Command Palette
Search for a command to run...
نشر VideoLLaMA3-7B بنقرة واحدة
التاريخ
الحجم
2.09 GB
الوسوم
الترخيص
Apache 2.0
GitHub
رابط الورقة البحثية
1. مقدمة البرنامج التعليمي


يستخدم هذا البرنامج التعليمي مورد حوسبة RTX 4090 واحدًا، وينشر نموذج VideoLLaMA3-7B-Image، ويقدم مثالين لفهم الفيديو والصور. بالإضافة إلى ذلك، يوفر البرنامج أربعة دروس تعليمية في نصوص دفتر الملاحظات حول "فهم صورة واحدة"، و"فهم صور متعددة"، و"التعبير عن المرجع البصري وتحديد موقعه"، و"فهم الفيديو".
يُعدّ VideoLLaMA3 نموذجًا أساسيًا متعدد الوسائط، مفتوح المصدر، أطلقه فريق معالجة اللغات الطبيعية التابع لأكاديمية Alibaba DAMO (DAMO-NLP-SG) في فبراير 2025، ويركز على مهام فهم الصور والفيديوهات. بفضل بنيته التي تتمحور حول الرؤية وهندسة البيانات عالية الجودة، يُحسّن النموذج بشكلٍ ملحوظ دقة وكفاءة فهم الفيديوهات. يُلبي إصداره الخفيف (2B) احتياجات النشر على الحافة، بينما يُقدّم نموذج 7B أداءً متميزًا للتطبيقات البحثية. يُحقق نموذج 7B أداءً متطورًا في ثلاث مهام رئيسية: فهم الفيديوهات بشكل عام، والاستدلال الزمني، وتحليل الفيديوهات الطويلة. تتوفر أوراق بحثية ذات صلة. VideoLLaMA 3: نماذج أساسية متعددة الوسائط لفهم الصور والفيديو .
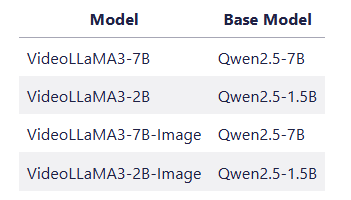
