Command Palette
Search for a command to run...
VGGT: نموذج رؤية ثلاثي الأبعاد عام
التاريخ
الحجم
967.01 MB
الترخيص
CC BY 4.0
GitHub
رابط الورقة البحثية
1. مقدمة البرنامج التعليمي

شبكة VGGT العصبية ذات التغذية الأمامية، التي أطلقها فريق Meta AI ومجموعة الهندسة البصرية (VGG) بجامعة أكسفورد في 28 مارس 2025، قادرة على استنتاج جميع الخصائص ثلاثية الأبعاد الرئيسية للمشهد مباشرةً من مشهد واحد أو عدة مشاهد أو حتى مئات المشاهد في غضون ثوانٍ. تشمل هذه الخصائص معلمات الكاميرا الخارجية والداخلية، وخرائط النقاط، وخرائط العمق، ومسارات النقاط ثلاثية الأبعاد. كما تتميز بالبساطة والكفاءة، إذ تُكمل عملية إعادة البناء في ثانية واحدة، متفوقةً حتى على الطرق البديلة التي تتطلب معالجة لاحقة باستخدام تقنيات تحسين الهندسة البصرية. للاطلاع على الورقة البحثية ذات الصلة، يُرجى مراجعة ما يلي: VGGT: محول أرضي هندسي مرئيتم قبولها في مؤتمر CVPR 2025 وفازت بجائزة أفضل ورقة بحثية في مؤتمر CVPR 2025.
يستخدم هذا البرنامج التعليمي الموارد لبطاقة RTX 4090 واحدة.
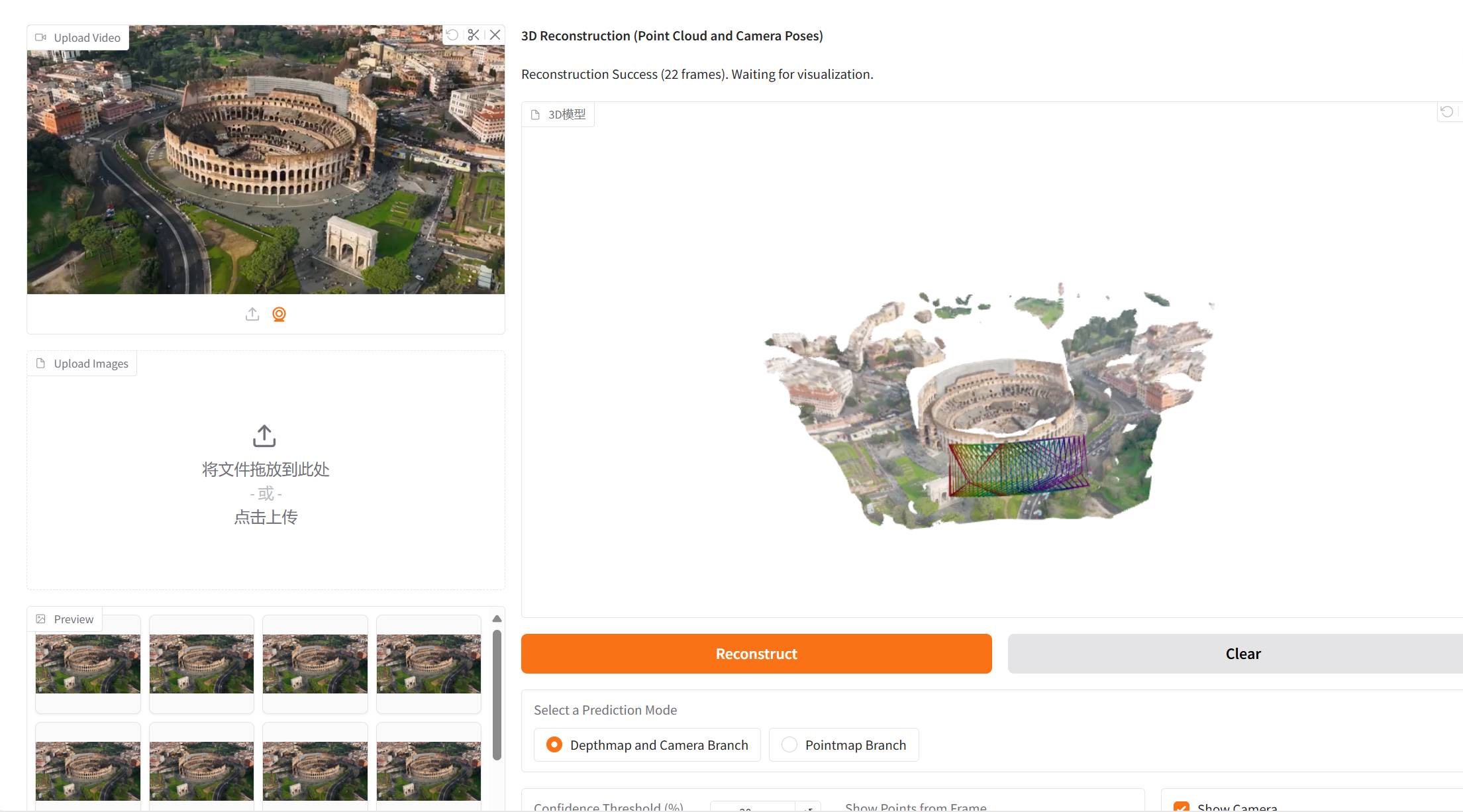
2. أمثلة المشاريع
3. خطوات التشغيل
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
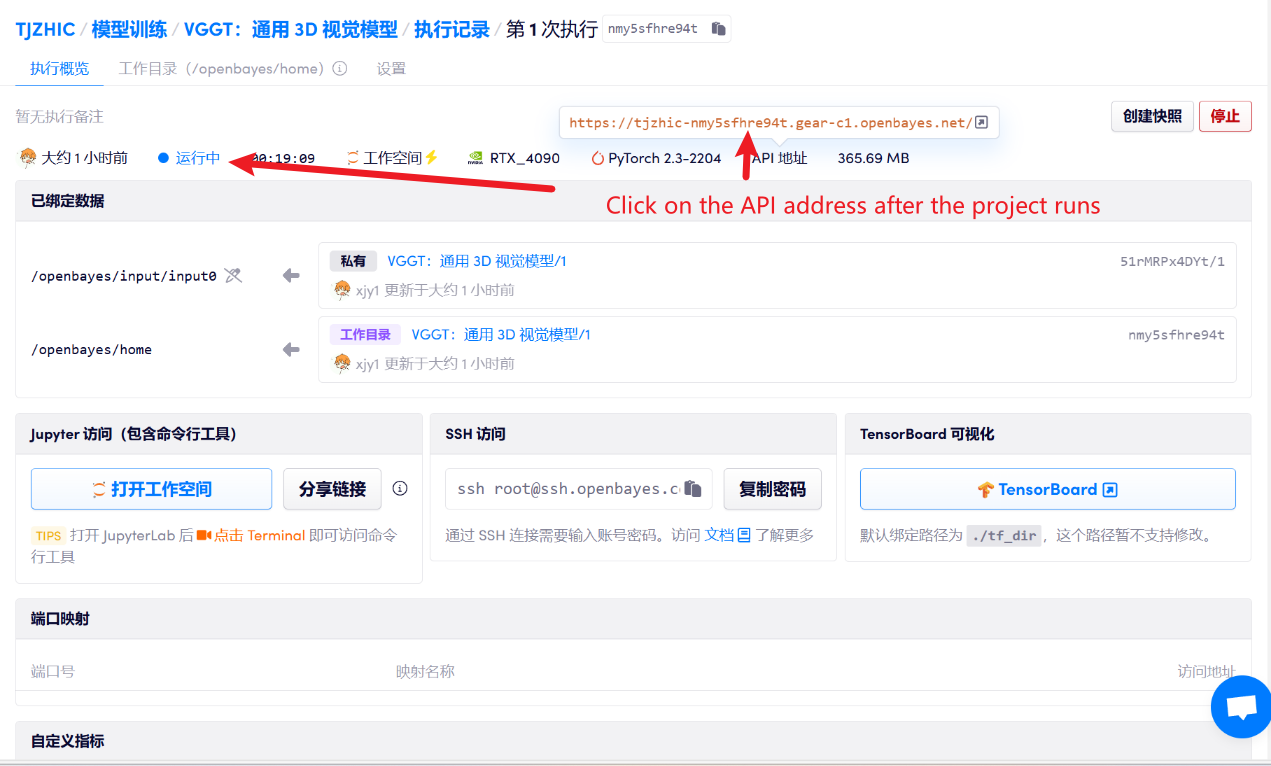
2. بمجرد دخولك إلى صفحة الويب، يمكنك استخدام النموذج
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 2-3 دقائق وتحديث الصفحة.
