Command Palette
Search for a command to run...
Nanonets-OCR-s: أداة استخراج معلومات المستندات وقياس أدائها
1. مقدمة البرنامج التعليمي

Nanonets-OCR-s هو نموذج للتعرف الضوئي على الحروف (OCR) أطلقته Nanonets في 10 يونيو 2025. تركز تقنية التعرف الضوئي على الحروف التقليدية بشكل أساسي على استخراج النصوص العادية من الصور، بينما يتقدم Nanonets-OCR-s خطوةً أبعد. فهو قادر على التعرف على عناصر متعددة في المستندات، مثل الصيغ الرياضية والصور والتوقيعات والعلامات المائية ومربعات الاختيار والجداول، وتنظيمها بتنسيق Markdown منظم. تتيح له هذه القدرة أداءً ممتازًا عند معالجة المستندات المعقدة، مثل الأوراق الأكاديمية والوثائق القانونية وتقارير الأعمال. مخرجاته ليست سهلة القراءة فحسب، بل توفر أيضًا أساسًا متينًا للمعالجة الآلية اللاحقة.
يستخدم هذا البرنامج التعليمي بطاقة RTX 4090 واحدة كمورد. يحتوي هذا البرنامج التعليمي على وظيفتين: 1. استخراج المعلومات من المستندات. 2. تحويل الصور وملفات PDF إلى Markdown.
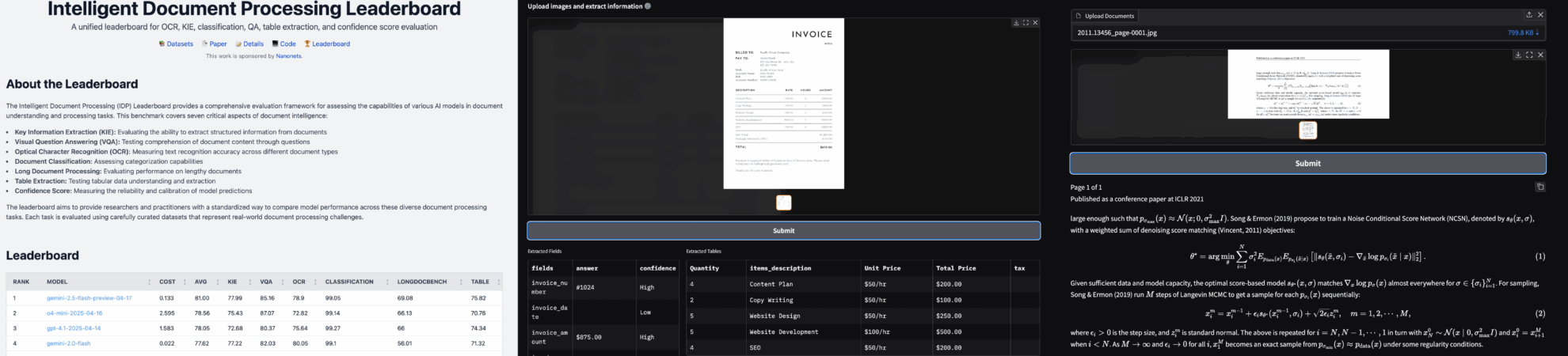
2. أمثلة المشاريع
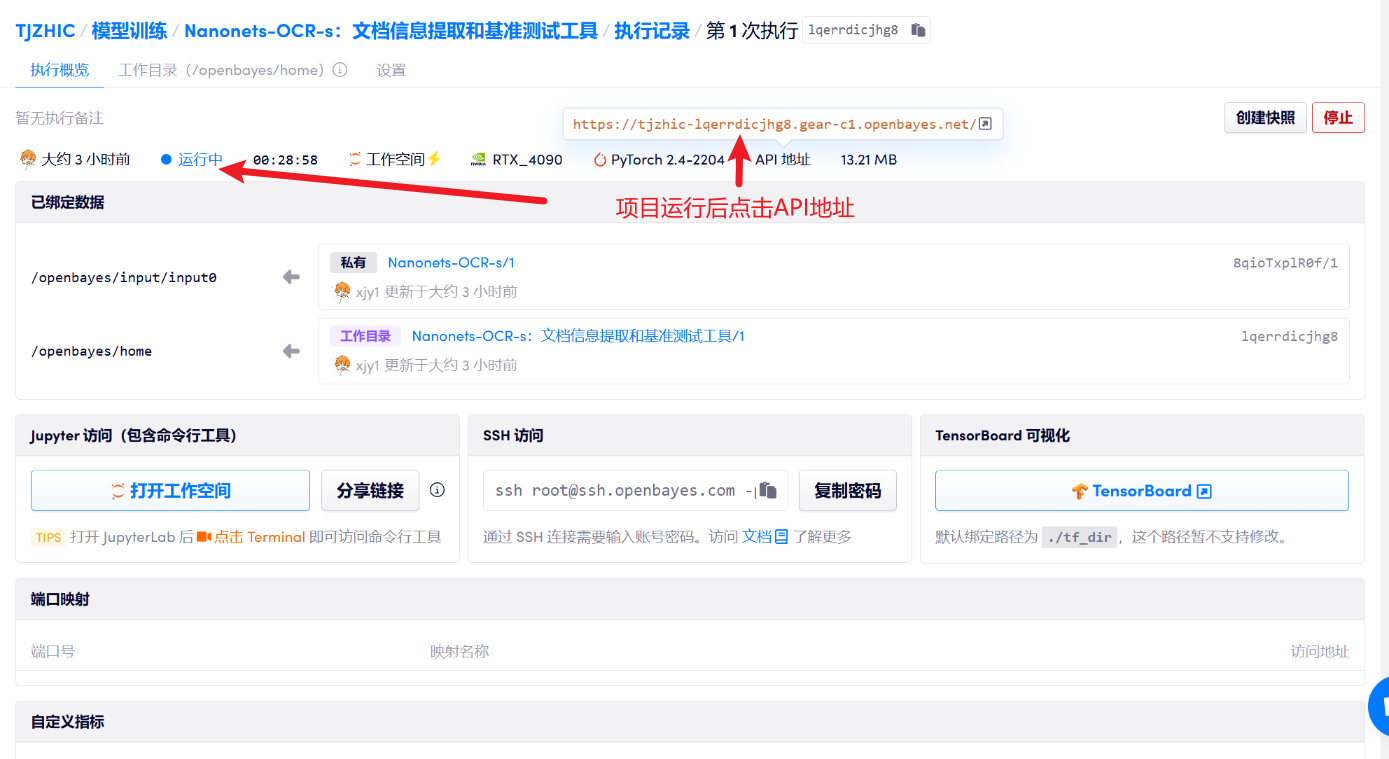
3. خطوات التشغيل
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
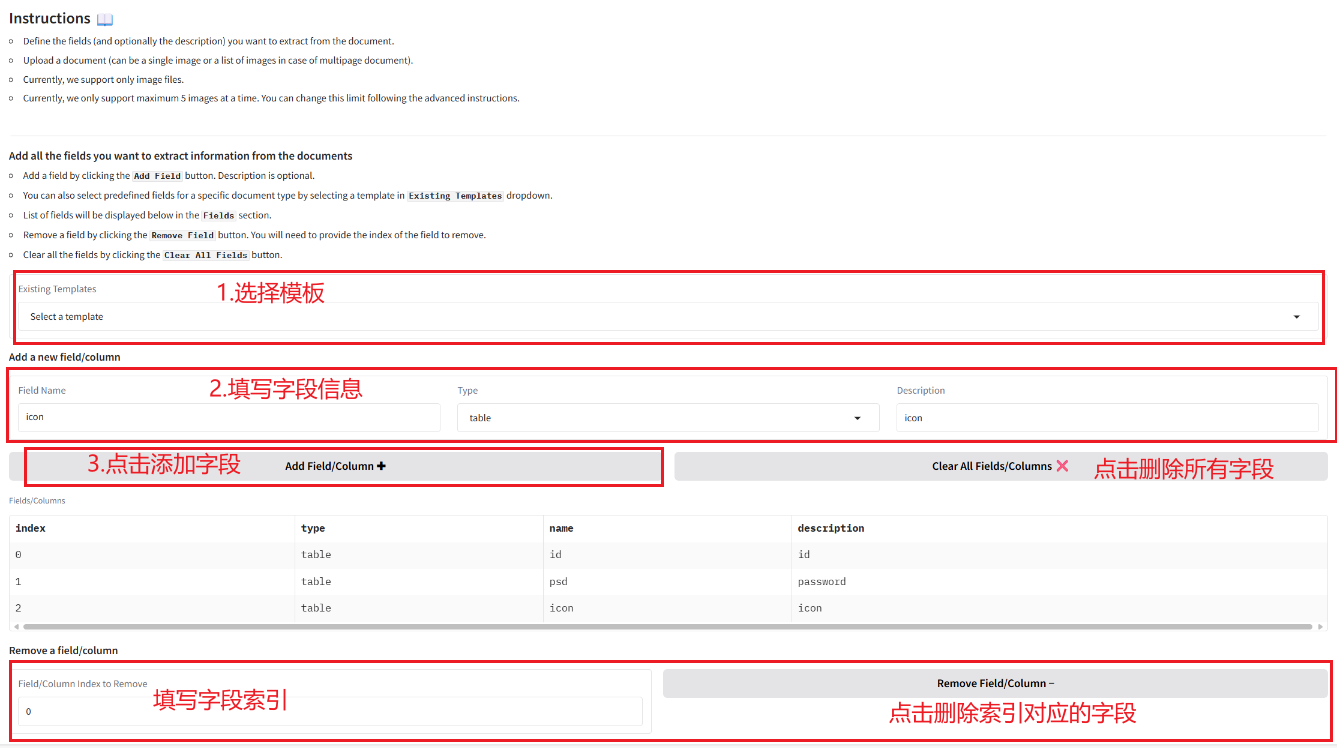
2. خطوات الاستخدام
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 1-2 دقيقة وتحديث الصفحة.