👉يوفر المشروع 4 نماذج من النماذج:
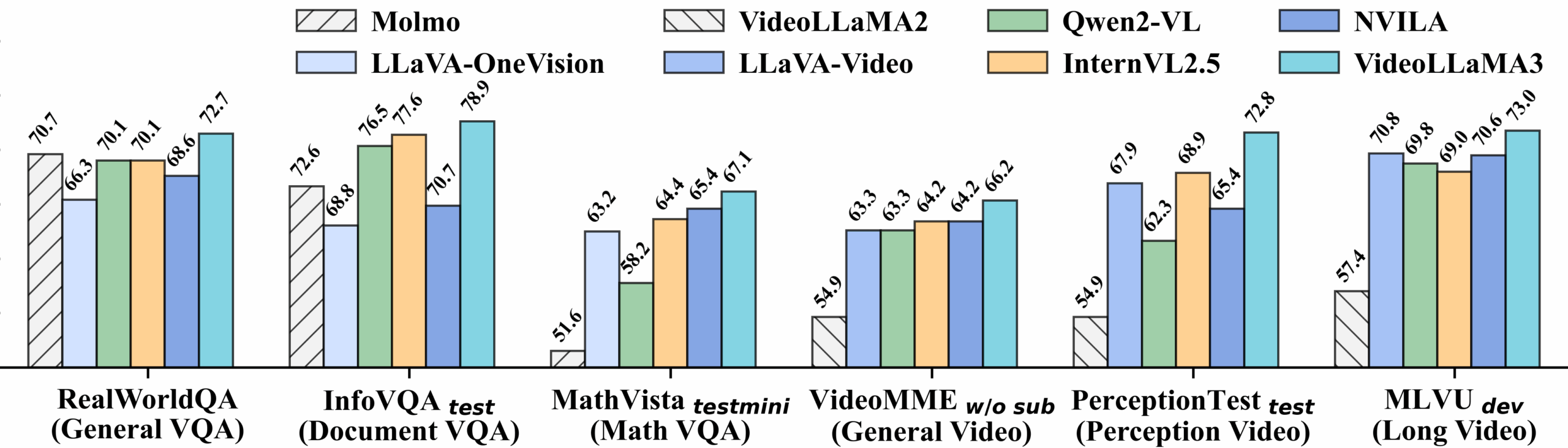
فيديو معايير الأداء التفصيلية:
عرض الأداء التفصيلي لمعايير الصورة:
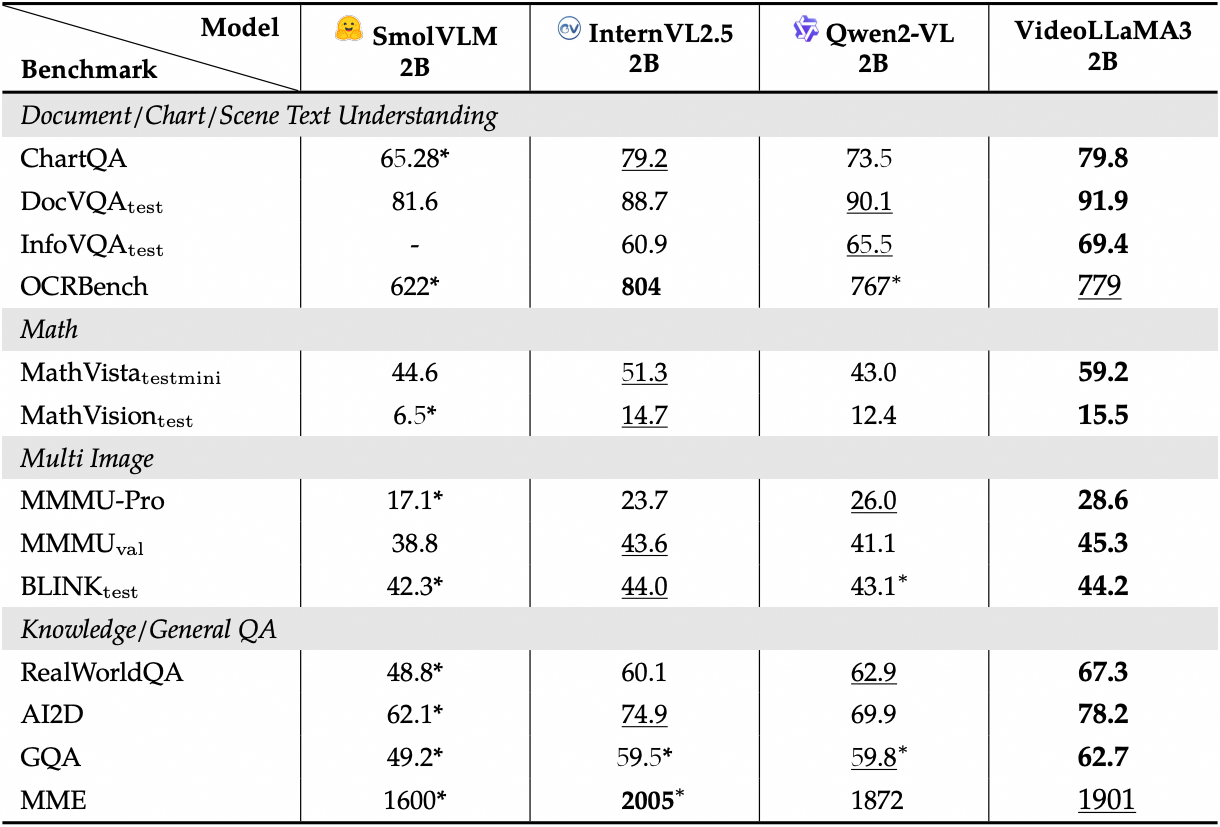
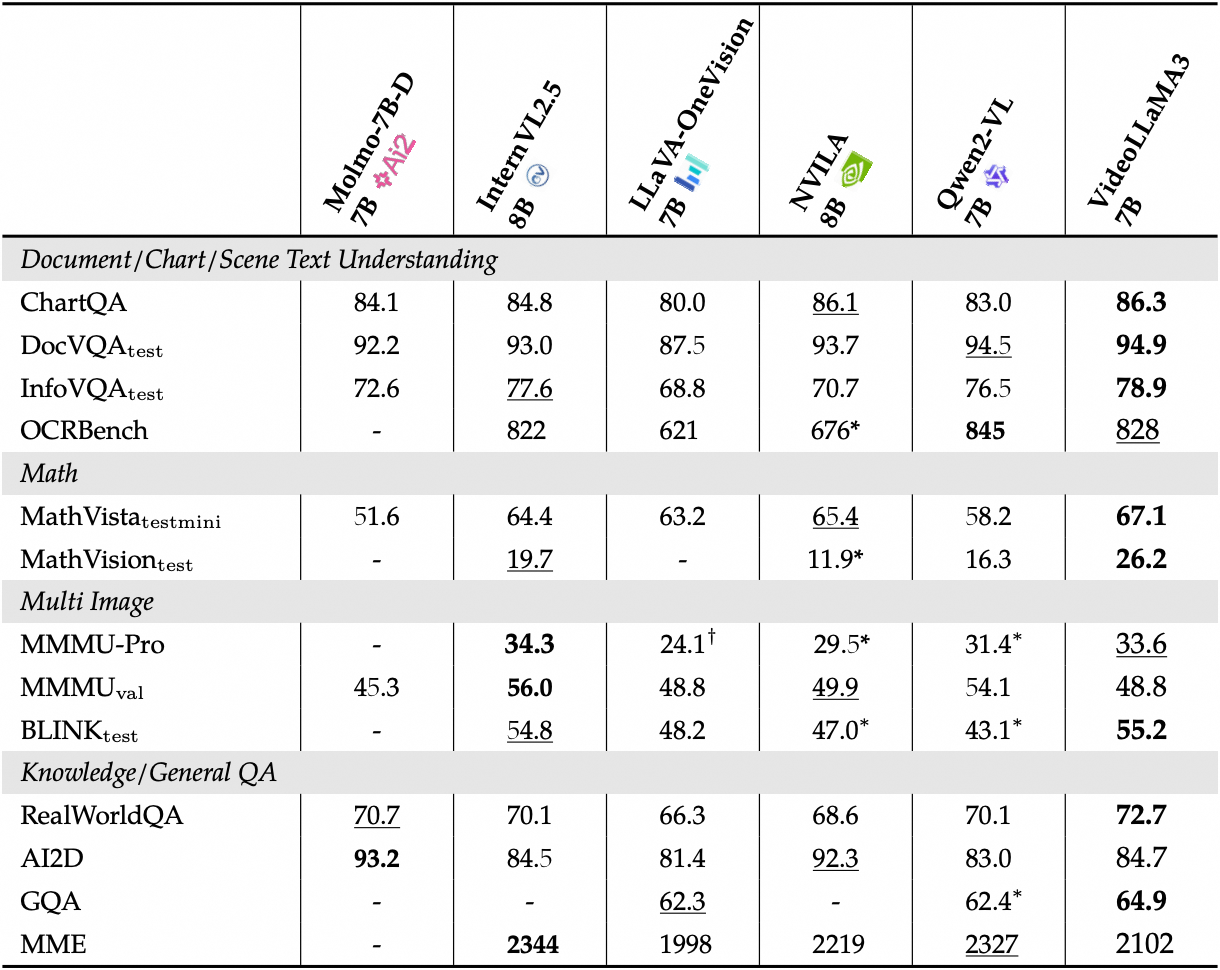
2. خطوات التشغيل
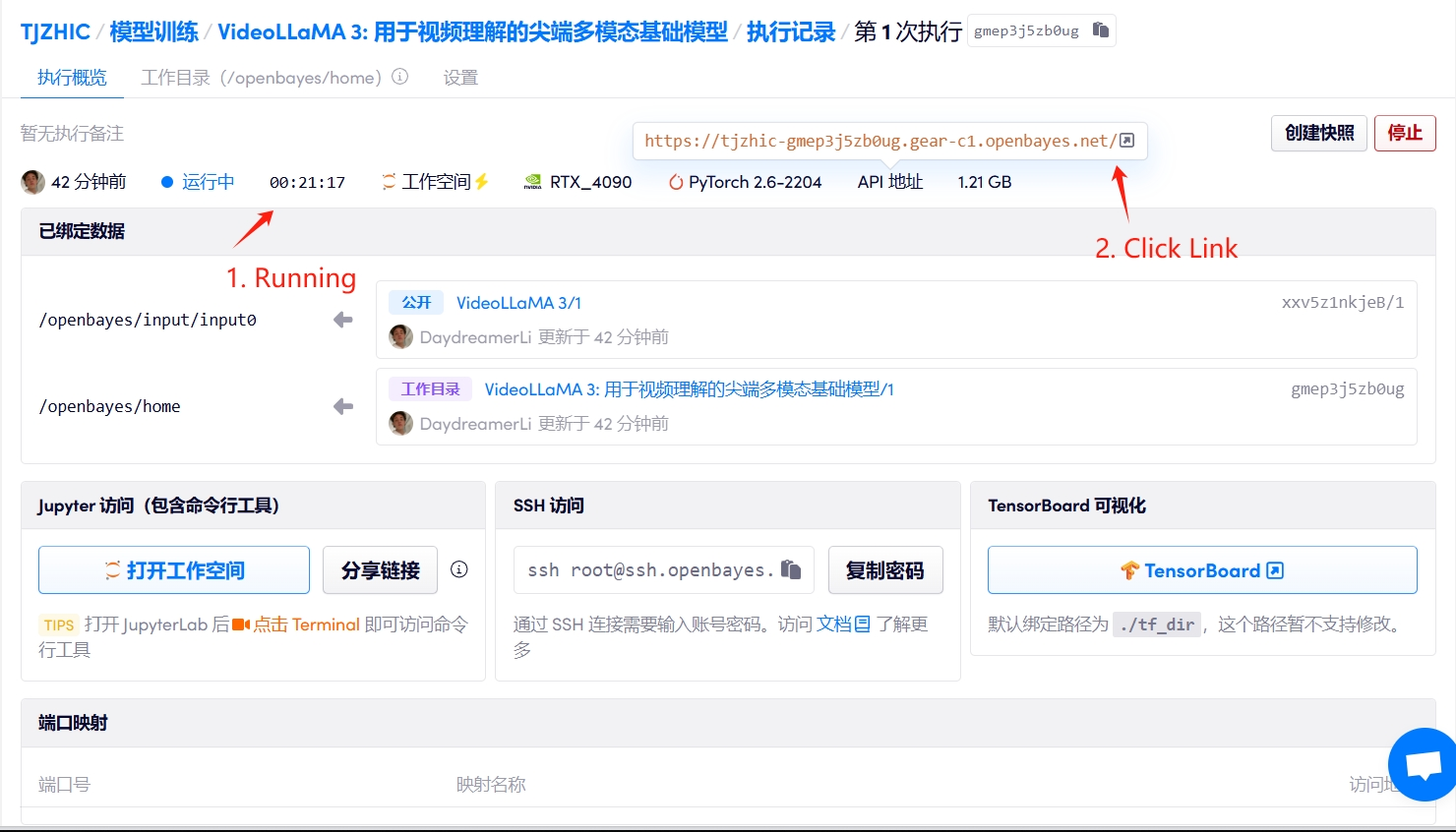
1. ابدأ تشغيل الحاوية
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 2-3 دقائق وتحديث الصفحة.
