يستخدم هذا البرنامج التعليمي الموارد لبطاقة RTX 4090 واحدة.
👉 يقدم هذا المشروع نموذجًا لـ:
MegaTTS 3: نظام تحويل النص إلى كلام (TTS) مع خوارزمية "المحول المنتشر الكامن" الموجهة المتراصة بشكل متناثر والتي تحقق جودة كلام تحويل النص إلى كلام (TTS) متطورة للغاية وتدعم التحكم المرن للغاية في قوة اللهجة. يمكن استنساخ جرس الإدخال واستخدامه لإنشاء محتوى صوتي محدد وفقًا للمتطلبات.
2. خطوات التشغيل
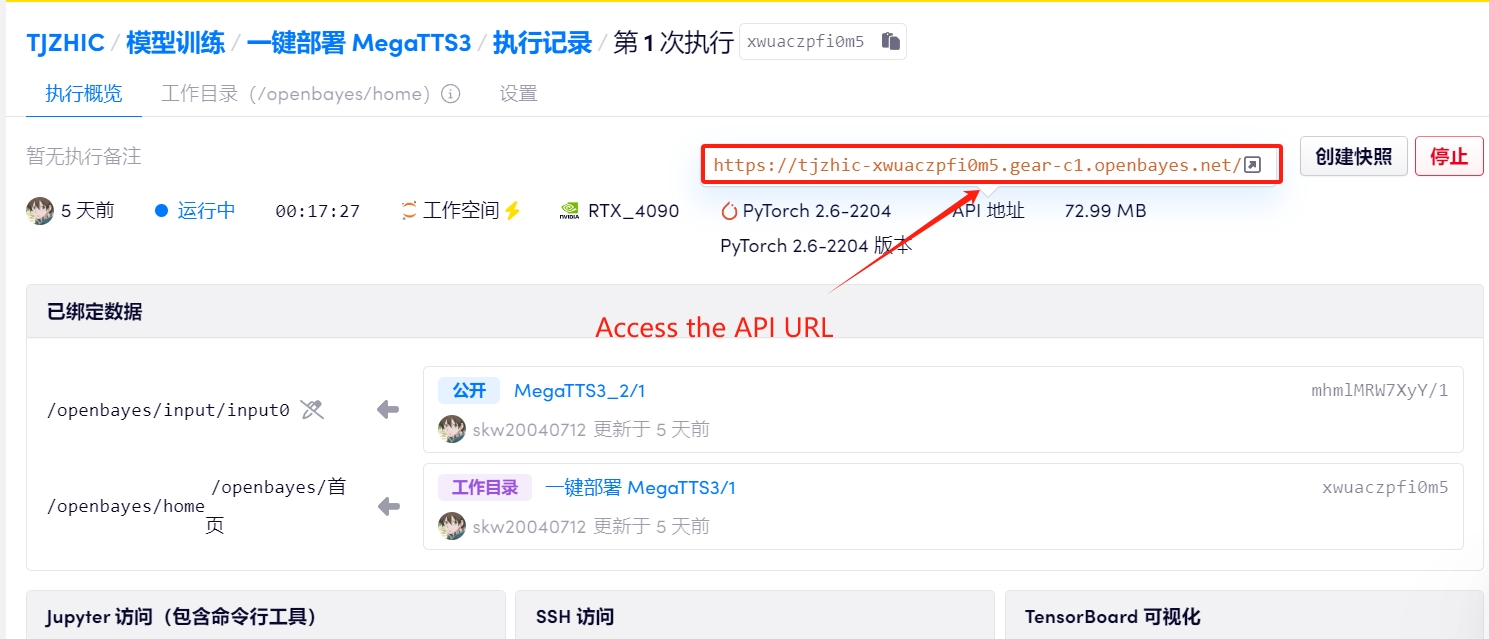
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 1-2 دقيقة وتحديث الصفحة.
