Command Palette
Search for a command to run...
PlayDiffusion: نموذج تحرير الصوت المحلي مفتوح المصدر
التاريخ
الحجم
1.35 MB
الوسوم
الترخيص
Apache 2.0
GitHub
رابط الورقة البحثية
1. مقدمة البرنامج التعليمي

المميزات الرئيسية:
- تحرير الصوت الجزئي: يدعم الاستبدال الجزئي أو التعديل أو الحذف للصوت دون إعادة إنشاء مقطع الصوت بالكامل، مما يحافظ على الصوت طبيعيًا وسلسًا.
- تحويل نص إلى كلام فعال: عند إخفاء الصوت بأكمله، كنموذج تحويل نص إلى كلام فعال، تكون سرعة الاستدلال أسرع بـ 50 مرة من تحويل النص إلى كلام التقليدي، كما أن طبيعية الكلام وتناسقه أفضل.
- الحفاظ على استمرارية الكلام: الحفاظ على السياق عند التحرير لضمان استمرارية الكلام وتناسق صوت المتحدث.
- تعديل الصوت الديناميكي: ضبط نطق الصوت ونبرته وإيقاعه تلقائيًا وفقًا للنص الجديد، وهو مناسب لسيناريوهات مثل التفاعل في الوقت الفعلي.
المبدأ الفني:
- ترميز الصوت: يُرمِّز تسلسل الصوت المُدخل إلى سلسلة مُنفصلة من الرموز، حيث يُمثِّل كل رمز وحدة صوتية. ينطبق هذا على الكلام الحقيقي والصوت المُولَّد بواسطة نماذج تحويل النص إلى كلام.
- معالجة القناع: عندما يكون هناك حاجة إلى تعديل جزء من الصوت، قم بتمييز الجزء كقناع لتسهيل المعالجة اللاحقة.
- إزالة الضوضاء بنموذج الانتشار: إزالة الضوضاء من المنطقة المقنعة بناءً على نموذج انتشار يُحدِّث النص. يُولِّد نموذج الانتشار سلسلة عالية الجودة من الرموز الصوتية بناءً على إزالة الضوضاء تدريجيًا. تُولَّد جميع الرموز في آنٍ واحد باستخدام طريقة غير انحدارية، وتُحسَّن بناءً على عدد ثابت من خطوات إزالة الضوضاء.
- فك التشفير إلى شكل موجة صوتية: يتم تحويل تسلسل الرمز الناتج مرة أخرى إلى شكل موجة كلامية استنادًا إلى نموذج فك التشفير BigVGAN لضمان أن يكون الكلام الناتج النهائي طبيعيًا ومتماسكًا.
يستخدم هذا البرنامج التعليمي موردًا حاسوبيًا واحدًا لبطاقة RTX A6000، ويقدم ثلاثة أمثلة للاختبار: Inpaint، وText to Speech، وVoice Conversion. يدعم هذا البرنامج التعليمي اللغة الإنجليزية فقط.
