Command Palette
Search for a command to run...
عرض توضيحي لنموذج الرسم البياني لمطابقة تدفق Flow-GRPO
التاريخ
الحجم
1.88 GB
الترخيص
MIT
GitHub
رابط الورقة البحثية
1. مقدمة البرنامج التعليمي

يُعدّ Flow-GRPO نموذجًا لمطابقة التدفقات، أُطلق في 13 مايو 2025 من قِبل مختبر الوسائط المتعددة التابع للجامعة الصينية في هونغ كونغ، وجامعة تسينغهوا، وفريق كوايشو كيلينغ. يدمج هذا النموذج بشكل مبتكر إطار عمل للتعلم المعزز عبر الإنترنت مع نظرية مطابقة التدفقات، محققًا بذلك إنجازًا بارزًا في معيار GenEval 2025: إذ قفزت دقة التوليد المُجمّعة لنموذج SD 3.5 Medium من 63% إلى 95%، وتجاوز مقياس تقييم جودة التوليد GPT-40 لأول مرة. تتوفر أوراق بحثية ذات صلة. Flow-GRPO: تدريب نماذج مطابقة التدفق عبر التعلم التعزيزي عبر الإنترنت .
يستخدم هذا البرنامج التعليمي بطاقة RTX 4090 واحدة كمورد، كما تدعم مطالبات إنشاء الصورة اللغة الإنجليزية فقط.
2. أمثلة المشاريع
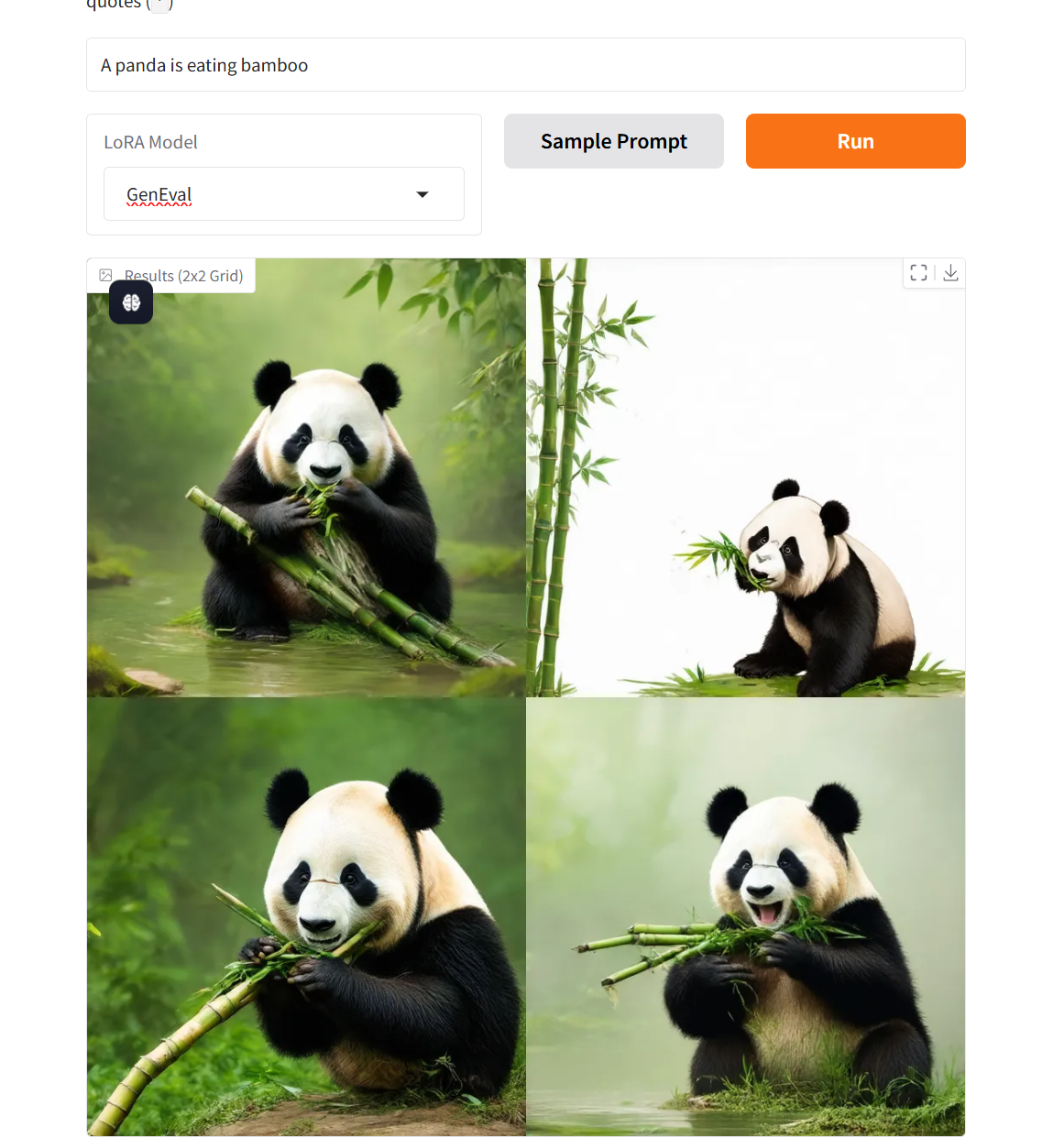
3. خطوات التشغيل
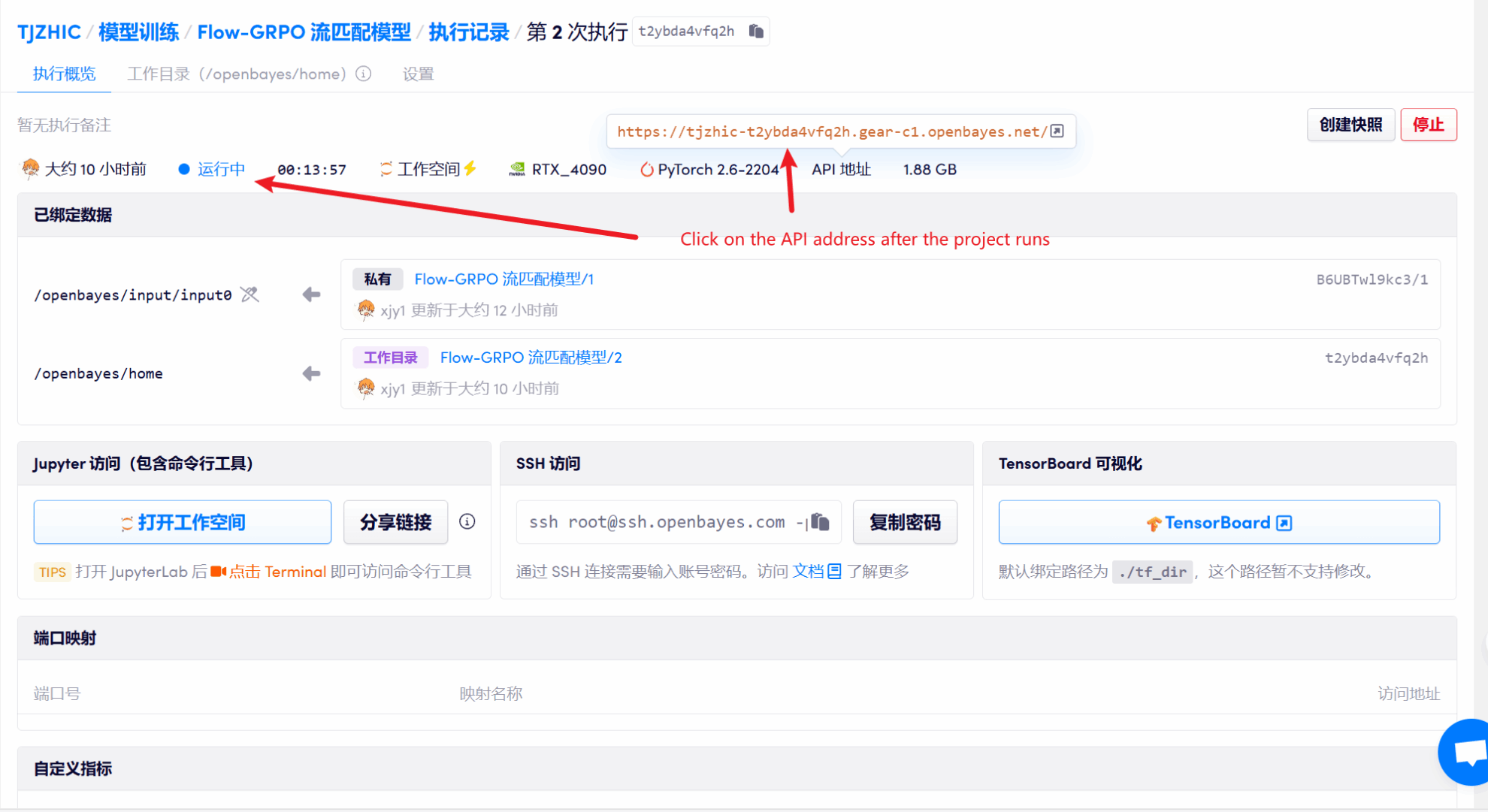
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 1-2 دقيقة وتحديث الصفحة.
2. بعد الدخول إلى صفحة الويب، يمكنك بدء محادثة مع النموذج
كيفية الاستخدام
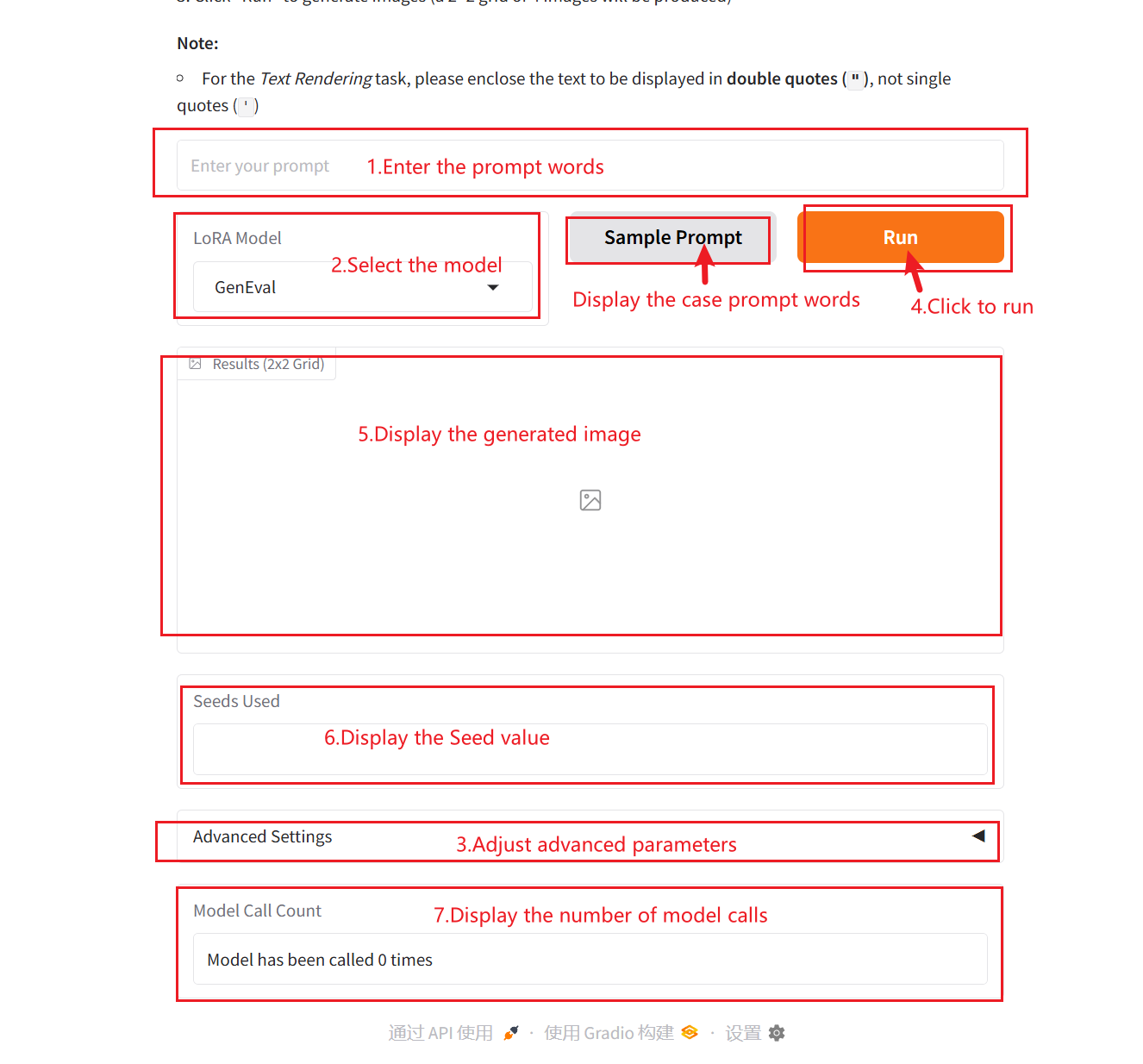
وصف المعلمة:
- نموذج LoRA:
- لا أحد: يتم استدعاء النموذج الأساسي بشكل أصلي ولا يتم تقديم استراتيجية تحسين.
- تقييم عام: تم إنشاء نظام تقييم سداسي الأبعاد لدعم إنشاء السيناريوهات المعقدة والتحقق منها.
- تقديم النص: يتيح التصور الدقيق للنص إمكانية رسم خرائط دقيقة للمحتوى الرسومي والنصي.