كيفية الاستخدام
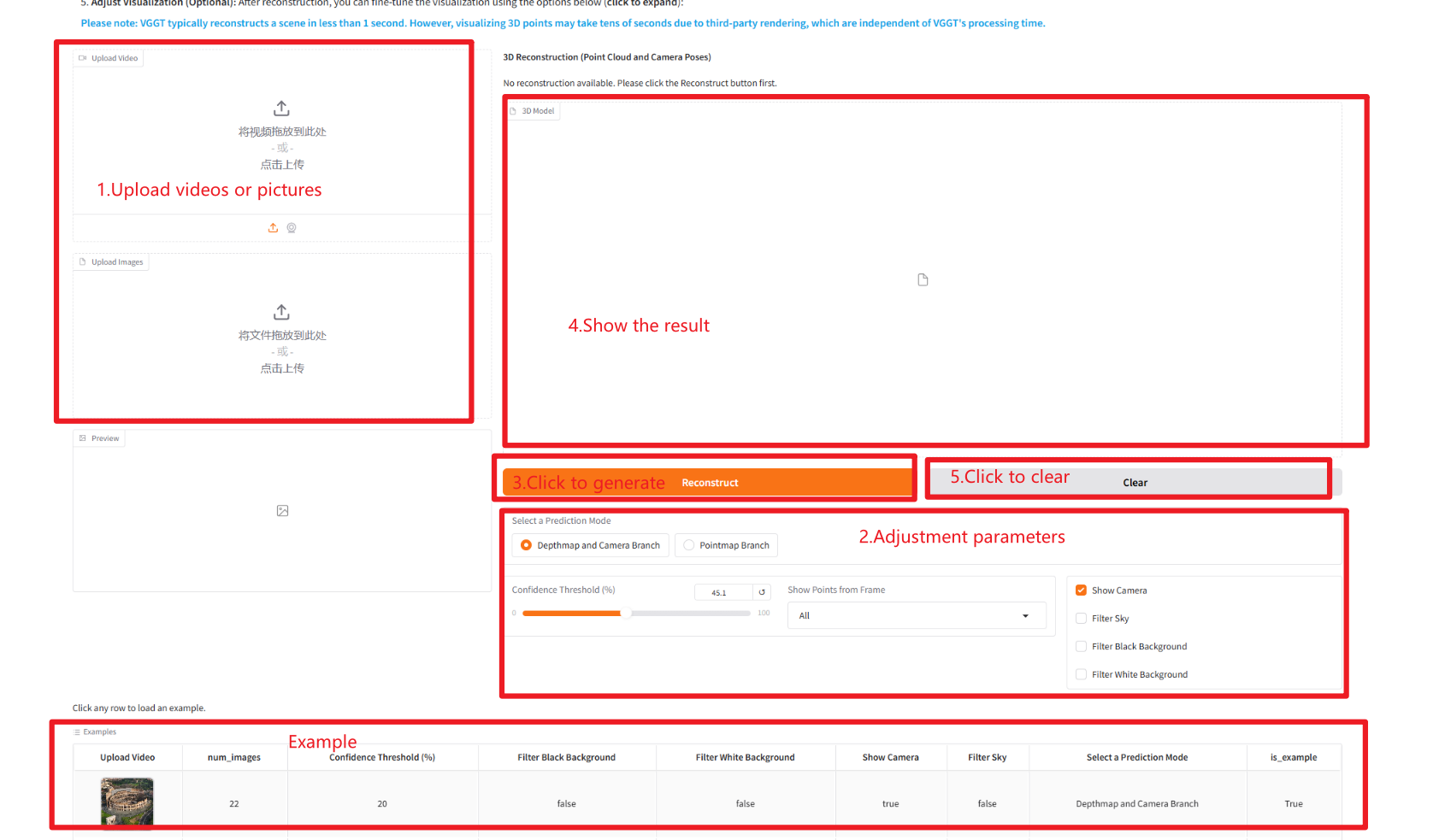
وصف المعلمة:
- حدد وضع التنبؤ:
- خريطة العمق وفرع الكاميرا: إعادة البناء باستخدام فروع خريطة العمق ووضعية الكاميرا.
- فرع خريطة النقاط: استخدم فرع سحابة النقاط مباشرة لإعادة البناء.
- عتبة الثقة: عتبة الثقة، تستخدم لتصفية النتائج ذات الثقة الأعلى في مخرجات النموذج.
- إظهار النقاط من الإطار: ما إذا كان سيتم عرض النقاط المستخرجة من الإطار المحدد.
- إظهار الكاميرا: ما إذا كان سيتم عرض موضع الكاميرا.
- تصفية السماء: ما إذا كان سيتم تصفية نقاط السماء.
- تصفية الخلفية السوداء: ما إذا كان سيتم تصفية النقاط ذات الخلفية السوداء.
- تصفية الخلفية البيضاء: ما إذا كان سيتم تصفية النقاط ذات الخلفية البيضاء.
4. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓

معلومات الاستشهاد
معلومات الاستشهاد لهذا المشروع هي كما يلي:
@inproceedings{wang2025vggt,
title={VGGT: Visual Geometry Grounded Transformer},
author={Wang, Jianyuan and Chen, Minghao and Karaev, Nikita and Vedaldi, Andrea and Rupprecht, Christian and Novotny, David},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2025}
}بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.