2. عرض التأثير
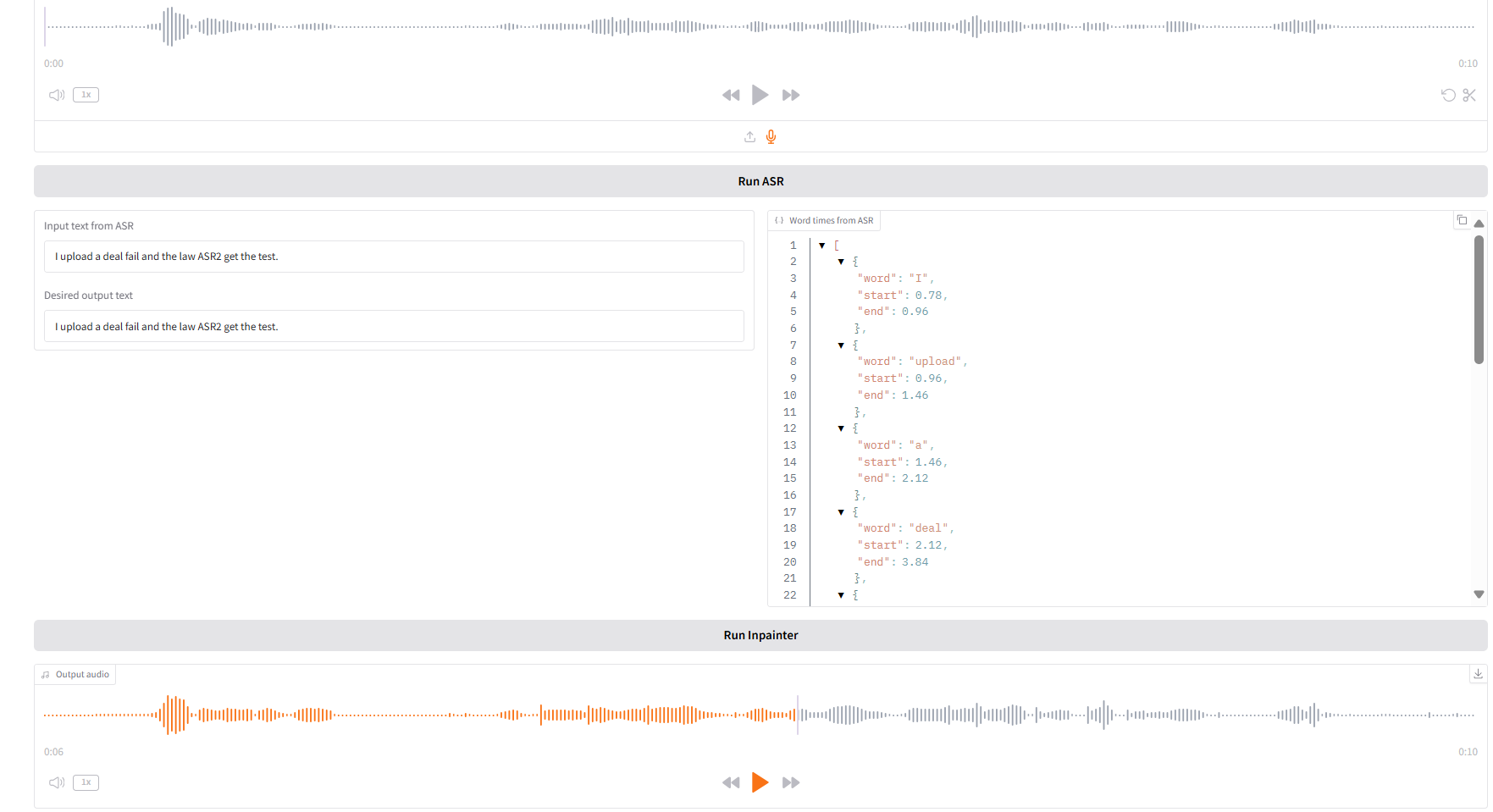
1. إنبينت
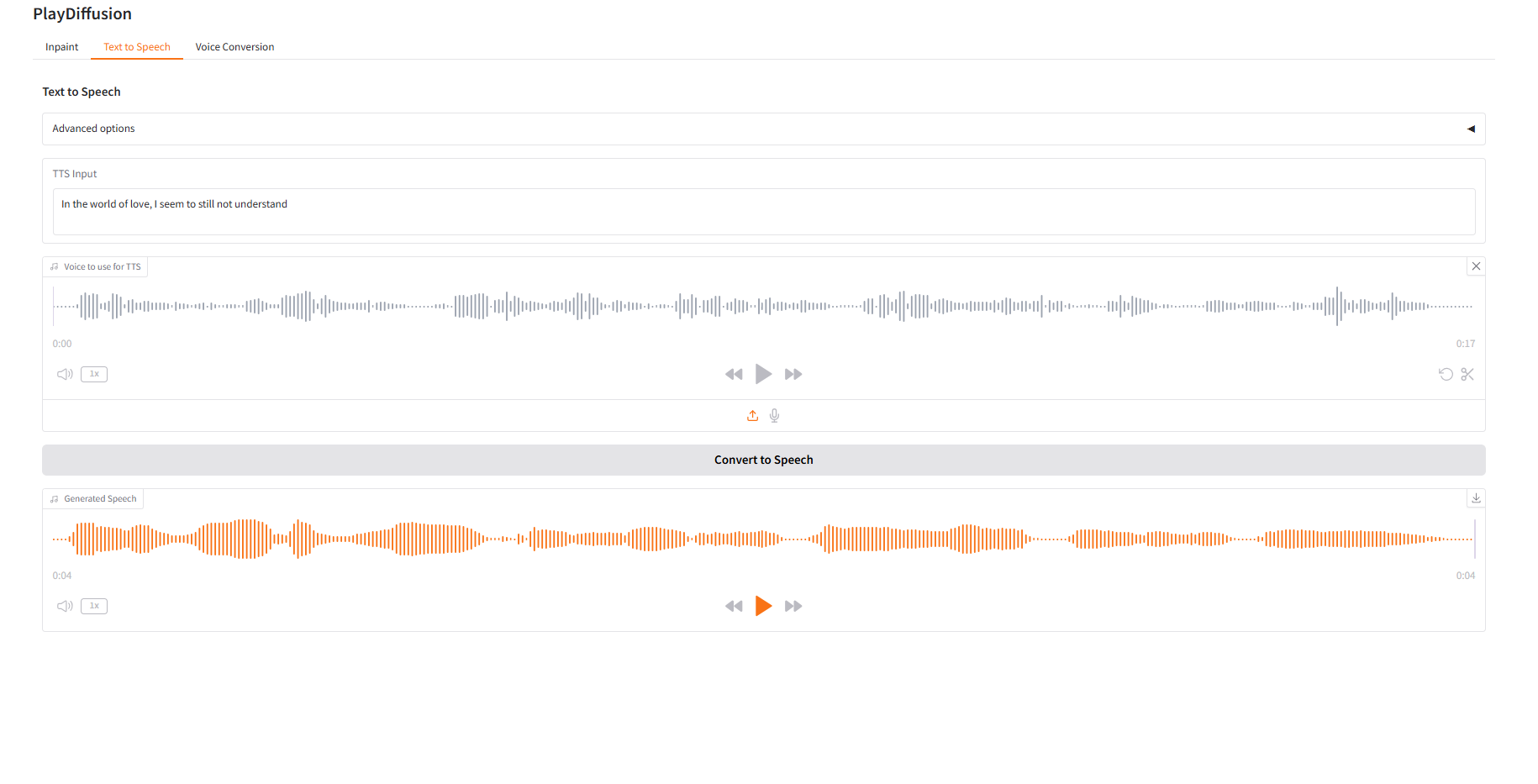
2. تحويل النص إلى كلام
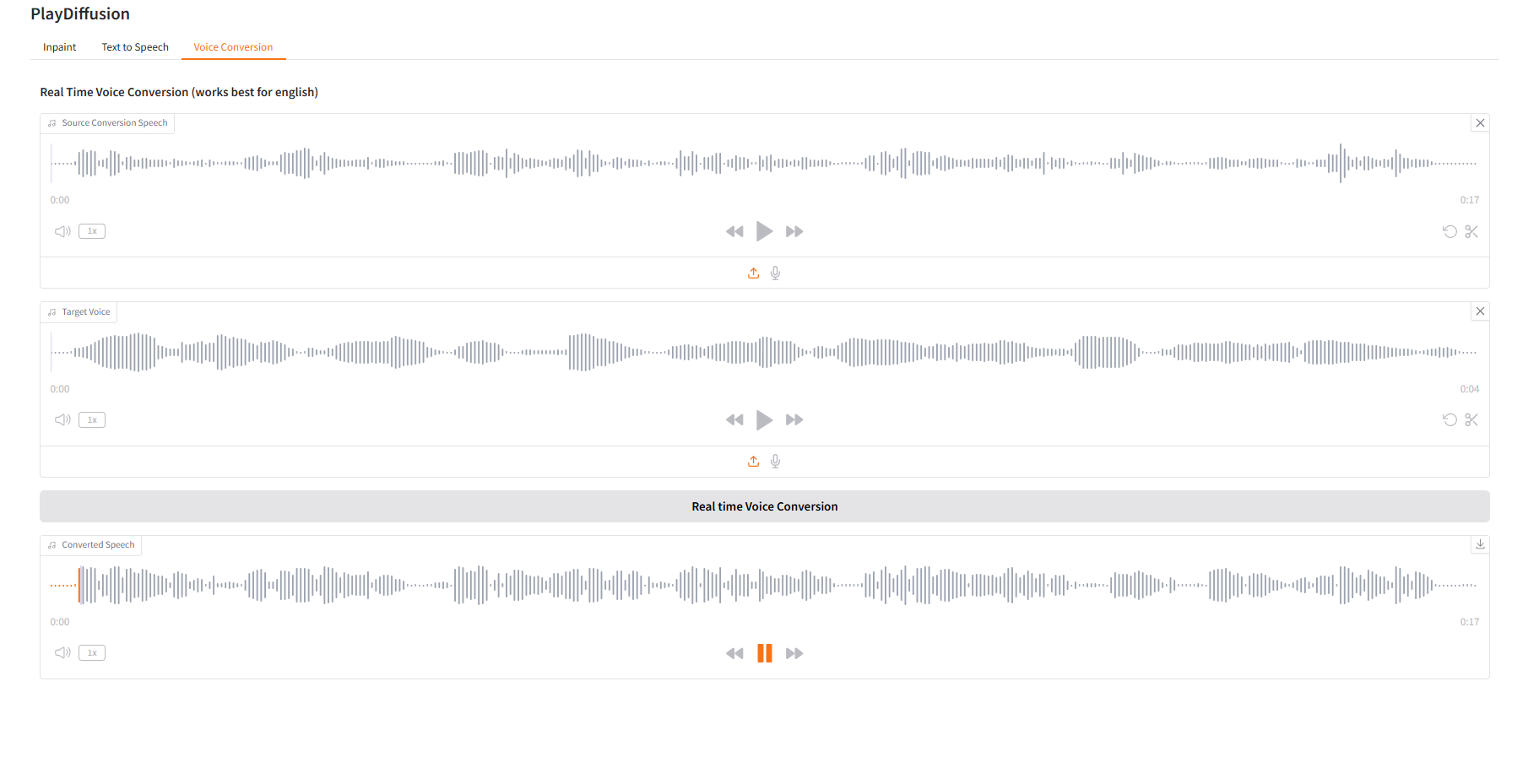
3. تحويل الصوت
3. خطوات التشغيل
1. ابدأ تشغيل الحاوية
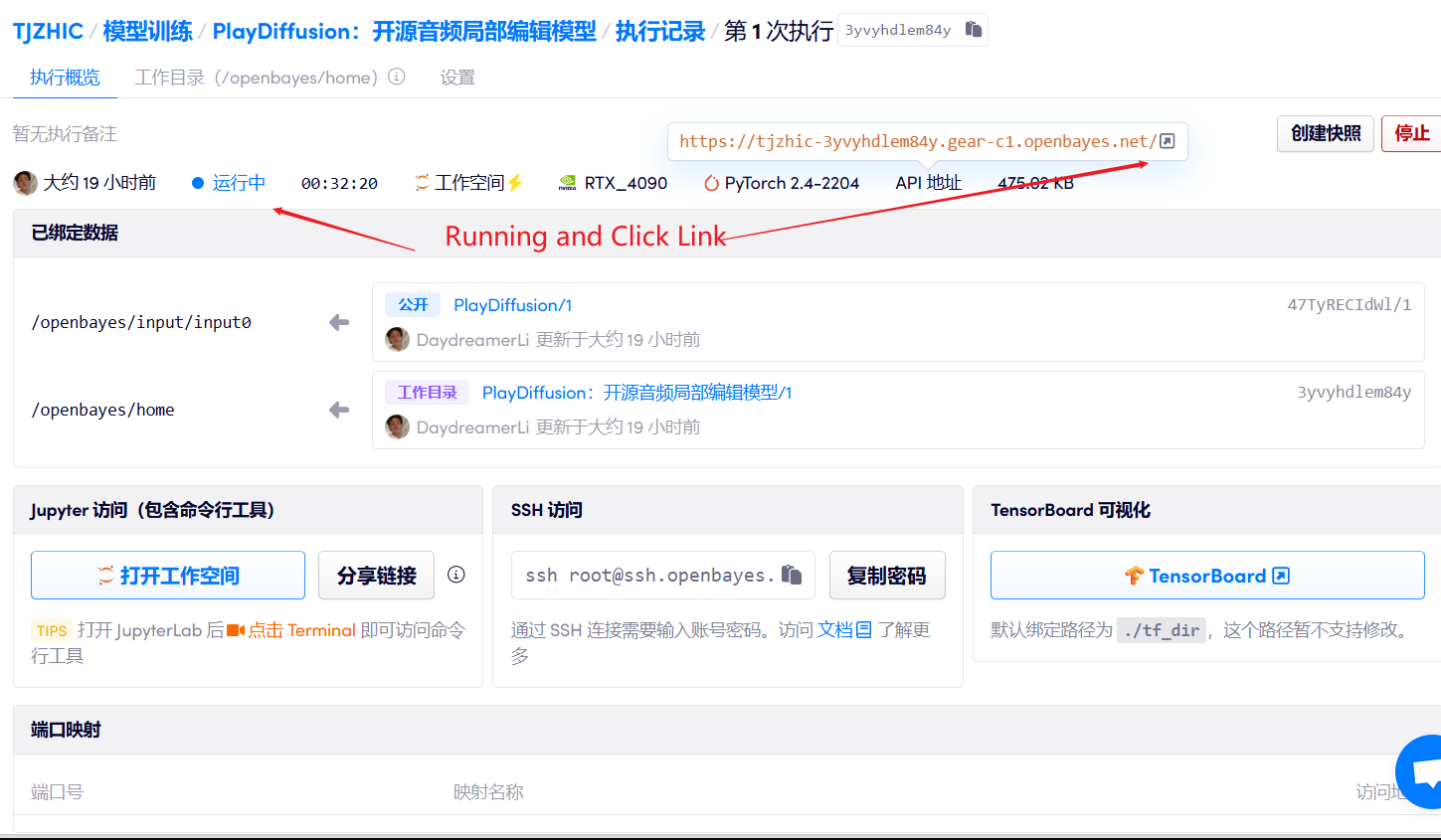
2. خطوات الاستخدام
