Command Palette
Search for a command to run...
OpenAudio-s1-mini: أداة عالية الكفاءة لتوليد تحويل النص إلى كلام
التاريخ
الترخيص
Apache 2.0
GitHub
1. مقدمة البرنامج التعليمي

يستخدم هذا البرنامج التعليمي الموارد لبطاقة RTX 4090 واحدة.
2. أمثلة المشاريع
تحويل النص إلى كلام
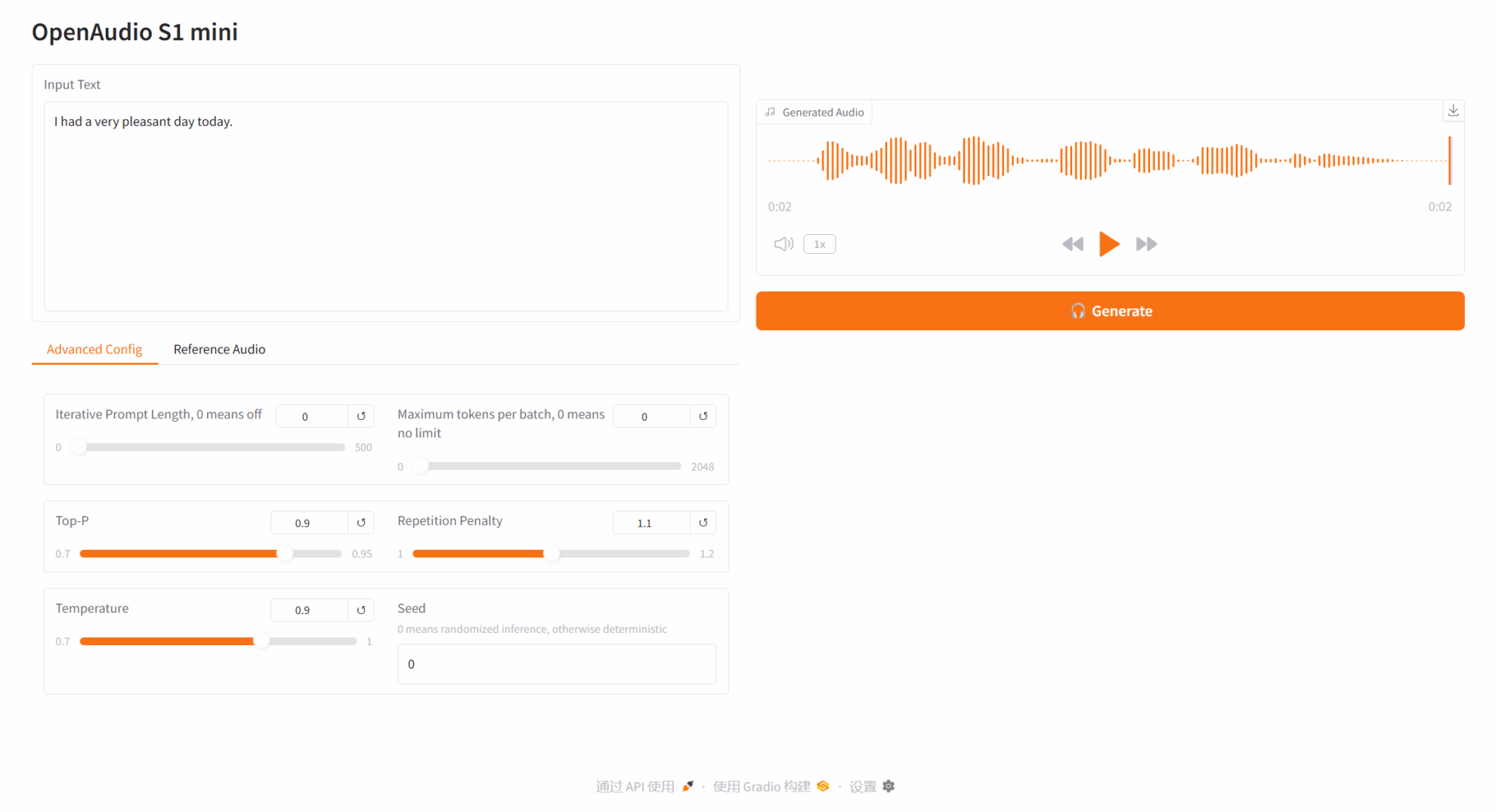