2. بمجرد دخولك إلى صفحة الويب، يمكنك استخدام MegaTTS 3
كيفية الاستخدام
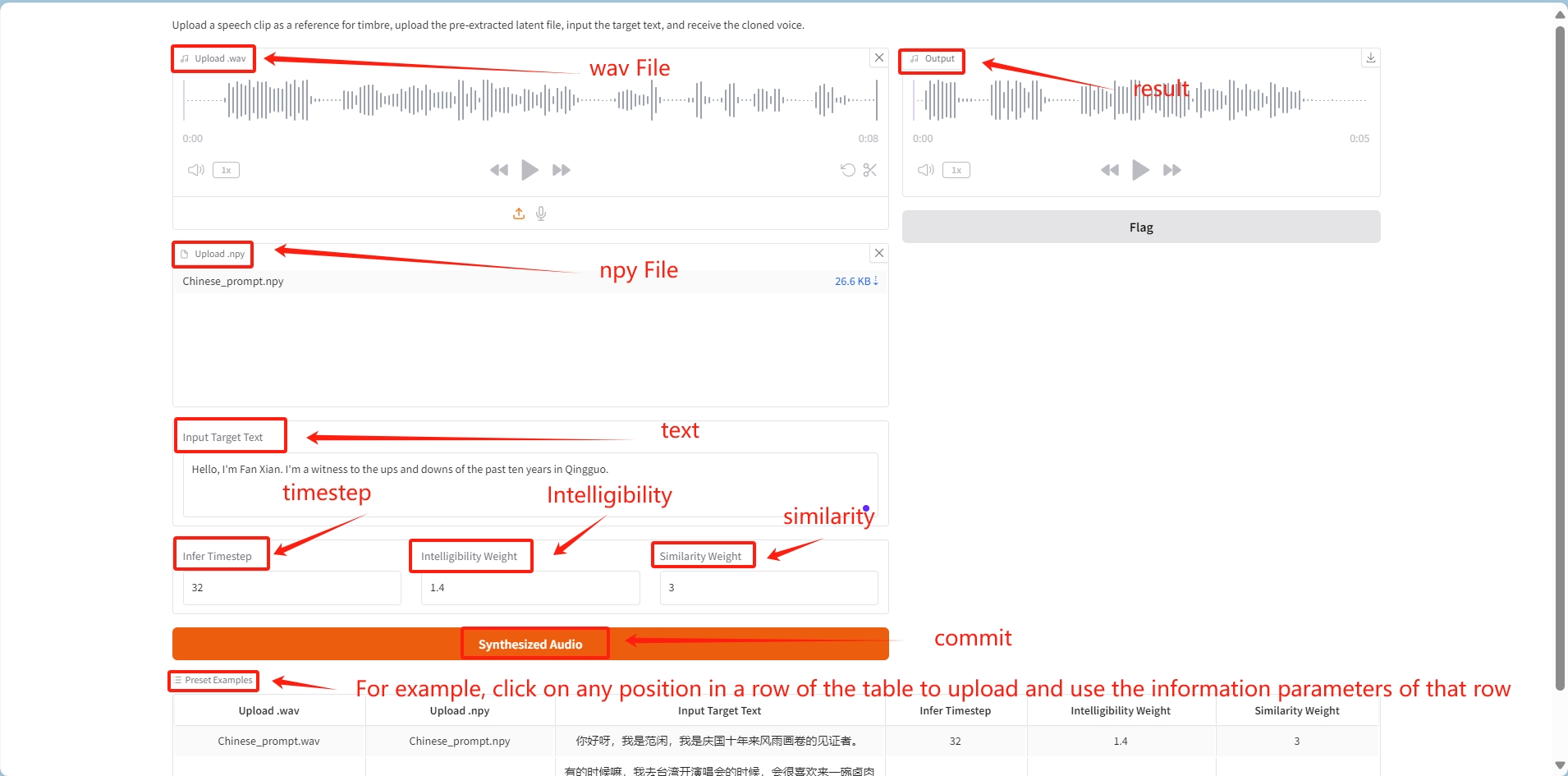
① قم بتحميل ملف الصوت wav وملف npy المولد المقابل بشكل منفصل؛
② أدخل النص المحدد في input_text؛
③ بعد الإرسال، سيتم استنساخ الجرس الموجود في ملف الصوت لتوليد الصوت المقابل للنص الموجود في input_text.
❗️وصف المعلمة:
استنتج الخطوة الزمنية: يؤثر على خطوة الوقت التي يقوم فيها النموذج بإنشاء الأصوات، ويتحكم عادةً في عدد خطوات الوقت في عملية التوليد. قد يؤدي تقليل الخطوة الزمنية إلى جعل الصوت أكثر سلاسة لأن النموذج يحتوي على خطوات زمنية أكثر لتحسين ميزات الصوت.
وزن الوضوح: ضبط وضوح الصوت ووضوحه. يجعل الوزن الأعلى الصوت أكثر وضوحًا ويكون مناسبًا للمشاهد التي تحتاج إلى نقل المعلومات فيها بدقة، ولكن قد يضحي ببعض الطبيعية.
وزن التشابه: يتحكم في مدى تشابه الصوت الناتج مع الصوت الأصلي. يجعل الوزن الأعلى الصوت أقرب إلى الصوت الأصلي وهو مناسب للسيناريوهات التي يتعين فيها إعادة إنتاج الصوت المستهدف بأمانة.
احصل على ملف العينة
اذهب إلى الموقع https://drive.google.com/drive/folders/1QhcHWcy20JfqWjgqZX1YM3I6i9u4oNlr، هناك ثلاثة مجلدات فرعية (librispeech_testclean_40، official_test_case، user_batch_1-3) تحتوي على جميع الألوان الصوتية المتوفرة حاليًا. بعد الدخول إلى المجلد، استمع إلى ملف wav وملف npy وقم بتنزيلهما.