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 2-3 دقائق وتحديث الصفحة.
عند استخدام متصفح Safari، قد لا يتم تشغيل الصوت مباشرة ويجب تنزيله قبل التشغيل.
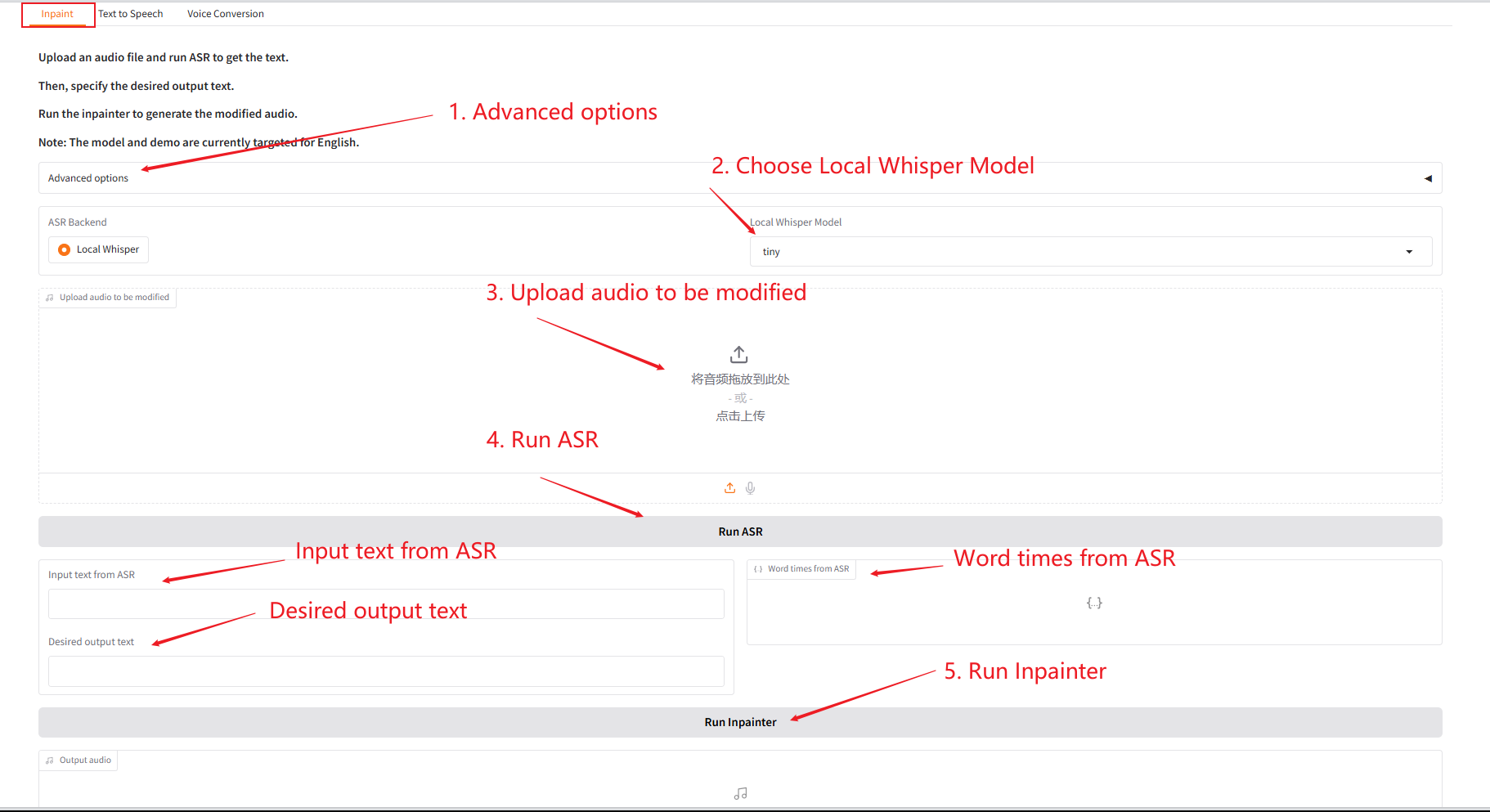
1. إنبينت
يمكن لهذه الوحدة استبدال الصوت جزئيًا أو تعديله أو حذفه دون إعادة إنشاء الصوت بالكامل، مما يحافظ على الكلام طبيعيًا وسلسًا.
