Command Palette
Search for a command to run...
نشر vLLM+Open WebUI QwenLong-L1-32B
التاريخ
الحجم
96.23 MB
الوسوم
الترخيص
Apache 2.0
رابط الورقة البحثية
1. مقدمة البرنامج التعليمي

QwenLong-L1-32B هو نموذج استدلال للنصوص الطويلة، تم إصداره في 26 مايو 2025 من قِبل مختبر تونغي ومجموعة علي بابا. يُعد هذا النموذج الأول من نوعه الذي يُدرَّب باستخدام التعلّم المعزز، ويركز على حل مشكلات مثل ضعف الذاكرة والتناقضات المنطقية التي تواجهها النماذج التقليدية واسعة النطاق عند التعامل مع سياقات طويلة للغاية (مثل 120,000 كلمة). يتجاوز هذا النموذج قيود السياق التي تعاني منها النماذج التقليدية واسعة النطاق، موفرًا حلاً منخفض التكلفة وعالي الأداء لسيناريوهات تتطلب دقة عالية، مثل مجالات التمويل والقانون. تتوفر أوراق بحثية ذات صلة. QwenLong-L1: نحو نماذج استدلالية كبيرة ذات سياق طويل مع التعلم التعزيزي .
يستخدم هذا البرنامج التعليمي موارد RTX A6000 ثنائية البطاقة.
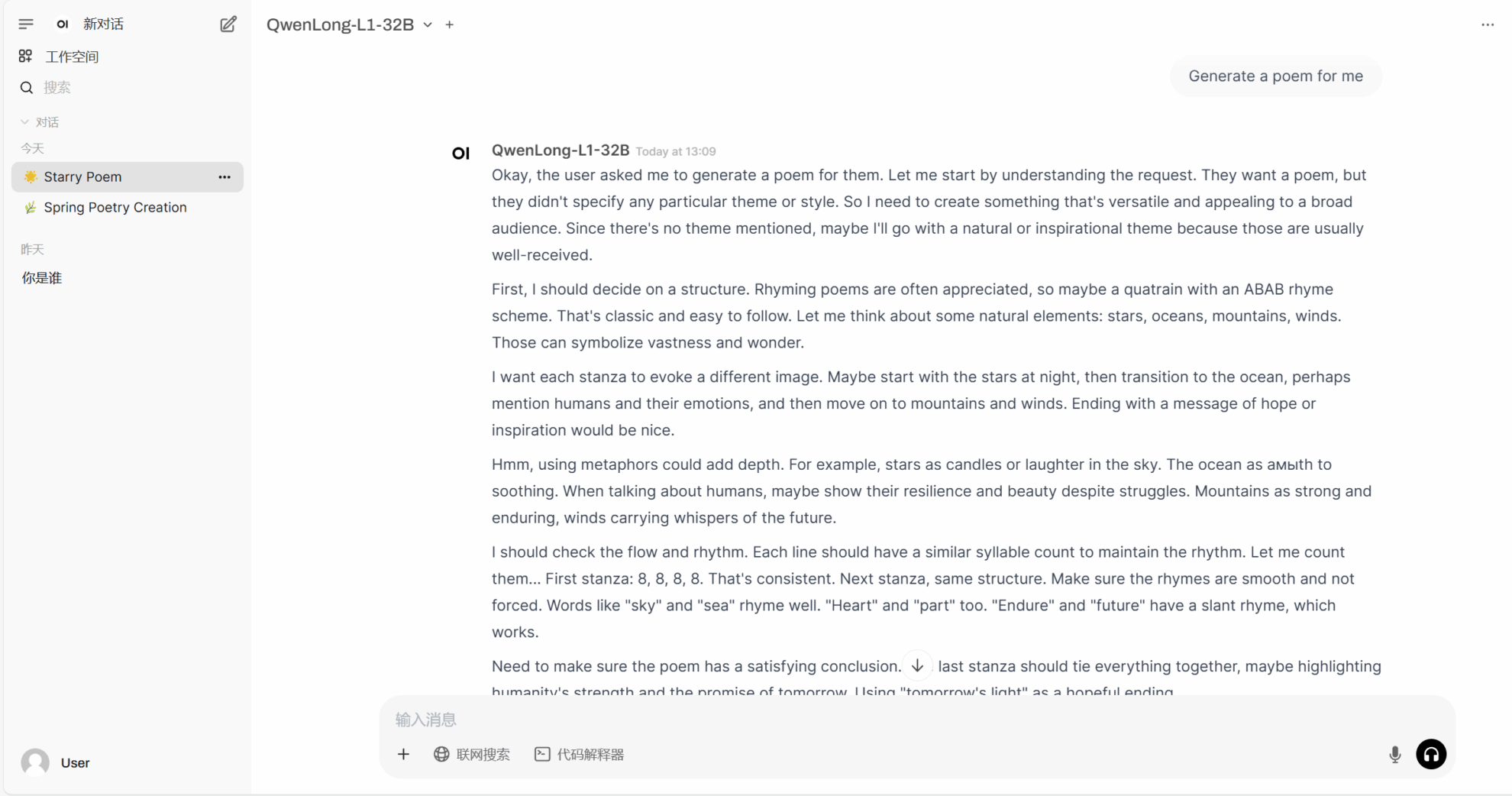
2. أمثلة المشاريع
3. خطوات التشغيل
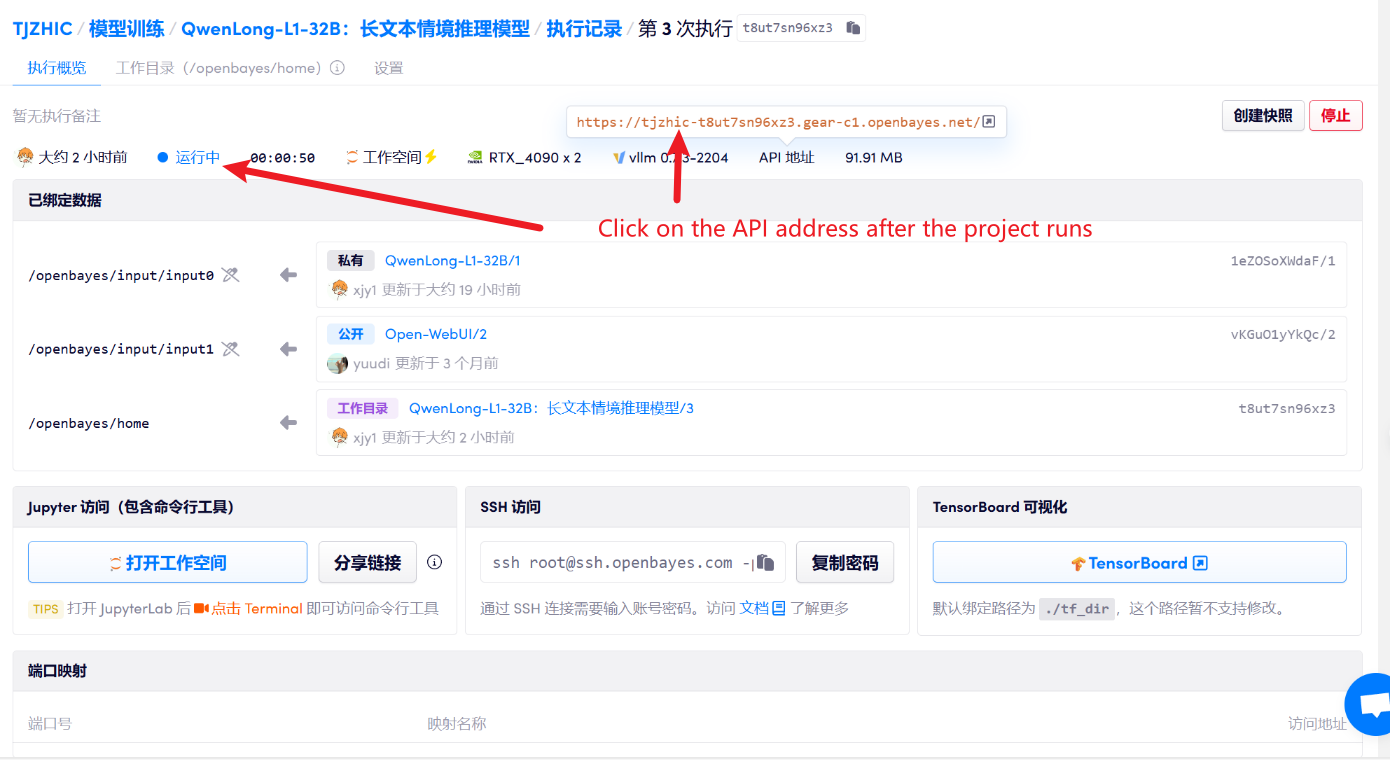
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
إذا لم يتم عرض "النموذج"، فهذا يعني أنه يتم تهيئة النموذج. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 2-3 دقائق وتحديث الصفحة.