3. خطوات التشغيل
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
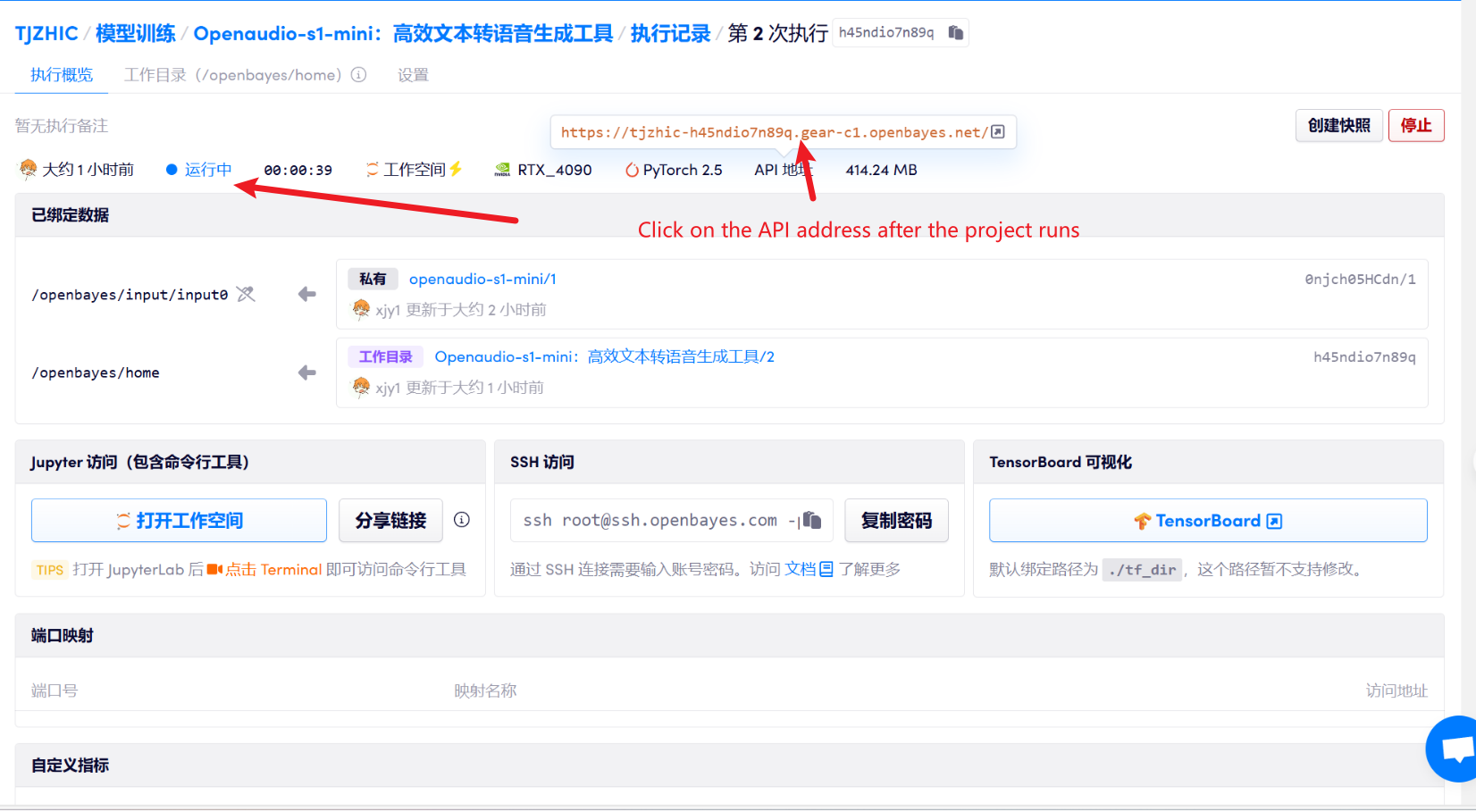
2. بمجرد دخولك إلى صفحة الويب، يمكنك استخدام النموذج
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 1-2 دقيقة وتحديث الصفحة. عند استخدام متصفح Safari، قد لا يتم تشغيل الصوت مباشرة ويجب تنزيله قبل التشغيل.
