Command Palette
Search for a command to run...
MonkeyOCR: تحليل المستندات استنادًا إلى النموذج الثلاثي للبنية والتعرف على العلاقة
التاريخ
الحجم
1.1 GB
الوسوم
الترخيص
Apache 2.0
GitHub
رابط الورقة البحثية
1. مقدمة البرنامج التعليمي

MonkeyOCR هو نموذج مفتوح المصدر لتحليل المستندات، تم إطلاقه في 5 يونيو 2025 من قِبل جامعة هوا تشونغ للعلوم والتكنولوجيا بالتعاون مع شركة Kingsoft Office. يُحوّل هذا النموذج محتوى المستندات غير المهيكلة بكفاءة إلى معلومات مهيكلة. وبفضل تحليله الدقيق للتخطيط، والتعرف على المحتوى، والفرز المنطقي، يُحسّن بشكل ملحوظ دقة وكفاءة تحليل المستندات. بالمقارنة مع الطرق التقليدية، يُظهر MonkeyOCR أداءً استثنائيًا في معالجة المستندات المعقدة (مثل تلك التي تحتوي على صيغ وجداول)، محققًا تحسنًا في الأداء بمعدل 5.11 TP3T، وتحسنًا بمقدار 15.01 TP3T و8.61 TP3T في تحليل الصيغ والجداول على التوالي. يتفوق النموذج في معالجة المستندات متعددة الصفحات، حيث تصل سرعته إلى 0.84 صفحة في الثانية، متجاوزًا بذلك الأدوات المماثلة الأخرى. يدعم MonkeyOCR أنواعًا مختلفة من المستندات، بما في ذلك الأوراق الأكاديمية والكتب المدرسية والصحف، وهو متوافق مع لغات متعددة، مما يوفر دعمًا قويًا لرقمنة المستندات ومعالجتها آليًا. تتوفر أوراق بحثية ذات صلة. MonkeyOCR: تحليل المستندات باستخدام نموذج الثلاثية "البنية-التعرف-العلاقة" .
المميزات الرئيسية:
- تحليل المستندات وهيكلتها: تحويل المحتوى غير المنظم (بما في ذلك النصوص والجداول والصيغ والصور وما إلى ذلك) في مستندات بتنسيقات مختلفة (مثل PDF والصور وما إلى ذلك) إلى معلومات منظمة وقابلة للقراءة آليًا.
- دعم متعدد اللغات: يدعم لغات متعددة، بما في ذلك الصينية والإنجليزية.
- التعامل بكفاءة مع المستندات المعقدة: يعمل بشكل جيد عند معالجة المستندات المعقدة (مثل تلك التي تحتوي على صيغ وجداول وتخطيطات متعددة الأعمدة وما إلى ذلك).
- معالجة سريعة للمستندات متعددة الصفحات: معالجة المستندات متعددة الصفحات بكفاءة بسرعة معالجة تبلغ 0.84 صفحة في الثانية، وهي أفضل بكثير من الأدوات الأخرى (مثل MinerU 0.65 صفحة في الثانية وQwen2.5-VL-7B 0.12 صفحة في الثانية).
- النشر والتوسع المرن: يدعم النشر الفعال على وحدة معالجة رسومية واحدة من نوع NVIDIA 3090 لتلبية احتياجات مختلف المقاييس.
المبدأ الفني:
- نموذج ثلاثي البنية-التعرف-العلاقة (SRR): كاشف تخطيط مستند قائم على YOLO، يحدد موقع وفئة العناصر الرئيسية في المستند (مثل كتل النصوص، والجداول، والصيغ، والصور، إلخ). يتم التعرف على المحتوى على كل منطقة مُكتشَفة، ويتم التعرف الشامل باستخدام نموذج متعدد الأشكال كبير (LMM) لضمان دقة عالية. بناءً على آلية تنبؤ بترتيب القراءة على مستوى الكتلة، تُحدَّد العلاقة المنطقية بين العناصر المُكتشَفة لإعادة بناء البنية الدلالية للمستند.
- مجموعة بيانات MonkeyDoc: تُعد MonkeyDoc أشمل مجموعة بيانات لتحليل المستندات حتى الآن، حيث تحتوي على 3.9 مليون نسخة، تغطي أكثر من عشرة أنواع من المستندات باللغتين الصينية والإنجليزية. بُنيت مجموعة البيانات هذه بناءً على خط أنابيب متعدد المراحل، يجمع بين الشرح اليدوي الدقيق، والتوليف البرمجي، والشرح التلقائي القائم على النموذج. تُستخدم لتدريب نماذج MonkeyOCR وتقييمها، مما يضمن قدرات تعميم قوية في سيناريوهات المستندات المتنوعة والمعقدة.
- تحسين النموذج ونشره: يُستخدم مُحسِّن AdamW وجدولة معدل تعلم جيب التمام مع مجموعات بيانات واسعة النطاق للتدريب، وذلك لضمان التوازن بين دقة النموذج وكفاءته. بالاعتماد على أداة LMDeplov، يمكن لـ MonkeyOCR العمل بكفاءة على وحدة معالجة رسومات NVIDIA 3090 واحدة، مما يدعم الاستدلال السريع والنشر واسع النطاق.
يستخدم هذا البرنامج التعليمي بطاقة رسوميات RTX 5090 واحدة كمورد حوسبة.
2. عرض التأثير
مثال على مستند الصيغة