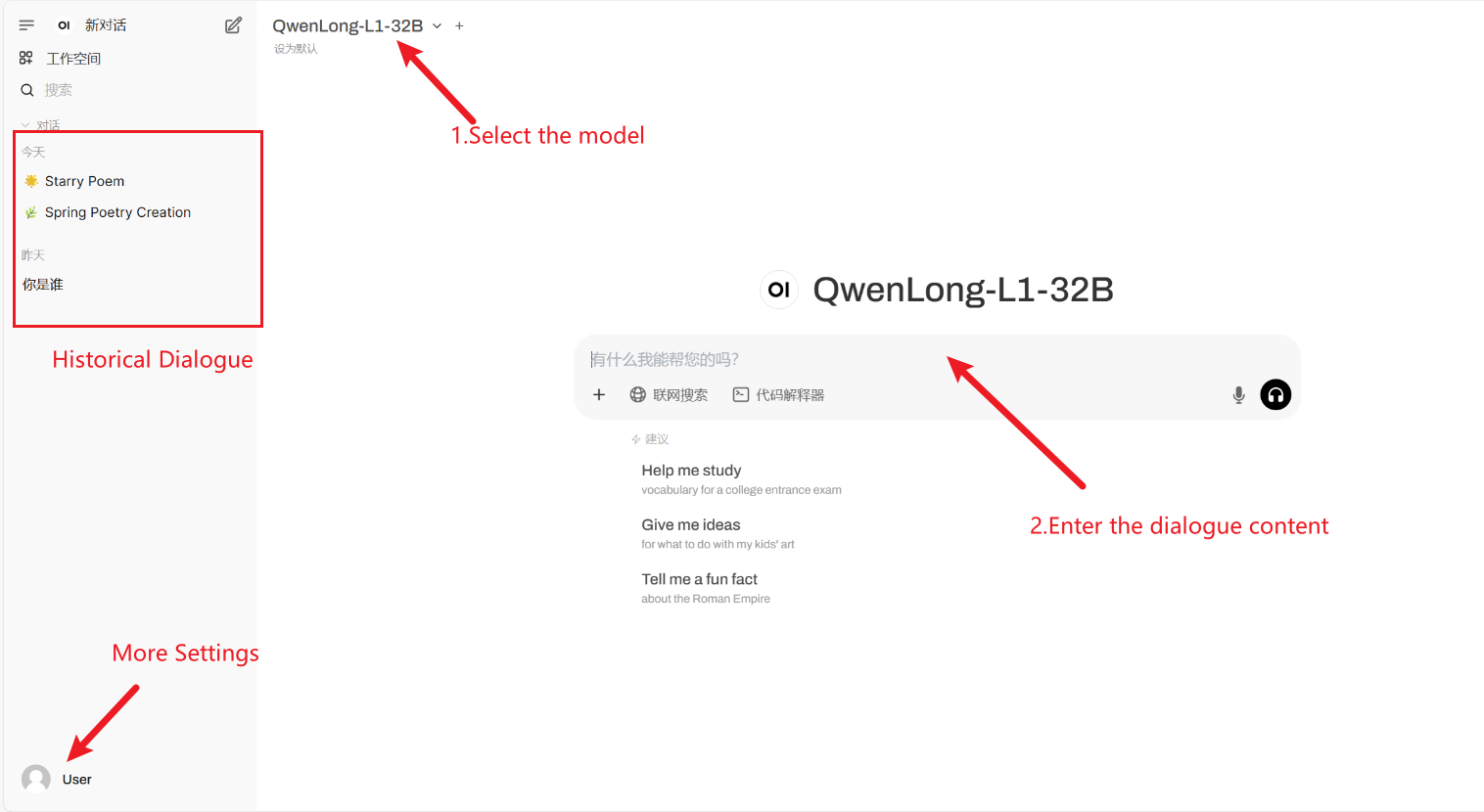
2. بعد الدخول إلى صفحة الويب، يمكنك بدء محادثة مع النموذج
كيفية الاستخدام
4. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓

معلومات الاستشهاد
شكرًا لمستخدم Github xxxجججج1 نشر هذا البرنامج التعليمي. معلومات الاستشهاد لهذا المشروع هي كما يلي:
@article{wan2025qwenlongl1,
title={QwenLong-L1: : Towards Long-Context Large Reasoning Models with Reinforcement Learning},
author={Fanqi Wan, Weizhou Shen, Shengyi Liao, Yingcheng Shi, Chenliang Li, Ziyi Yang, Ji Zhang, Fei Huang, Jingren Zhou, Ming Yan},
journal={arXiv preprint arXiv:2505.17667},
year={2025}
}بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.