Command Palette
Search for a command to run...
موس: توليد الحوار من النص إلى الكلام
التاريخ
الحجم
8.4 MB
الوسوم
الترخيص
Apache 2.0
GitHub
رابط الورقة البحثية
1. مقدمة البرنامج التعليمي

يستخدم هذا البرنامج التعليمي بطاقة RTX 5090 واحدة كمورد.
2. أمثلة المشاريع
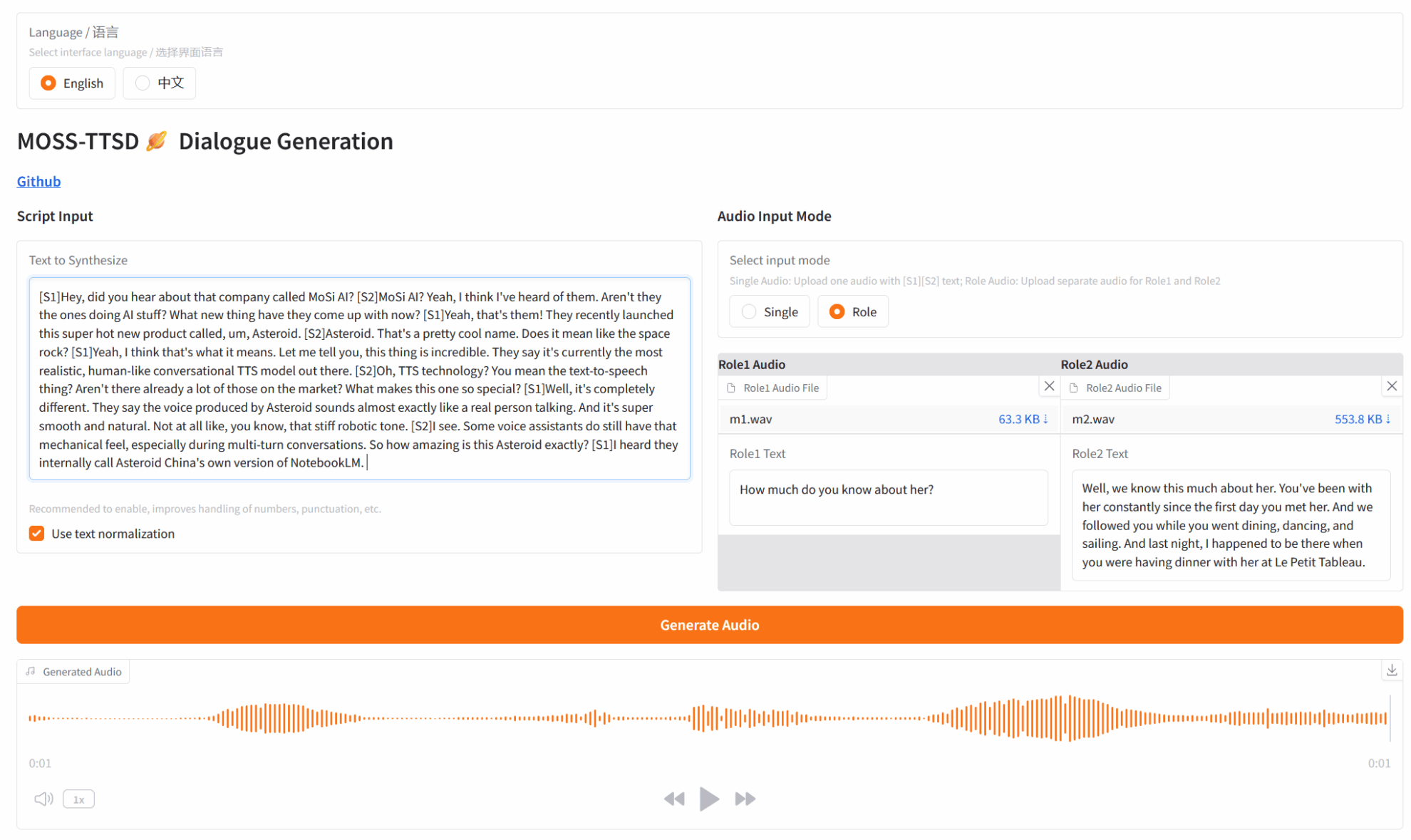
3. خطوات التشغيل
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
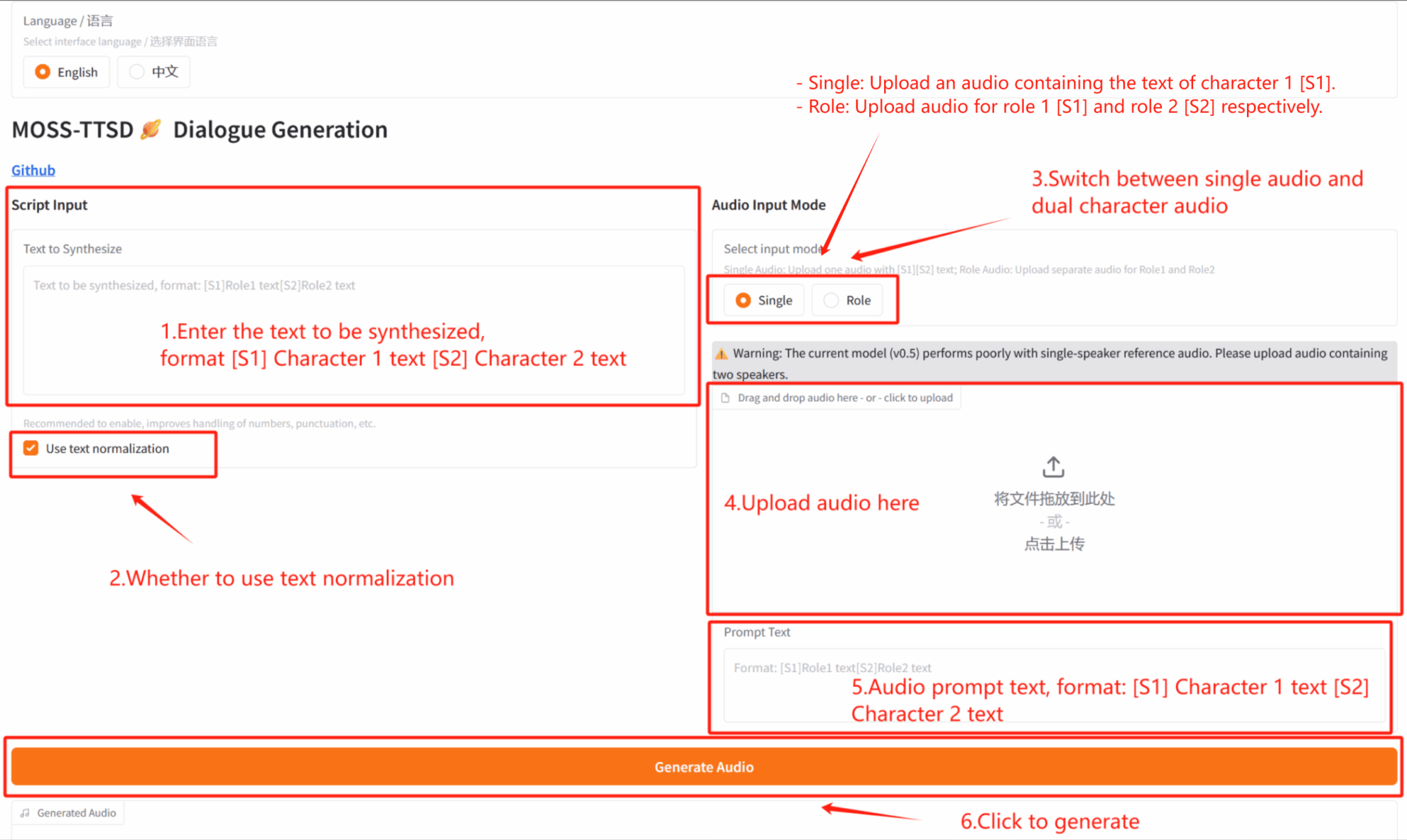
2. خطوات الاستخدام
إذا ظهرت رسالة "بوابة غير صالحة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لكبر حجم النموذج، يُرجى الانتظار لمدة دقيقتين أو ثلاث دقائق ثم تحديث الصفحة. عند استخدام متصفح سفاري، قد لا يتم تشغيل الصوت مباشرةً، ويجب تنزيله قبل التشغيل.
*يسمح لك هذا البرنامج التعليمي بالاختيار بين إنشاء صوت لاعب واحد (فردي) وإنشاء صوت حوار لاعبين (الدور) في "وضع إدخال الصوت".
معلومات الاستشهاد
معلومات الاستشهاد لهذا المشروع هي كما يلي:
@article{moss2025ttsd,
title={Text to Spoken Dialogue Generation},
author={OpenMOSS Team},
year={2025}
}بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.