يستخدم هذا البرنامج التعليمي بطاقة A6000 واحدة كمورد. في الوقت الحالي، يدعم التفاعل بالذكاء الاصطناعي اللغتين الصينية والإنجليزية فقط.
2. أمثلة المشاريع
3. خطوات التشغيل
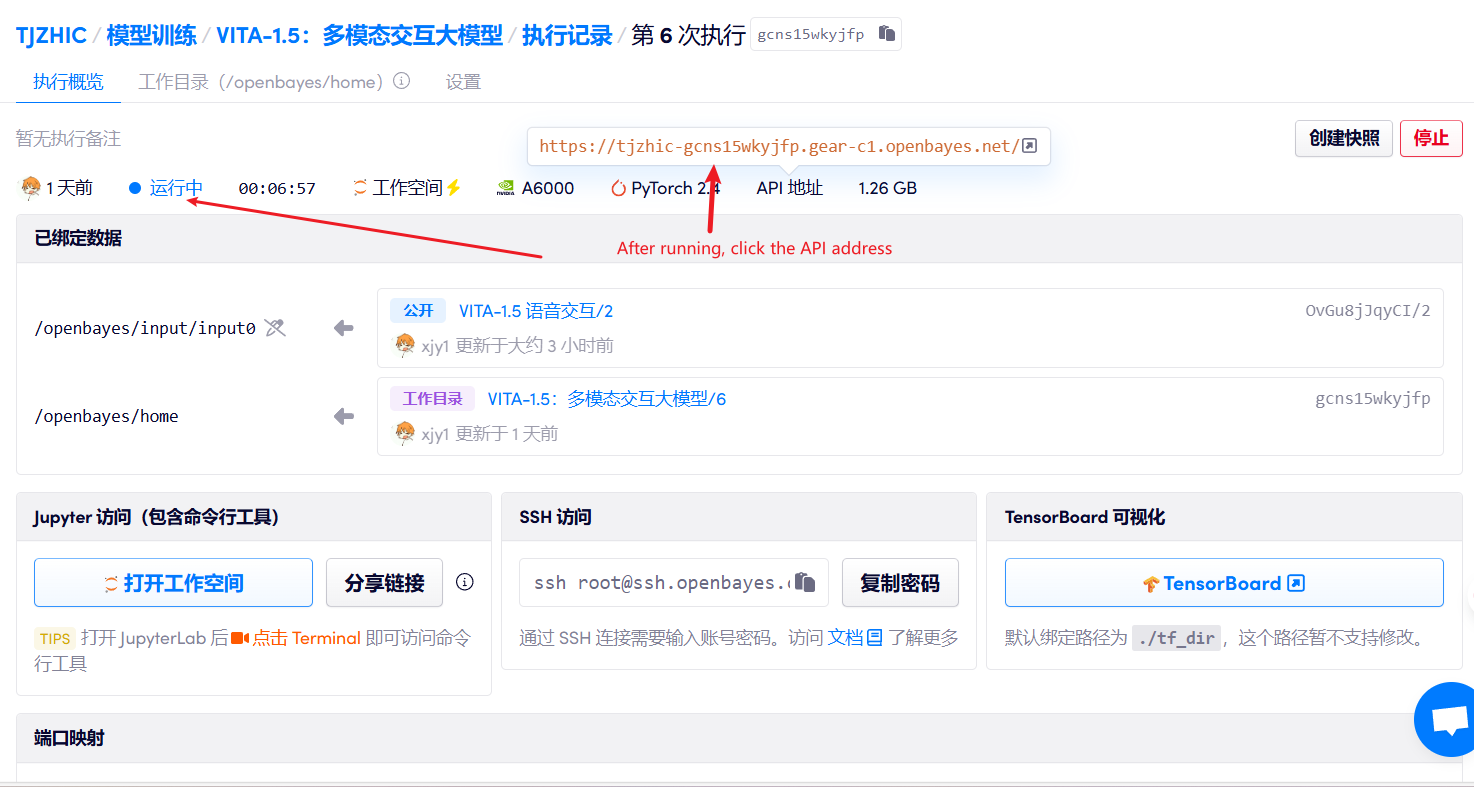
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 1-2 دقيقة وتحديث الصفحة.