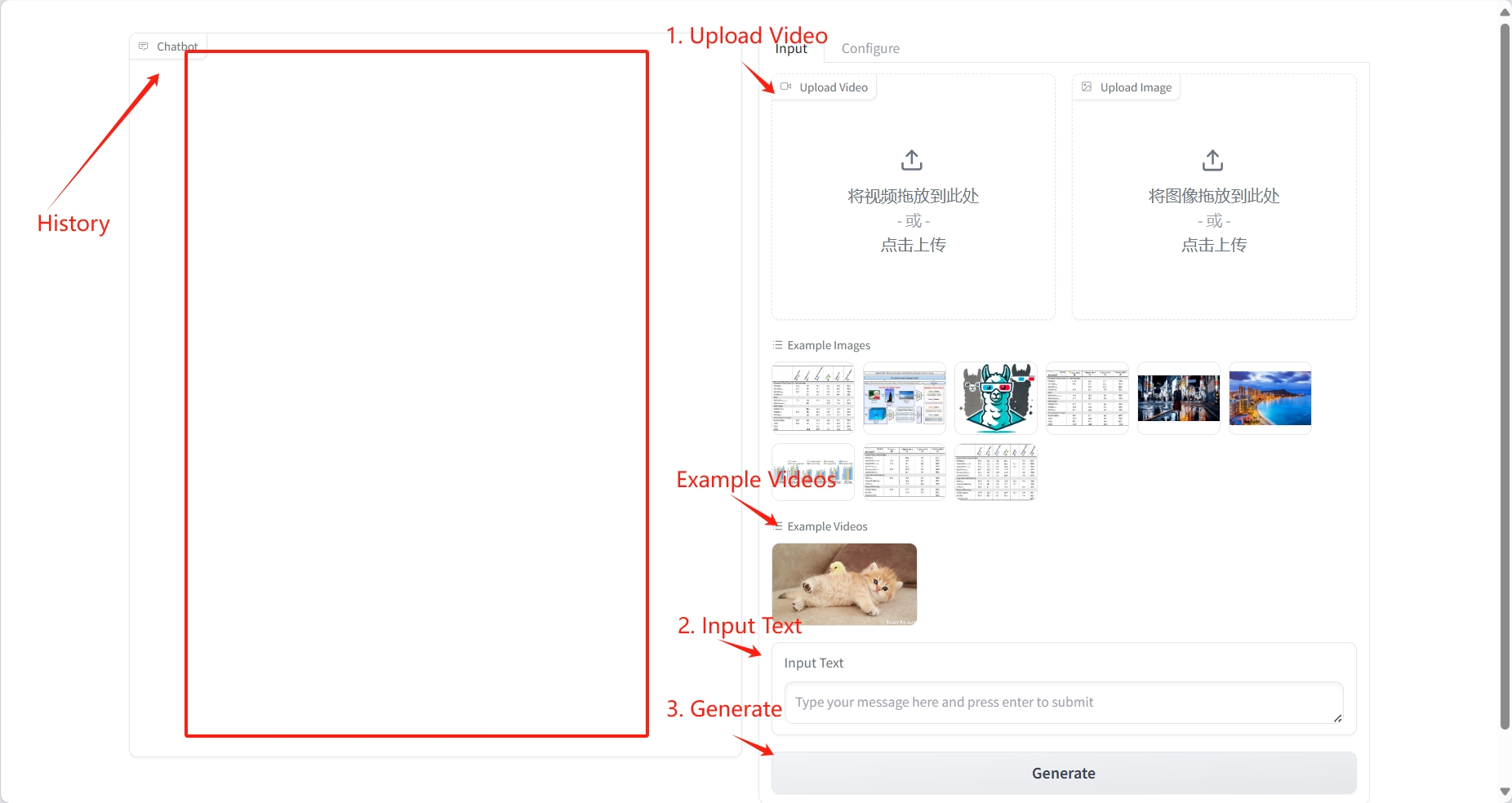
2. خطوات الاستخدام
فهم الفيديو
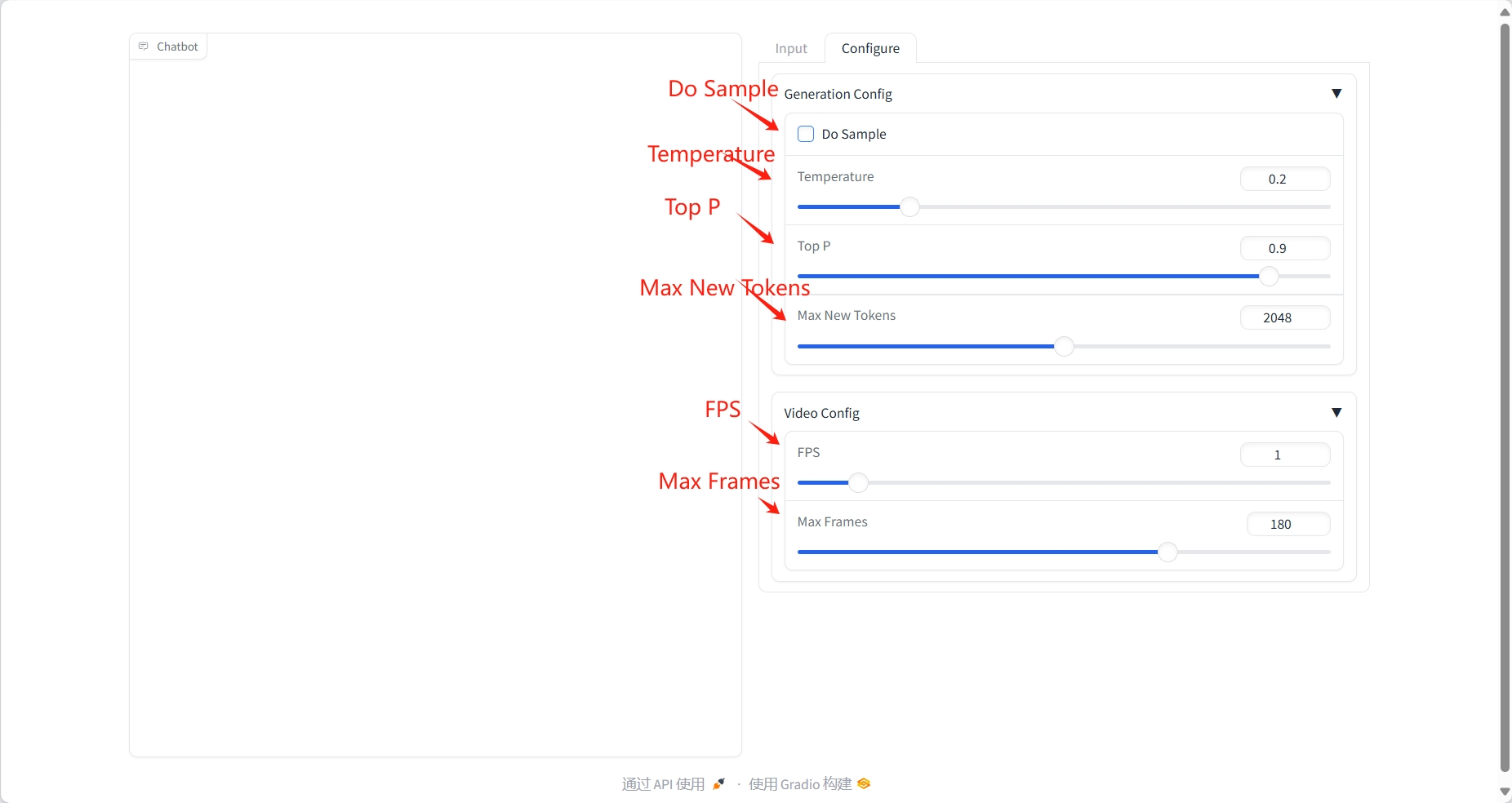
نتيجة
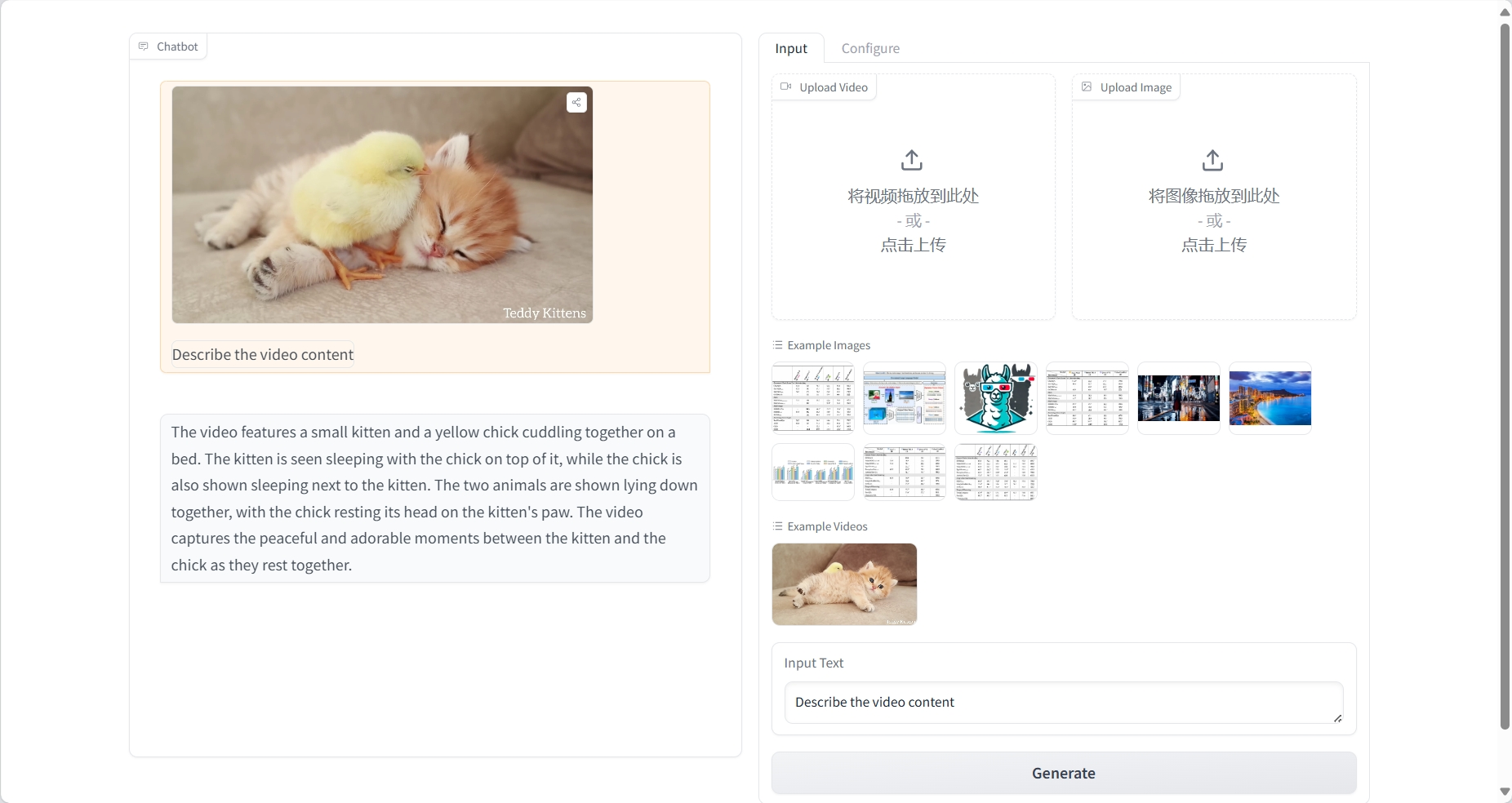
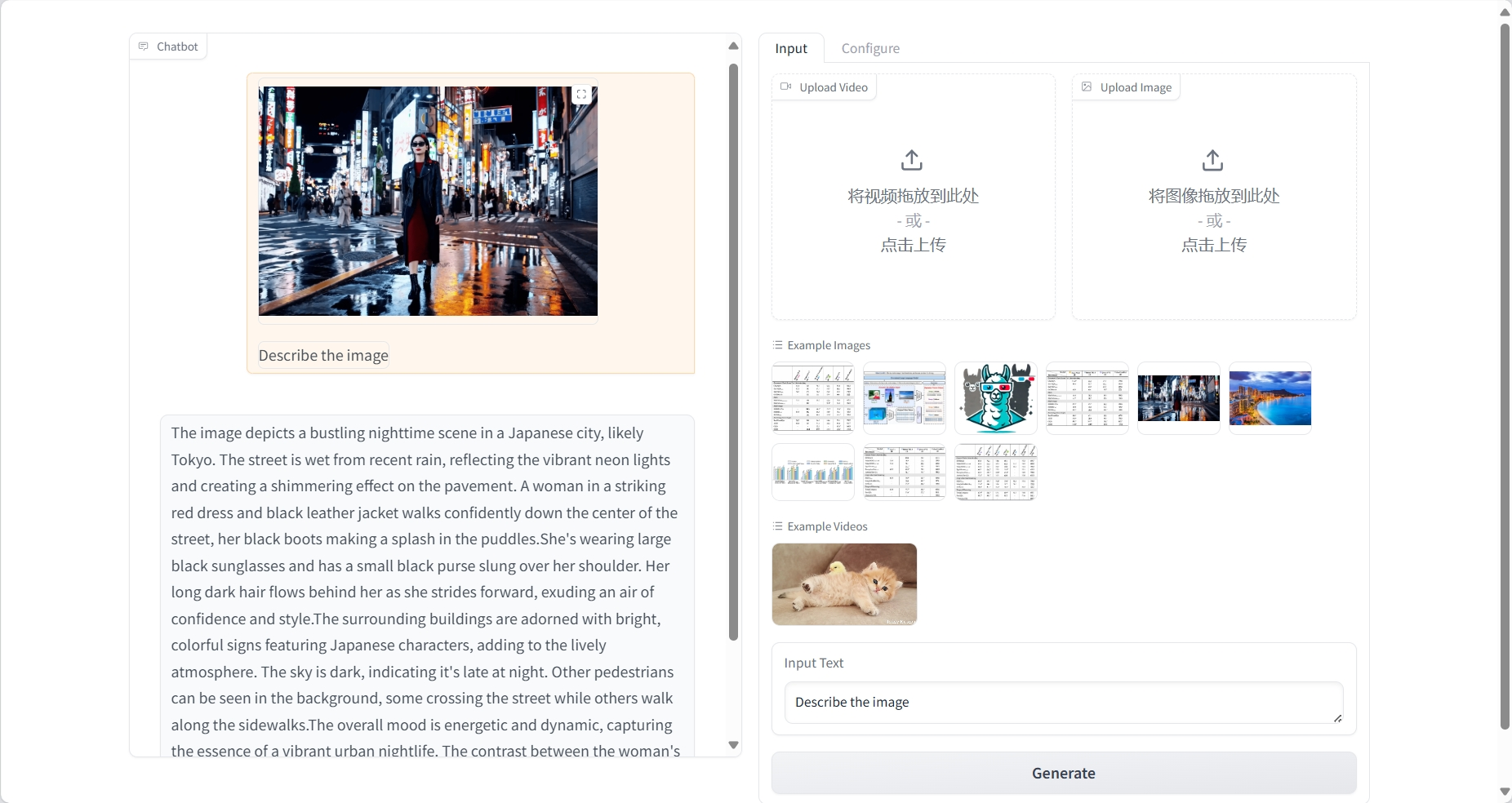
فهم الصورة
نتيجة
3. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓

معلومات الاستشهاد
معلومات الاستشهاد لهذا المشروع هي كما يلي:
@article{damonlpsg2025videollama3,
title={VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding},
author={Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, Deli Zhao},
journal={arXiv preprint arXiv:2501.13106},
year={2025},
url = {https://arxiv.org/abs/2501.13106}
}
@article{damonlpsg2024videollama2,
title={VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs},
author={Cheng, Zesen and Leng, Sicong and Zhang, Hang and Xin, Yifei and Li, Xin and Chen, Guanzheng and Zhu, Yongxin and Zhang, Wenqi and Luo, Ziyang and Zhao, Deli and Bing, Lidong},
journal={arXiv preprint arXiv:2406.07476},
year={2024},
url = {https://arxiv.org/abs/2406.07476}
}
@article{damonlpsg2023videollama,
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
journal = {arXiv preprint arXiv:2306.02858},
year = {2023},
url = {https://arxiv.org/abs/2306.02858}
}بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.