مثال على مستند الجدول

مثال على الصحيفة

مثال على التقرير المالي


3. خطوات التشغيل
1. ابدأ تشغيل الحاوية
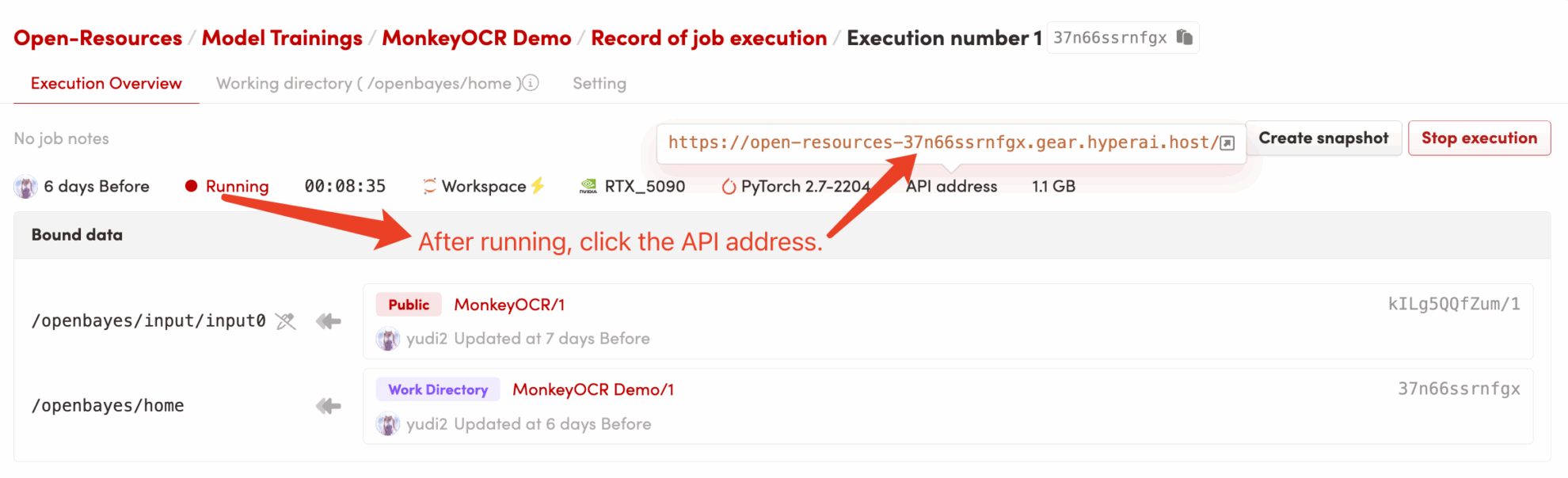
2. خطوات الاستخدام
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 2-3 دقائق وتحديث الصفحة.

معلومات الاستشهاد
معلومات الاستشهاد لهذا المشروع هي كما يلي:
@misc{li2025monkeyocrdocumentparsingstructurerecognitionrelation,
title={MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm},
author={Zhang Li and Yuliang Liu and Qiang Liu and Zhiyin Ma and Ziyang Zhang and Shuo Zhang and Zidun Guo and Jiarui Zhang and Xinyu Wang and Xiang Bai},
year={2025},
eprint={2506.05218},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05218},
}
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.