- محاذاة التفضيلات البشرية: المحاذاة الكمية للتفضيلات الجمالية وإطار تقييم PickScore المتكامل
- البذور البادئة: بذرة رقم عشوائي، تستخدم للتحكم في عشوائية عملية التوليد. يمكن لقيمة البذرة نفسها أن تنتج نفس النتائج (بشرط أن تكون المعلمات الأخرى هي نفسها)، وهو أمر مهم للغاية في إعادة إنتاج النتائج.
- عرض: يتم استخدامه للتحكم في عرض الصورة المولدة.
- ارتفاع: يتم استخدامه للتحكم في ارتفاع الصورة المولدة.
- مقياس التوجيه: يتم استخدامه للتحكم في الدرجة التي تؤثر بها المدخلات الشرطية (مثل النص أو الصور) في النماذج التوليدية على النتائج المولدة. ستعمل قيم التوجيه الأعلى على جعل النتائج المولدة تتطابق بشكل أوثق مع شروط الإدخال، بينما ستحتفظ القيم المنخفضة بمزيد من العشوائية.
- عدد خطوات الاستدلال: يمثل عدد تكرارات النموذج أو عدد الخطوات في عملية الاستدلال، ويمثل عدد خطوات التحسين التي يستخدمها النموذج لتوليد النتيجة. يؤدي عدد أكبر من الخطوات عادةً إلى إنتاج نتائج أكثر دقة، ولكن قد يؤدي إلى زيادة وقت الحساب.
4. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓

معلومات الاستشهاد
شكرًا لمستخدم Github xxxجججج1 نشر هذا البرنامج التعليمي. معلومات الاستشهاد لهذا المشروع هي كما يلي:
@misc{liu2025flowgrpo,
title={Flow-GRPO: Training Flow Matching Models via Online RL},
author={Jie Liu and Gongye Liu and Jiajun Liang and Yangguang Li and Jiaheng Liu and Xintao Wang and Pengfei Wan and Di Zhang and Wanli Ouyang},
year={2025},
eprint={2505.05470},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.05470},
}بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.