- قم بتحميل الصوت الأصلي، ثم انقر فوق "تشغيل SAR" لتشغيله، ثم قم بتعديل وتحرير محتوى الصوت الذي تريد إخراجه في "نص الإخراج المطلوب".
- ثم انقر فوق "تشغيل Inpainter" لتوليد الصوت المحرر.
وصف المعلمة:
- عدد خطوات أخذ العينات: عدد التكرارات في عملية إنشاء نموذج الانتشار. كلما زاد عدد الخطوات، زادت جودة التوليد، لكن الوقت المطلوب أطول.
- كتاب الرموز: قاموس للرموز المنفصلة في طبقة التكميم المتجهة، يستخدم لرسم خريطة للميزات المستمرة في تمثيلات منفصلة.
- درجة الحرارة الابتدائية: مُعامل يُتحكم في عشوائية أخذ العينات. كلما ارتفعت القيمة، زاد التنوع، وكلما انخفضت، زادت دقة النتيجة.
- التنوع الأولي: المعلمات التي تتحكم في درجة التباين في العينات المولدة لتجنب توليد نتائج متشابهة للغاية.
- التوجيه: ضبط درجة تأثير المعلومات الشرطية (مثل النص) على النتائج الناتجة.
- عامل إعادة مقياس التوجيه: نسبة الوزن المستخدمة لموازنة التوجيه الشرطي والتوليد غير المشروط.
- أخذ العينات من لوجيتات أعلى k: اختر فقط من بين المرشحين K الذين لديهم أعلى احتمال لتحسين جودة التوليد.