2.1 استخراج المعلومات من المستندات
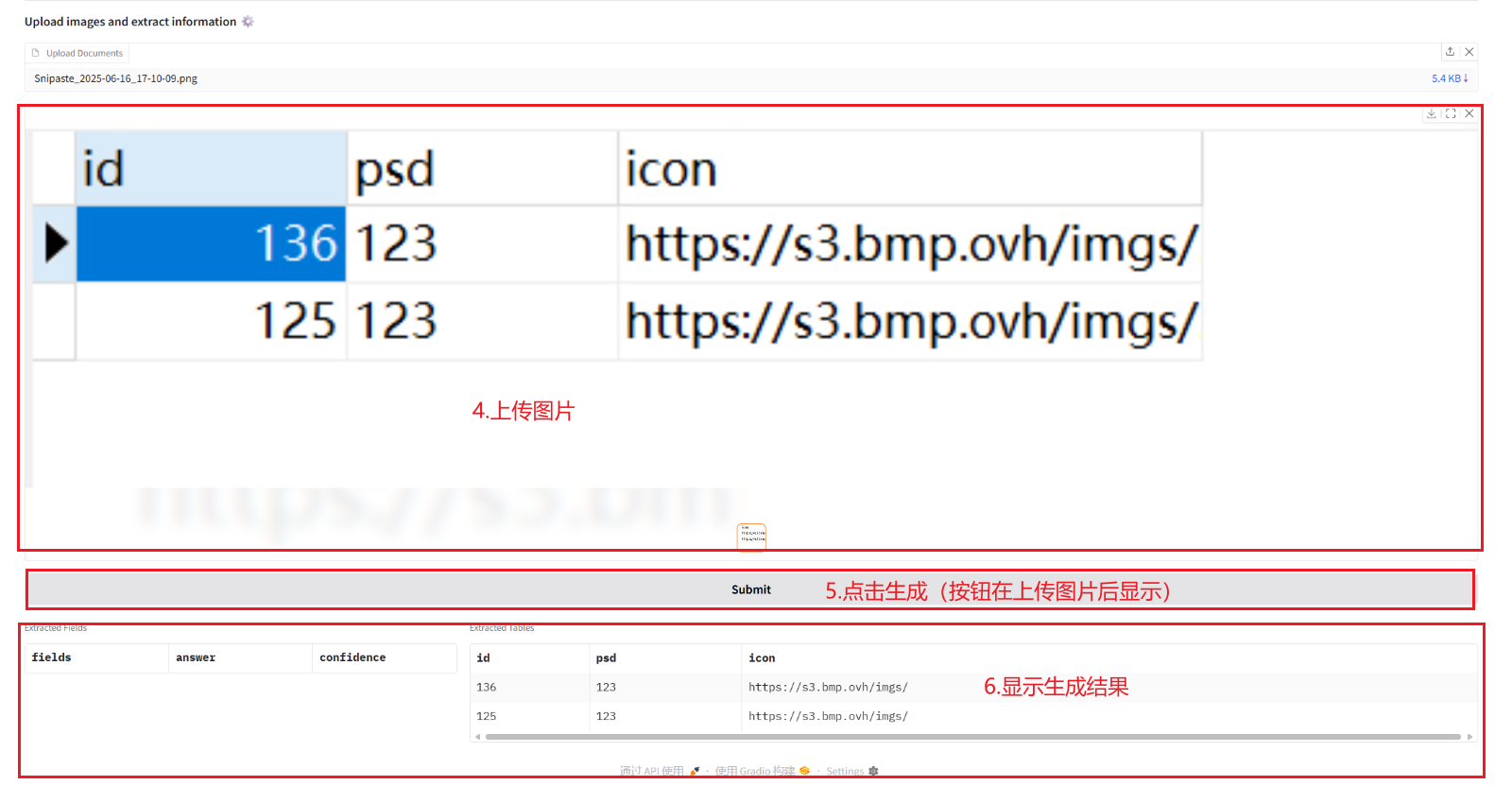
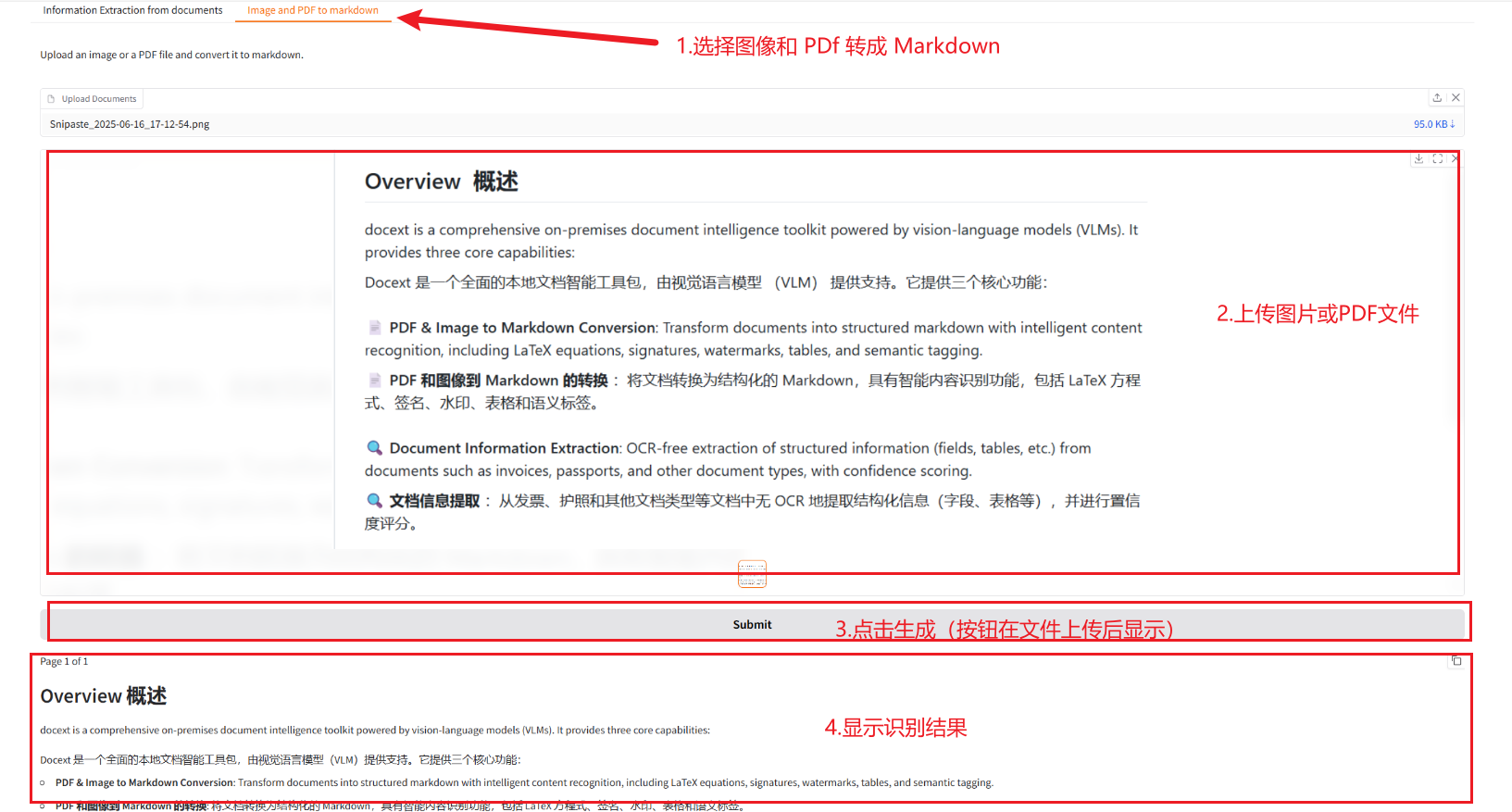
2.2 تحويل الصور وملفات PDF إلى Markdown
4. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓

بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.