://www.boson.ai/blog/higgs-audio-v2}},
}بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.