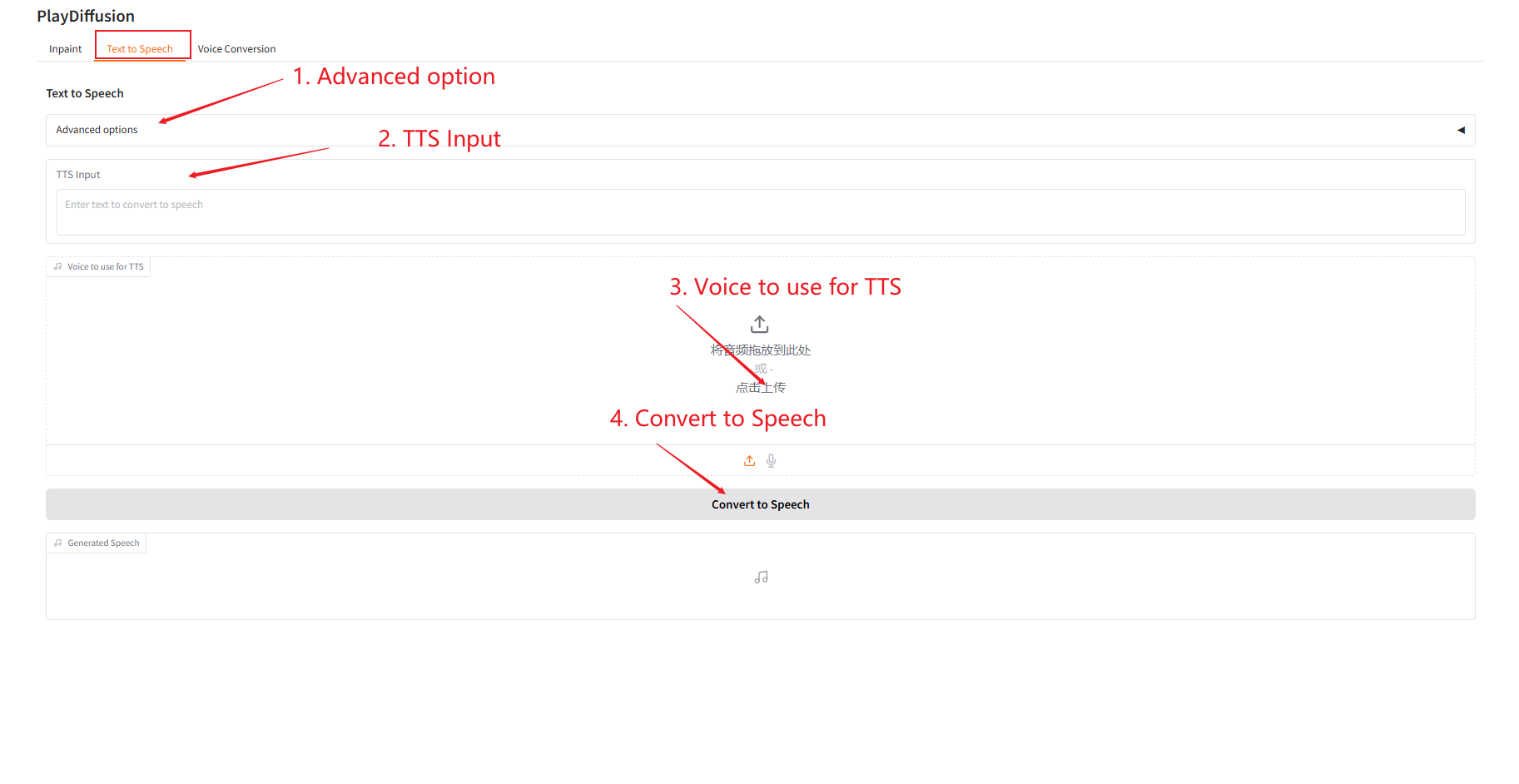
2. تحويل النص إلى كلام
باعتباره نموذج TTS فعال، فإن سرعة الاستدلال الخاصة به أسرع بـ 50 مرة من TTS التقليدي، كما أن طبيعية كلامه وتناسقه أفضل.
- أدخل محتوى النص الذي تريد إنشاء صوت له في "إدخال TTS" ثم قم بتحميل الصوت المستهدف.
- ثم انقر فوق "تحويل إلى كلام" لتوليد الصوت.