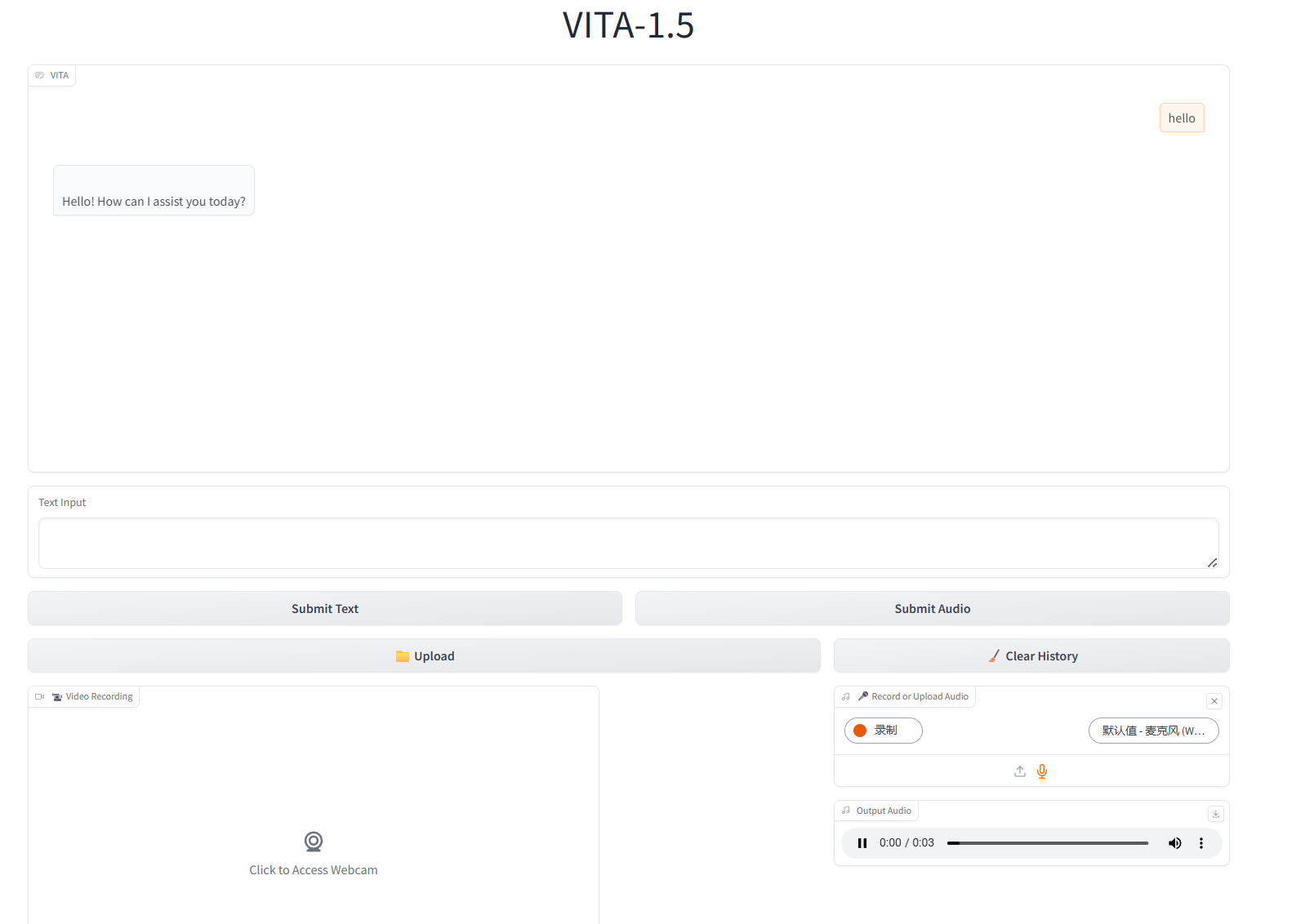
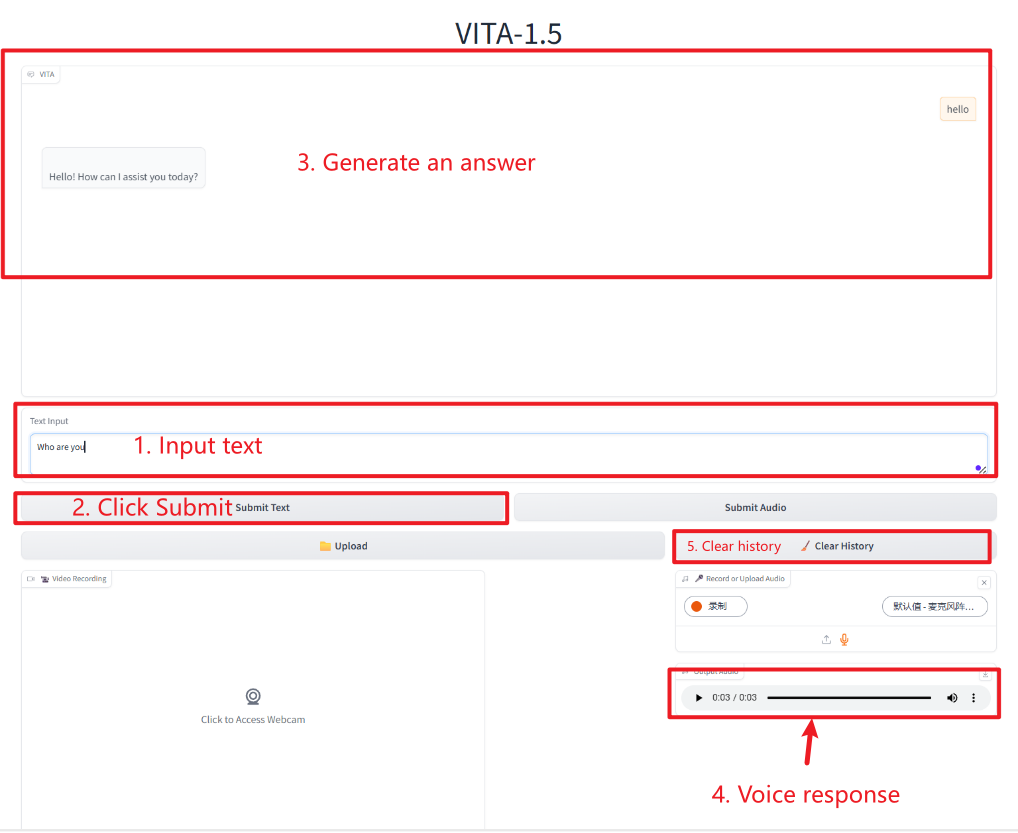
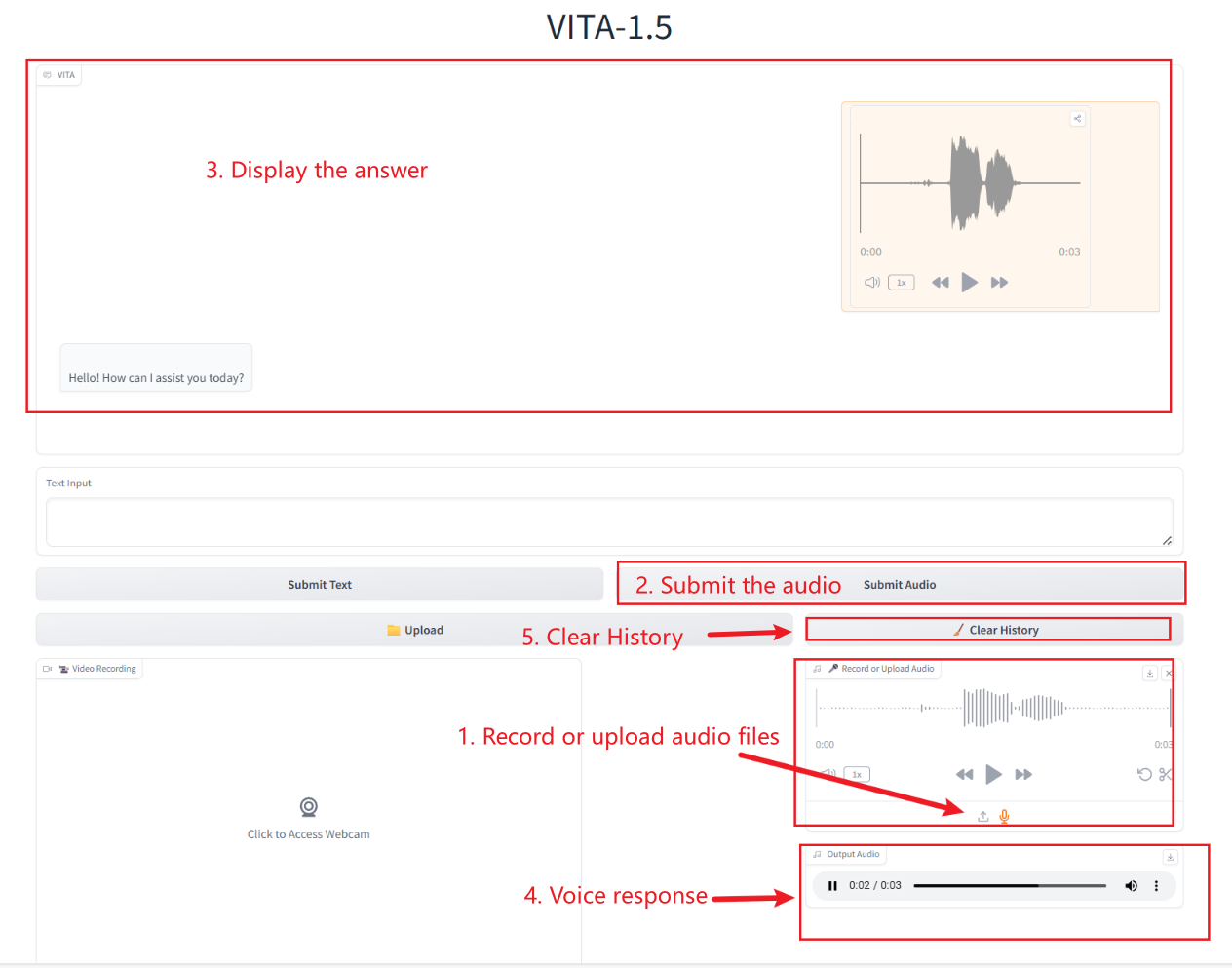
2. بعد الدخول إلى صفحة الويب، يمكنك