التبادل والمناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓
معلومات الاستشهاد
شكرًا لمستخدم Github كجاسدك لإنتاج هذا البرنامج التعليمي، معلومات مرجعية للمشروع هي كما يلي:
@article{jiang2025sparse,
title={Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis},
author={Jiang, Ziyue and Ren, Yi and Li, Ruiqi and Ji, Shengpeng and Ye, Zhenhui and Zhang, Chen and Jionghao, Bai and Yang, Xiaoda and Zuo, Jialong and Zhang, Yu and others},
journal={arXiv preprint arXiv:2502.18924},
year={2025}
}
@article{ji2024wavtokenizer,
title={Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling},
author={Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and others},
journal={arXiv preprint arXiv:2408.16532},
year={2024}
}
تم المساهمة في هذا الدفتر من قبل مستخدمي المجتمع وهو مخصص لأغراض تعليمية وإعلامية فقط. إذا كان أي محتوى ينطوي على انتهاك لحقوق النشر، يرجى الاتصال بنا على [email protected] للمراجعة والإزالة الفورية.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.
يستخدم هذا البرنامج التعليمي الموارد لبطاقة RTX 4090 واحدة.
👉 يقدم هذا المشروع نموذجًا لـ:
MegaTTS 3: نظام تحويل النص إلى كلام (TTS) مع خوارزمية "المحول المنتشر الكامن" الموجهة المتراصة بشكل متناثر والتي تحقق جودة كلام تحويل النص إلى كلام (TTS) متطورة للغاية وتدعم التحكم المرن للغاية في قوة اللهجة. يمكن استنساخ جرس الإدخال واستخدامه لإنشاء محتوى صوتي محدد وفقًا للمتطلبات.
2. خطوات التشغيل
1. بعد بدء تشغيل الحاوية، انقر فوق عنوان API للدخول إلى واجهة الويب
إذا تم عرض "بوابة سيئة"، فهذا يعني أن النموذج قيد التهيئة. نظرًا لأن النموذج كبير الحجم، يرجى الانتظار لمدة 1-2 دقيقة وتحديث الصفحة.
2. بمجرد دخولك إلى صفحة الويب، يمكنك استخدام MegaTTS 3
كيفية الاستخدام
① قم بتحميل ملف الصوت wav وملف npy المولد المقابل بشكل منفصل؛
② أدخل النص المحدد في input_text؛
③ بعد الإرسال، سيتم استنساخ الجرس الموجود في ملف الصوت لتوليد الصوت المقابل للنص الموجود في input_text.
❗️وصف المعلمة:
استنتج الخطوة الزمنية: يؤثر على خطوة الوقت التي يقوم فيها النموذج بإنشاء الأصوات، ويتحكم عادةً في عدد خطوات الوقت في عملية التوليد. قد يؤدي تقليل الخطوة الزمنية إلى جعل الصوت أكثر سلاسة لأن النموذج يحتوي على خطوات زمنية أكثر لتحسين ميزات الصوت.
وزن الوضوح: ضبط وضوح الصوت ووضوحه. يجعل الوزن الأعلى الصوت أكثر وضوحًا ويكون مناسبًا للمشاهد التي تحتاج إلى نقل المعلومات فيها بدقة، ولكن قد يضحي ببعض الطبيعية.
وزن التشابه: يتحكم في مدى تشابه الصوت الناتج مع الصوت الأصلي. يجعل الوزن الأعلى الصوت أقرب إلى الصوت الأصلي وهو مناسب للسيناريوهات التي يتعين فيها إعادة إنتاج الصوت المستهدف بأمانة.
احصل على ملف العينة
اذهب إلى الموقع https://drive.google.com/drive/folders/1QhcHWcy20JfqWjgqZX1YM3I6i9u4oNlr، هناك ثلاثة مجلدات فرعية (librispeech_testclean_40، official_test_case، user_batch_1-3) تحتوي على جميع الألوان الصوتية المتوفرة حاليًا. بعد الدخول إلى المجلد، استمع إلى ملف wav وملف npy وقم بتنزيلهما.
التبادل والمناقشة
🖌️ إذا رأيت مشروعًا عالي الجودة، فيرجى ترك رسالة في الخلفية للتوصية به! بالإضافة إلى ذلك، قمنا أيضًا بتأسيس مجموعة لتبادل الدروس التعليمية. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة وإضافة [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق↓
معلومات الاستشهاد
شكرًا لمستخدم Github كجاسدك لإنتاج هذا البرنامج التعليمي، معلومات مرجعية للمشروع هي كما يلي:
@article{jiang2025sparse,
title={Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis},
author={Jiang, Ziyue and Ren, Yi and Li, Ruiqi and Ji, Shengpeng and Ye, Zhenhui and Zhang, Chen and Jionghao, Bai and Yang, Xiaoda and Zuo, Jialong and Zhang, Yu and others},
journal={arXiv preprint arXiv:2502.18924},
year={2025}
}
@article{ji2024wavtokenizer,
title={Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling},
author={Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and others},
journal={arXiv preprint arXiv:2408.16532},
year={2024}
}
تم المساهمة في هذا الدفتر من قبل مستخدمي المجتمع وهو مخصص لأغراض تعليمية وإعلامية فقط. إذا كان أي محتوى ينطوي على انتهاك لحقوق النشر، يرجى الاتصال بنا على [email protected] للمراجعة والإزالة الفورية.
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.