كيفية الاستخدام
2.1 تحويل النص إلى صوت
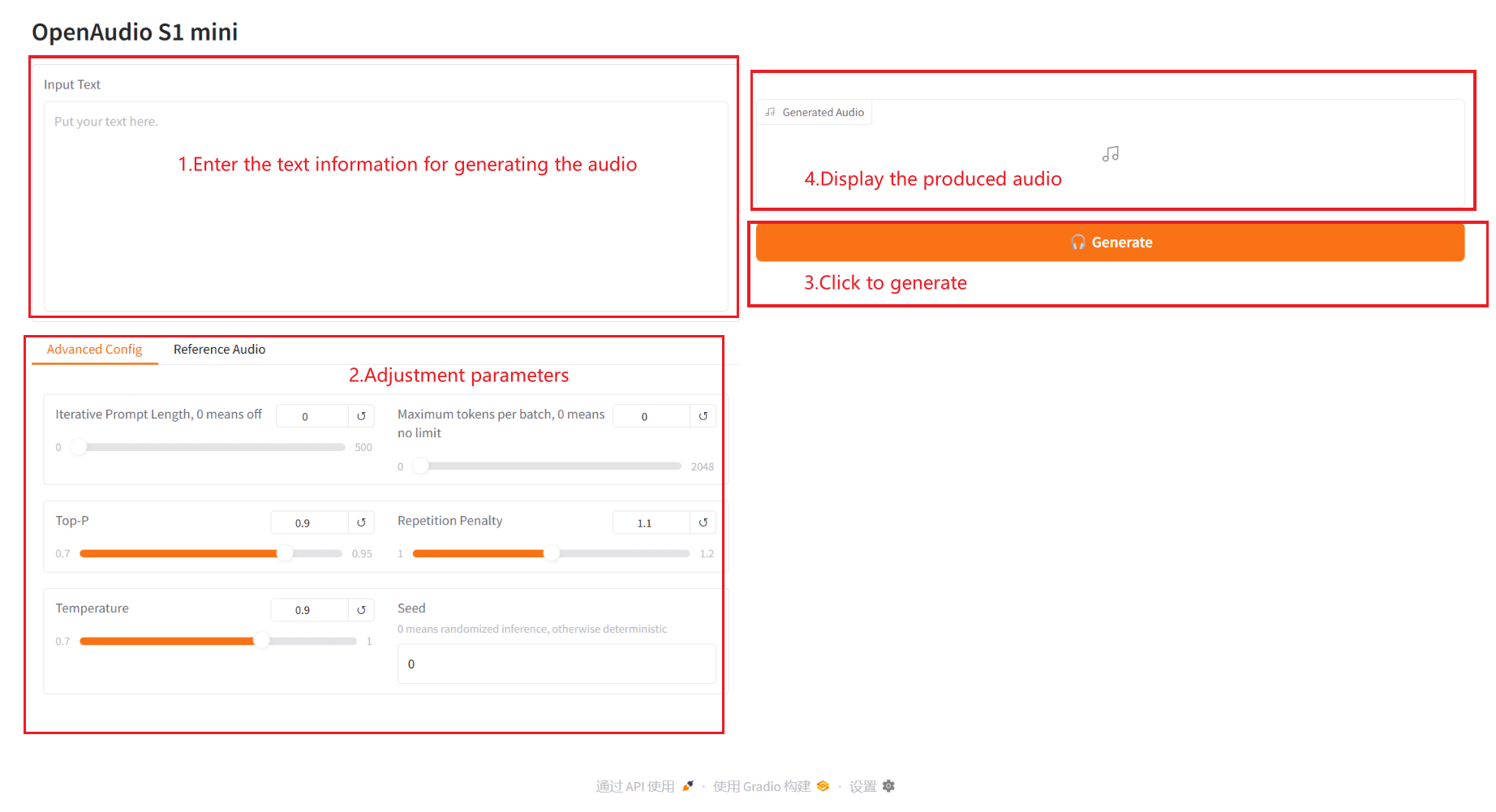
وصف المعلمة:
- التكوين المتقدم:
- طول المطالبة التكرارية: طول المطالبة التكرارية. 0 يعني إيقاف التشغيل. القيمة غير الصفرية تتحكم في طول نص المطالبة المستخدم في كل مرة عند توليد الكلام تكراريًا.
- الحد الأقصى لعدد الرموز لكل دفعة: الحد الأقصى لعدد الرموز لكل دفعة. ٠ يعني غير محدود. القيمة غير الصفرية تحد من الحد الأقصى لعدد الرموز المعالجة لكل دفعة.
- أعلى – P: احتمالية أخذ العينات الأساسية، والتي تتحكم في تنوع ويقين النص الناتج.
- عقوبة التكرار: مُعامل عقوبة التكرار، يُستخدم للتحكم في تكرار المحتوى في النص المُولّد. كلما زادت القيمة، زاد تجنب التكرار.
- درجة الحرارة: معامل درجة الحرارة، الذي يضبط عشوائية النص المُولَّد. كلما كبرت القيمة، زادت عشوائيته.
- البذرة: بذرة عشوائية، تستخدم لتوليد أرقام عشوائية ثابتة لضمان الحصول على نتائج قابلة للتكرار.
- مرجع صوتي:
- استخدام ذاكرة التخزين المؤقت: حدد ما إذا كنت تريد استخدام ذاكرة التخزين المؤقت.
- مرجع صوتي: قم بتحميل ملف صوتي (ملف wav) لاستخدامه كمرجع لمحتوى الصوت.
- نص مرجعي: أدخل محتوى النص للصوت الذي تم تحميله.
4. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓

معلومات الاستشهاد
معلومات الاستشهاد لهذا المشروع هي كما يلي:
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.