بدء محادثة مع النموذج
عند استخدام متصفح Safari، قد لا يتم تشغيل الصوت مباشرة ويجب تنزيله قبل التشغيل.
كيفية الاستخدام
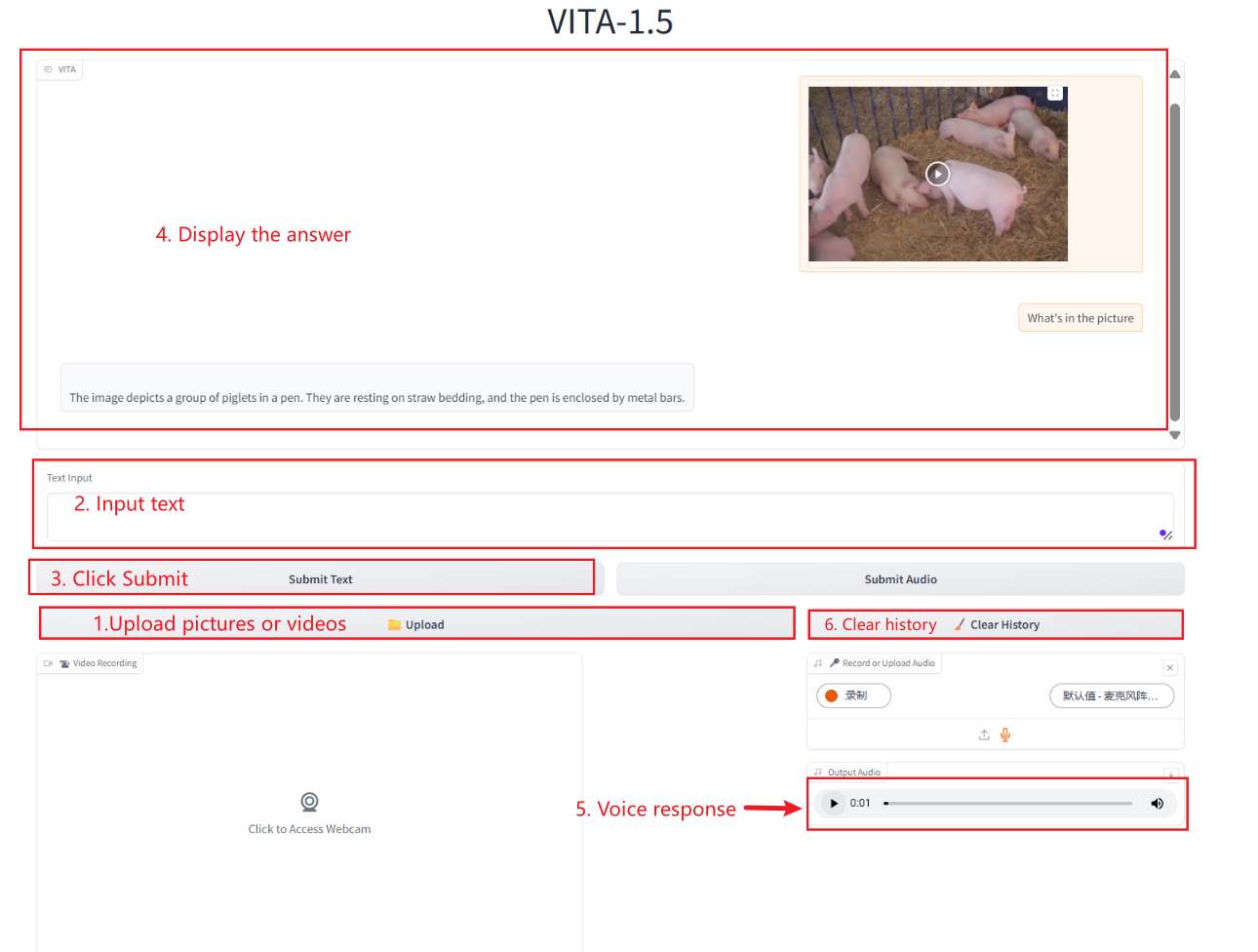