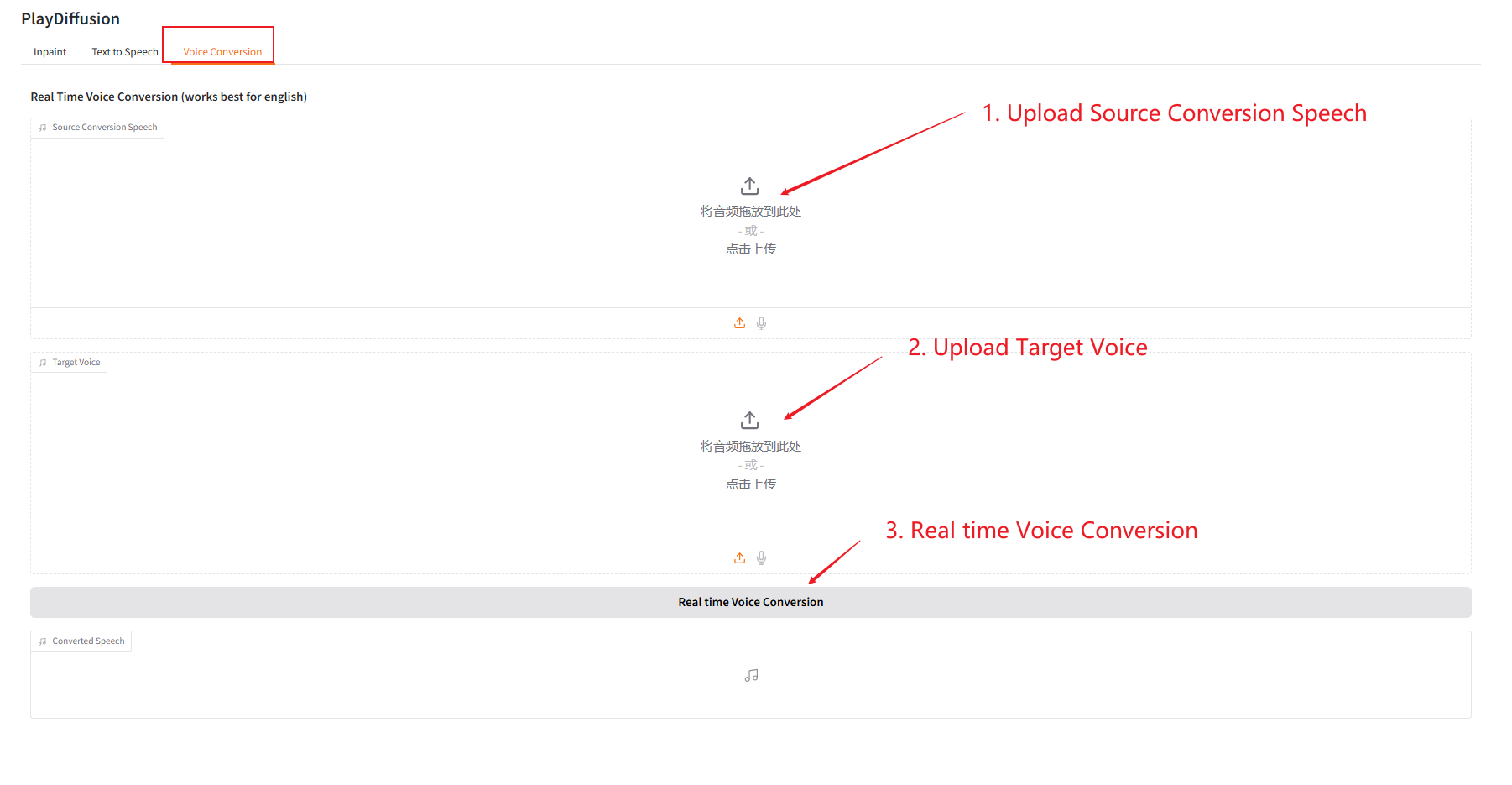
3. تحويل الصوت
اضبط محتوى الصوت بشكل ديناميكي، ويمكنك استنساخ محتوى الصوت الأصلي مباشرة إلى جرس الصوت المستهدف.
- قم بتحميل الصوت الأصلي، ثم قم بتحميل الصوت المستهدف.
- ثم انقر فوق "تحويل الصوت في الوقت الفعلي" لتوليد محتوى الصوت الأصلي للنغمة المستهدفة مباشرةً.
4. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓

بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.