يحتوي هذا الكتاب المدرسي على طرق متعددة للتفاعل مع الذكاء الاصطناعي: النص والصوت والفيديو والصور.
التفاعل النصي
التفاعل الصوتي
التفاعل بين الصور والفيديو
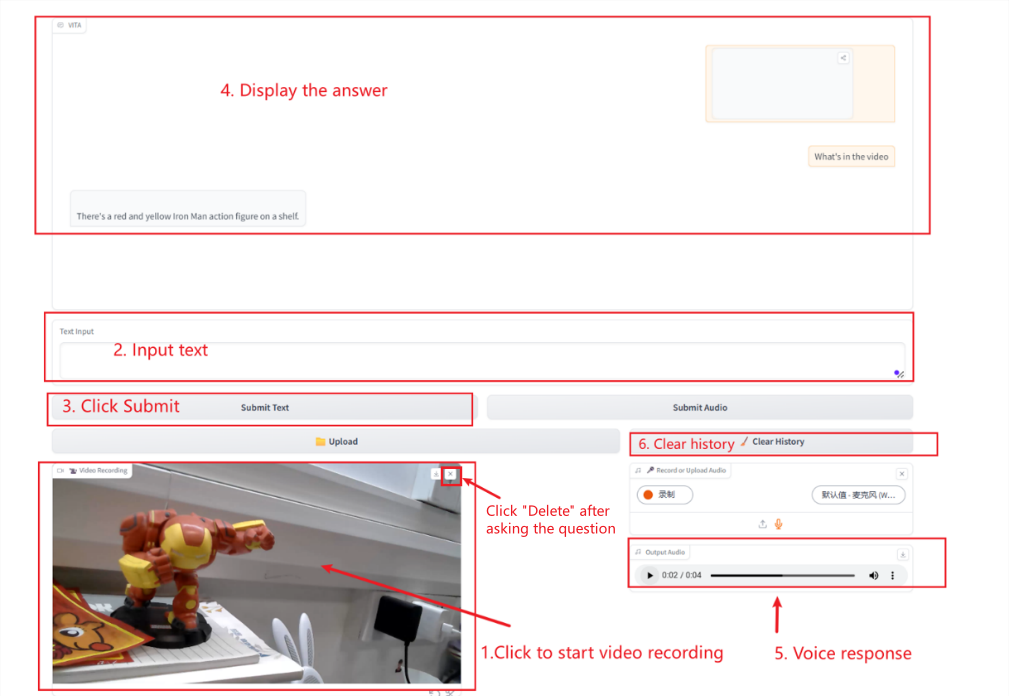
تفاعل الفيديو
ملحوظة:
عند استخدام الكاميرا لتسجيل فيديو، يجب حذف الفيديو فورًا بعد الانتهاء من السؤال.
4. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓
معلومات الاستشهاد
معلومات الاستشهاد لهذا المشروع هي كما يلي:
@article{fu2025vita,
title={VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction},
author={Fu, Chaoyou and Lin, Haojia and Wang, Xiong and Zhang, Yi-Fan and Shen, Yunhang and Liu, Xiaoyu and Li, Yangze and Long, Zuwei and Gao, Heting and Li, Ke and others},
journal={arXiv preprint arXiv:2501.01957},
year={2025}
}
@article{fu2024vita,
title={Vita: Towards open-source interactive omni multimodal llm},
author={Fu, Chaoyou and Lin, Haojia and Long, Zuwei and Shen, Yunhang and Zhao, Meng and Zhang, Yifan and Dong, Shaoqi and Wang, Xiong and Yin, Di and Ma, Long and others},
journal={arXiv preprint arXiv:2408.05211},
year={2024}
}
تم المساهمة في هذا الدفتر من قبل مستخدمي المجتمع وهو مخصص لأغراض تعليمية وإعلامية فقط. إذا كان أي محتوى ينطوي على انتهاك لحقوق النشر، يرجى الاتصال بنا على [email protected] للمراجعة والإزالة الفورية.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.
يستخدم هذا البرنامج التعليمي بطاقة A6000 واحدة كمورد. في الوقت الحالي، يدعم التفاعل بالذكاء الاصطناعي اللغتين الصينية والإنجليزية فقط.
2. أمثلة المشاريع
3. خطوات التشغيل
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 1-2 دقيقة وتحديث الصفحة.
2. بعد الدخول إلى صفحة الويب، يمكنك بدء محادثة مع النموذج
عند استخدام متصفح Safari، قد لا يتم تشغيل الصوت مباشرة ويجب تنزيله قبل التشغيل.
كيفية الاستخدام
يحتوي هذا الكتاب المدرسي على طرق متعددة للتفاعل مع الذكاء الاصطناعي: النص والصوت والفيديو والصور.
التفاعل النصي
التفاعل الصوتي
التفاعل بين الصور والفيديو
تفاعل الفيديو
ملحوظة:
عند استخدام الكاميرا لتسجيل فيديو، يجب حذف الفيديو فورًا بعد الانتهاء من السؤال.
4. المناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓
معلومات الاستشهاد
معلومات الاستشهاد لهذا المشروع هي كما يلي:
@article{fu2025vita,
title={VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction},
author={Fu, Chaoyou and Lin, Haojia and Wang, Xiong and Zhang, Yi-Fan and Shen, Yunhang and Liu, Xiaoyu and Li, Yangze and Long, Zuwei and Gao, Heting and Li, Ke and others},
journal={arXiv preprint arXiv:2501.01957},
year={2025}
}
@article{fu2024vita,
title={Vita: Towards open-source interactive omni multimodal llm},
author={Fu, Chaoyou and Lin, Haojia and Long, Zuwei and Shen, Yunhang and Zhao, Meng and Zhang, Yifan and Dong, Shaoqi and Wang, Xiong and Yin, Di and Ma, Long and others},
journal={arXiv preprint arXiv:2408.05211},
year={2024}
}
تم المساهمة في هذا الدفتر من قبل مستخدمي المجتمع وهو مخصص لأغراض تعليمية وإعلامية فقط. إذا كان أي محتوى ينطوي على انتهاك لحقوق النشر، يرجى الاتصال بنا على [email protected] للمراجعة والإزالة الفورية.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.